Apache Spark and Databricks 101 pt. II - Some DataFrames

Hugo Estrada S.
Posted on June 4, 2020


One of the core API's of Apache Spark is the DataFrame.
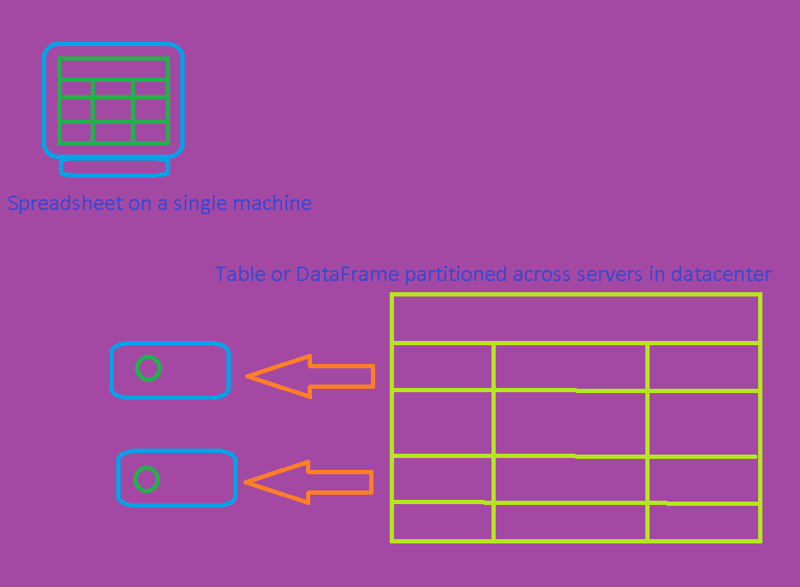
It represents a table of data with rows and columns.
The list of columns and the respective datatypes are what's called the schema.
Like an Excel spreadsheet with named columns.
DataFrames are powerful and can be partitioned across thousands of computers at the same time.
They make parallel processing of big data possible:
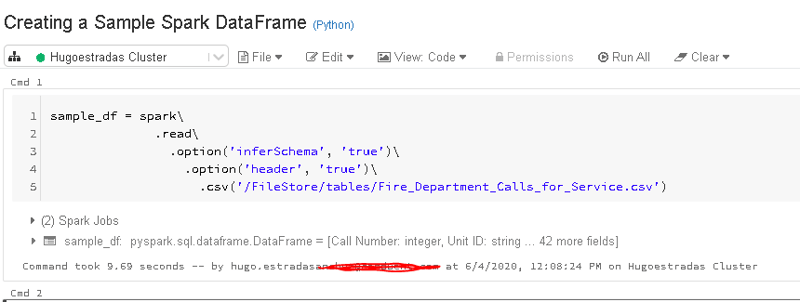
1 Creating a Sample Spark DataFrame:
The 'inferSchema' option means Spark will automatically detect the schema for us.
2 Take a Glimpse into the DataFrame:
With the 'display()' function we can see our DataFrame in a nice table format:
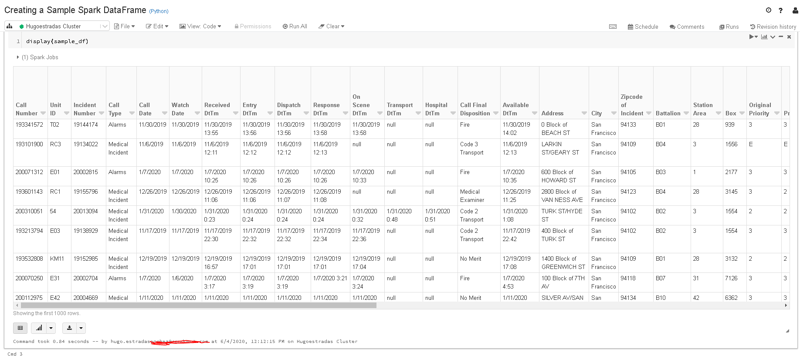
If just so happens that you only want to take a look to the first x rows use the '.take(x)' function:

Remember, this is Spark and not Python.
3 Final Thoughts and Conclusions:
Spark DataFrames are completely separate from Pandas DataFrames. That's something for another lecture, and I will show you how to convert one into the other and the differences and benefits of each.
Posted on June 4, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
