Apache Spark and Databricks 101 pt. I - The Big Picture

Hugo Estrada S.
Posted on June 1, 2020


If you're interested in becoming a Data Scientist, Data Engineer, Data Analyst (so many Data titles) or whatever, chances are you will work with Apache Spark and/or Databricks.
What is Apache Spark <?>
Is an open-source framework for distributed data processing. Anyone who uses the Spark ecosystem in an application can focus on his/her domain-specific data processing business case, while trusting that Spark will handle the messy details of parallel computing. Spark is deployed as a cluster consisting of a master server and many worker servers. The master server accepts incoming jobs and breaks them down into smaller tasks that can be handled by workers. Spark isn't a data storage solution, neither a Hadoop replacement.What is Databricks <?>
Databricks is an Apache Spark-based analytics platform optimized either AWS or Azure platforms. Designed with the founders of Apache Spark, Databricks is integrated in these cloud providers to provide one-click setup, streamlined workflows, and an interactive workspace that enables collaboration between data scientist, data engineers, and business analysts. There is also a free community edition available where you can learn the basics!Some interesting Databricks Features
Databricks lets you run code in notebooks - exactly like Jupyter would.
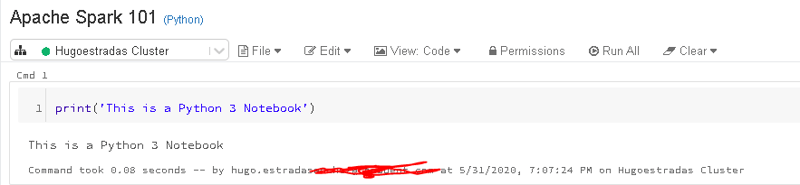
Looks just like Jupyter, doesn't it <?>
All your code runs on a cluster, though, which you can scale up depending on the workload.
Noticed how this is a "Python Notebook" <?>
In Databricks, you can seamlessly switch languages- EVEN IN THE SAME NOTEBOOK:
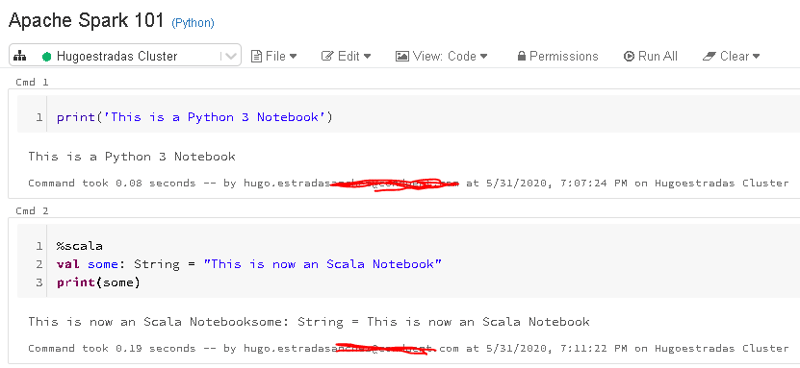
This is possible, with the "%" command.
There are a lot of Data Structures in the Apache Spark framework that you can explore using Databricks.
Tools like this are used by Data Scientist and Data Engineers alike.
Posted on June 1, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
