
Lucas Barret
Posted on February 22, 2023
Introduction
As a coffee lover and a developer, I decided to create some data manipulation using a dataset on Coffees Reviews I found online on Kaggle.
I created a Rails app and wanted to import the data from the CSV file I found into my Postgres database. Plenty of gems are available for this task, but I wanted to use SQL.
What we want to do :
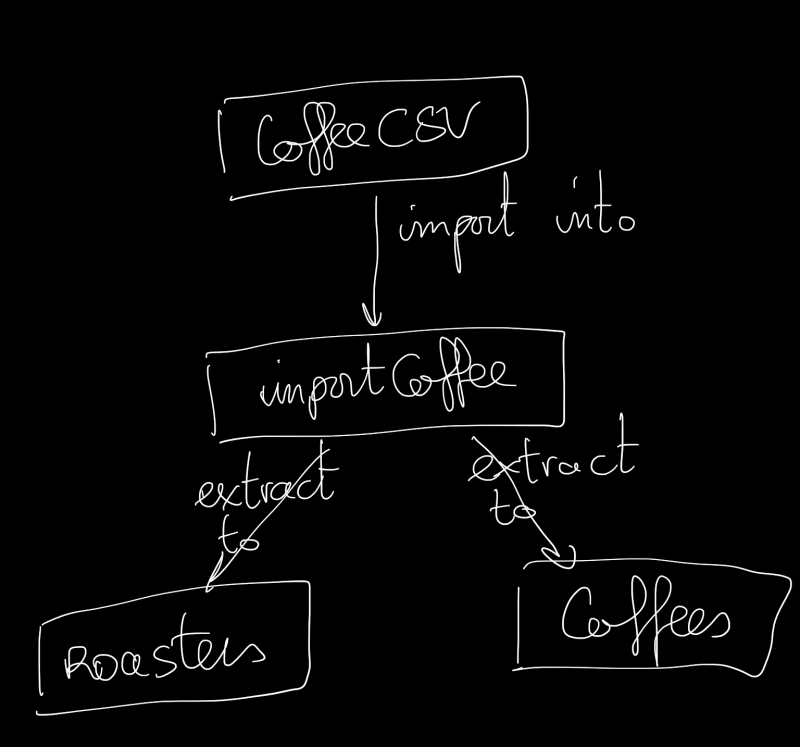
SQL is like a superhero tool with incredible power! And I want to level up my skills, so I decided to do it in SQL.
And there I go. I began learning about PL/PGSQL, ETL, and rake tasks.
PL/PGSQL
Procedural languages (PL) come in different forms for different databases. In Postgres databases, one such procedural language is PL/PGSQL. However, Postgres supports other procedural languages like PL/Ruby, PL/Python, and more.
ETL, what is it?
ETL stands for Extract, Transform, and Load. It is a process that involves extracting data from various sources (here on, transforming it into a format that can be easily analyzed and loading it into a destination system. In this article, the data sources are the CSV we found on Kaggle and our Postgres Database's destination system.
So let's get our hands dirty
Setup
First, I have created my rails project :
rails new coffee_app --database=postgres
Then add your sidekiq gem :
gem 'sidekiq'
And then run bundle in your app directory in your shell:
bundle
Sidekiq needs Redis to work, so you will need to execute it.
My personal preference is to run it in a docker container like this:
docker pull redis
docker run -p 6379:6379 --name redis-container redis
Then you can run sidekiq
bundle exec sidekiq
Now that we've got our battle gear let's dive into the coding trenches and show SQL who's boss!
Asynchronous ETL with Sidekiq
You can create a job with the rails cli easily like this:
rails g job CoffeeEtlJob
Then add the following code to your job :
class CoffeeEtlJob < ApplicationJob
queue_as :default
def perform
query_insert_into_coffee = <<-SQL
CREATE FUNCTION insertintocoffees() RETURNS TRIGGER AS $example_table_coffee$
BEGIN
INSERT INTO coffees (name,price,description,origin,created_at,updated_at) VALUES (
NEW.name,
NEW.price,
NEW.review,
NEW.origin,
NOW(),
NOW());
RETURN NEW;
END;
$example_table_coffee$ LANGUAGE plpgsql;
SQL
query_insert_into_roaster = <<-SQL
CREATE FUNCTION insertintoroasters() RETURNS TRIGGER AS $example_table_roaster$
BEGIN
INSERT INTO roasters (name,location,created_at,updated_at) VALUES (
NEW.roaster,
NEW.loc_country,
NOW(),
NOW());
RETURN NEW;
END;
$example_table_roaster$
SQL
create_triggers = <<-SQL
CREATE TRIGGER etl_coffees AFTER INSERT ON import_coffee FOR EACH ROW EXECUTE PROCEDURE insertintocoffees();
CREATE TRIGGER etl_roasters AFTER INSERT ON import_coffee FOR EACH ROW EXECUTE PROCEDURE insertintoroasters();
SQL
copy_data = <<-SQL
COPY import_coffee
FROM 'path/to/your/csv'
DELIMITER ',' CSV HEADER
SQL
ActiveRecord::Base.transaction do
ActiveRecord::Base.connection.execute(query_insert_into_coffee)
ActiveRecord::Base.connection.execute(query_insert_into_roaster)
ActiveRecord::Base.connection.execute(create_triggers)
ActiveRecord::Base.connection.execute(copy_data)
end
end
end
Break things up
The queries that create function and return a trigger insert data in the database table.
Like this one :
CREATE FUNCTION insertintocoffees() RETURNS TRIGGER AS $example_table_coffee$
BEGIN
INSERT INTO coffees (name,price,description,origin,created_at,updated_at) VALUES (
NEW.name,
NEW.price,
NEW.review,
NEW.origin,
NOW(),
NOW());
RETURN NEW;
END;
$example_table_coffee$ LANGUAGE plpgsql;
After a trigger is fired in response to an event it will insert into the database, and the values for the column are provided thanks to the NEW keyword.
But how do we execute this? Thanks to the definition of the trigger like this :
CREATE TRIGGER etl_coffees
AFTER INSERT ON import_coffee
FOR EACH ROW EXECUTE PROCEDURE insertintocoffees();
This will execute your insertintocoffees function with each row of our CSV file. Nonetheless, it will be triggered first after INSERT ON import_coffee. For the import_coffee insertion, we need this :
COPY import_coffee
FROM 'path/to/your/csv'
DELIMITER ',' CSV HEADER
This will copy the data from our csv to the import_coffee table.
Putting all together
We create functions that will copy the data in a good place and transform it if necessary.
We create a trigger to execute our function for each row of our new table after the insert.
We launch our copy which will trigger our functions when all the data are in the import_coffee table.
Rake Task
Rake is a build tool written in Ruby. It is used in Ruby on Rails projects to automate repetitive tasks like running tests, migrating databases, or deploying code to a server. It looks like the rails runner I've spoken about in this article.
Rake uses a domain-specific language (DSL) to define tasks and dependencies between tasks and provides a command-line interface for executing those tasks.
In a Rakefile (a file that defines tasks for Rake), tasks are defined using the task method.
You can generate a rake task with the rails cli.
rails g task etl populate
This will generate a task file called etl.rake in your app's lib/tasks directory. Then you can add the following line to it :
namespace :etl do
desc "Populate the database with data from the ETL."
task populate: :environment do
CoffeeEtlJob.perform
end
end
And you're good. Eventually, you run your rake task like this:
rake etl: populate
When you run the rake etl: populate command, the CoffeeEtlJob will be executed immediately. However, make sure that your Sidekiq server is running.
Remember that although creating an ETL process in Ruby using PL/PGSQL and Sidekiq is easy, there are still necessary steps before it's production-ready. (Where are the test ?🙈).
Conclusion
It is easy to run an ETL in Ruby. SQL and Ruby are mighty; it seems not a natural choice for data manipulation. The most important is that you took pleasure along the way.
I hope you have learned or used something that makes you happy. In my opinion, boring Technologies or not, Ruby, Rails, and SQL are mighty and genuinely pleasurable to use.
Keep in Touch
On Twitter : @yet_anotherDev
Posted on February 22, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



