How Should we Version GraphQL APIs?

Marc-Andre Giroux
Posted on November 6, 2019
How do you version GraphQL APIs? The most common answer you’ll get these days is “you don’t”. If you’re like me when I first read that, you might be a little anxious about maintaining a version-less API or a bit skeptical of the approach. In fact, not only is this a common answer, but it’s listed as a feature of GraphQL itself on graphql.org

When reading graphql.org, this may look like a feature being specific to GraphQL, but in fact, evolving APIs without versioning is something that has been recommended a lot for REST and HTTP APIs already. In fact, Roy Fielding himself, famously said at a conference that the best practice for versioning REST APIs was not to do it! Let’s explore API versioning and maybe try to see which evolution approach makes most sense for GraphQL APIs.
API Versioning is Never Fun
In API Versioning Has No “Right Way”, Phil Sturgeon does a very useful tour of API versioning techniques we’ve been seeing in the wild. The conclusion Phil ends up is one I share. No versioning approach is bullet proof, and most of them are quite 💩 for clients.
Probably the most popular versioning approach out there is global URL versioning. This is the approach you see when APIs have /api/v1/user and /api/v2/user for example. While this may appear like the most simple approach to get started it comes with a lot of annoying problems. A now classic versioning article from Brandur Leach on Stripe's versioning approach explains this beautifully:
“This can work, but has the major downside of changes between versions being so big and so impactful for users that it’s almost as painful as re-integrating from scratch. It’s also not a clear win because there will be a class of users that are unwilling or unable to upgrade and get trapped on old API versions. Providers then have to make the difficult choice between retiring API versions and by extension cutting those users off, or maintaining the old versions forever at considerable cost.”
Instead, Stripe’s approach is to use smaller date-based change sets that map to server side “transforms”, hoping for smaller sets of changes, but also incurring less cost on the server side implementation. Instead of expressing these versions in the URL, a header is used to switch between these smaller versions. They reserve the right to version in the URL, but would only be used for really major changes.
The header based / dynamic approach has become a fairly popular approach to versioning, which I think provides a better experience to clients and API providers.
When using resource based HTTP APIs, another approach to evolving resources is using content negotiation. For example, the GitHub API allows clients to specify a custom media type that includes a version number. This is a pretty good way to express versioning for the representation of a resource, but not necessarily for other types of changes. The other down side is that clients aren’t forced to pass that media type, and if it goes away, are reverted back usually to the latest version, almost certainly breaking them. For GraphQL, since we aren’t dealing with different HTTP resources, this is a no go.
Versioning GraphQL is Possible
Nothing is stopping anyone from versioning a GraphQL API. The spirit of Lee Byron won’t come haunt you if that happens (Actually, I can’t promise that 👻). In fact, Shopify recently adopted a URL versioning approach to evolve their GraphQL API.
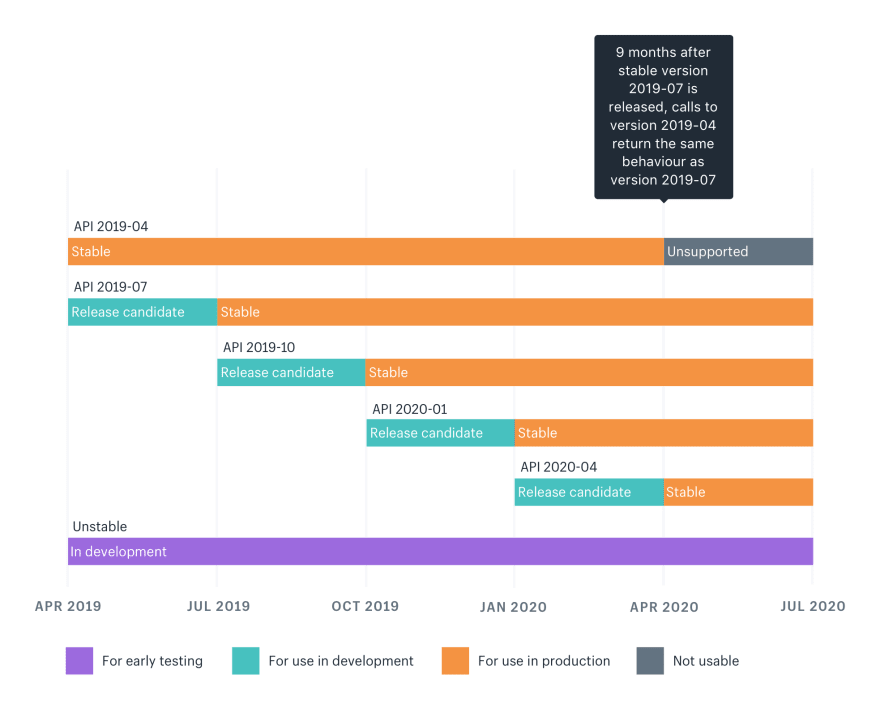
The versioning approach uses the URL for global versioning. With GraphQL, this is less annoying because it doesn’t create a full new hierarchy of resources under the new identifiers. It uses finer grained, 3 month long versions, which helps with the typical global versioning problems.
While versioning often gives a sense of security to both providers and clients, it doesn’t generally last forever. Unless an infinite amount of versions is supported, which causes unbounded complexity on the server side, clients eventually need to evolve. In that Shopify example, this happens 9 months after a stable version is released. After that 9 months, clients need to either upgrade to the next viable version, which contains a smaller set of changes, or upgrade to the newest version, which probably includes a lot more changes.
Continuous Evolution
The alternative to versioning, as mentioned at the beginning of this post is to simply not do it. The process of maintaining a single version and constantly evolving it in place rather than cutting new versions is often called Continuous Evolution. One of my favorite way to describe the philosophy comes from again, Phil Sturgeon:
“API evolution is the concept of striving to maintain the “I” in API, the request/response body, query parameters, general functionality, etc., only breaking them when you absolutely, absolutely, have to. It’s the idea that API developers bending over backwards to maintain a contract, no matter how annoying that might be, is often more financially and logistically viable than dumping the workload onto a wide array of clients.”
Commitment to Contracts
Ironically, I remember hearing that Tobi was absolutely against API versions back when I worked at Shopify. Back then I was shocked to hear that, and was really skeptical. The funny thing is now I totally understand where Tobi was coming from, and I hold similar views nowadays.
A big part of the philosophy behind continuous evolution is a strong commitment to contracts, aiming to evolve the API in a backward compatible way the absolute best we can. This may sound like an unachievable dream to some of you, but I’ve noticed a lot of API providers will settle into versioning rather than trying to find creative ways to maintain their interface.
Additive changes are almost always backward compatible, and a lot of the time breaking changes can be avoided if they are used wisely. The main downside to an additive approach to evolution is usually naming real estate and API “bloat”. The naming issue can usually be mitigated by being overly specific in naming in the first place. The bloating, especially in GraphQL, is most probably less of an issue than the cost of versioning to clients. But that’s of course a tradeoff for API providers to decide.
Unavoidable Breaking Changes
At this point you’re probably yelling at your screen thinking back to moments when you totally had to make breaking changes to your interface. And it’s true! Not all changes can be made through addition, and there will always be moments where a breaking change need to be made. In fact, here are a few good examples of unavoidable breaking changes:
- Security Changes: You realize a field has been leaking private data or that you should never expose a certain set of fields.
- Performance issues linked to the API design: A unpaginated list that can potentially return millions of records, causing timeouts and breaking clients.
- Authentication changes: An API provider deciding to deprecate “basic auth” all together, forcing API clients to move towards JWTs.
- A non-null field actually can be null at runtime: I would not wish this one on my worst enemy.
In these four example cases, there is often no way an additive change can be made to address the situation. The API must be modified, or fields be removed. With evolution, we rely on deprecation notices, a period to let clients move away from the deprecated fields, and a final sunset making the breaking change.
Versioning seems like it would solve breaking change issues but if you look at the examples we listed, none of them would be easy even if we had a great versioning strategy in place. In fact, we would need to make breaking changes in all affected versions, making use of deprecations, a period to let clients move away, before finally making the breaking change. Notice something funny? Yep, versioning requires the same amount of work (possibly more depending on amount of versions) than if we had a single continuously evolving version.
Not matter what strategy you picked, it’s how you go through that deprecation period that will determine how good your API evolution is. This is sometimes referred to as “change management”.
Change Management
As API maintainers, no matter what evolution / versioning process we decide to standardize one, one thing is for sure: we have to get good at change management. Rarely will throwing a deprecated directive on a field solve all your problems. We need more a bit more than this!
Communicate 💌
Communicate early and often. Reaching all users of the use case you are deprecating is hard. Often, a combination of all mediums you can think of works best:
- An API upcoming change log.
- Your API’s Twitter Account.
- A notice on your developers doc website.
- A blog post announcing the upcoming changes.
- A notice on the API client dashboard if you have one.
- Direct Email.
You communications should be clear about what is going away, why that’s the case, and what the new way of doing things is. Provide examples of old vs new if you can. Empathy goes a long way, and if this does not happen often serious integrators won’t hold a grudge.
Track 🔎
The best communication is often the one that is targeted and closer to individual integrators. But for that to happen you need to know in the first place who out of all integrators could be affected. For GraphQL APIs, it’s both easier and harder than with HTTP APIs. Let’s start with the good news.
As I mentioned in this article, GraphQL allows us to track our API usage in a very fine grained way, which is awesome. The bad news is that doing that requires a bit more work than simply looking at HTTP logs or tracking endpoints.
If you want a plug and play solution, Apollo’s Platform product allows you to do just that. If not you’ll have to build your own. Generally, you’ll want to parse incoming GraphQL query strings, map them to which part of the schema they use, and store the fields & arguments as well as client details (app id, email, etc) that are being used in your datastore of choice. You’ll then be able to query for things like “Which clients have queries User.name in the past 24 hours?”, which will help you extract a list of integrators to contact. Once you have contacted them, you can use the same data to see if usage is going down over time. Once it’s at an acceptable state to you, you can make the change. This is an absolutely amazing concept that serious GraphQL platforms should consider using.
Last Resort 🚨
Sometimes you’ve announced the change everywhere, reached out to individual integrators via email, and still there’s usage. There will always be a point where a tradeoff needs to be made between how perfect the transition needs to be, and evolution not being blocked.
A technique I really like to use to “wake up” integrators that haven’t seen or haven’t acted on the deprecation notice is called “API brownouts”. With brownouts, you temporally make the breaking change in the hope that a monitoring system, logs, or a human notices that something is broken for those last integrators.
Hopefully the error your API is returning includes some kind of information on how to fix it:
{
"errors": [{
"message": "Deprecated: Field `name` does not exist on type `User` anymore. Upgrade as soon as possible. See: https://my.api.com/blog/deprecation-of-name-on-user"
}]
}
Take a look at the data you’re gathering after some brownout sessions and see if the usage is dropping!
So… Should we Version?
That decision ultimately boils down to your own set of trade offs, what your clients are expecting, and what kind of expectations you want to set as an API provider. However, more and more, I’m starting to think that versioning usually ends up causing more trouble than anything, since a lot of the time, there comes a point where changes need to be made, just like in a continuous evolution approach.
GraphQL helps us do continuous evolution in a few ways that make it quite a bit easier:
- It has first-class deprecation support on fields, and most tooling already knows how to use it.
- Additive changes come with no overhead on existing and new clients.
- Usage tracking can be done down to single fields.
These three things make GraphQL a really good candidate for continuous evolution, which is why I think we see it being recommended so heavily. Another thing to keep in mind is that if you opt for a continuous evolution approach first and then decide you absolutely need versioning, that’s possible. The opposite is much harder.
It’s important to mention that I think continuous evolution can definitely be done in a bad way. It is a big responsibility and can’t be abused. That’s why additive changes must be the absolute priority before making changes.
Finally, the best way to avoid all these kinds of problems is often at the root: API design. Use a design-first approach with a focus on evolvable design from the get go. When changes have to be made, we “just” have to be very good at change management and hope for the best!
If you want to read more on what’s been said about the subject, here are another bunch of versioning articles I loved:
- https://phil.tech/api/2018/05/02/api-evolution-for-rest-http-apis/
- https://apisyouwonthate.com/blog/api-versioning-has-no-right-way
- https://www.mnot.net/blog/2011/10/25/web_api_versioning_smackdown
- https://www.mnot.net/blog/2012/12/04/api-evolution.html
Originally published at https://productionreadygraphql.com on November 6, 2019.
Posted on November 6, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
