
Victor Hazbun
Posted on March 9, 2024
Databases are the lifeblood of our applications, storing the crucial information that fuels their operation. But just like sculpting clay, modifying database tables requires careful precision and meticulous planning. A single misguided change can ripple through data integrity, functionality, and user experience.
Fear not, intrepid data architects and developers! This document serves as your guide to navigating the delicate dance of database modifications.
SQL transactions best practices
Transactions are the bulwark of relational database consistency. All or nothing, that’s the transaction motto. Transactions ensure that every command of a set is executed. If anything fails along the way, all of the commands are rolled back as if they never happened.
MySQL transactions follow ACID compliance, which stands for:
Atomic (either all operations succeed or none do)
Consistent (the data will always be in a good state and never in an inconsistent state)
Isolated (transactions don’t interfere with one another)
Durable (a committed transaction is safe, even after a server crash)
Transactions use cases
For the following examples, let’s pretend we have a wallets table with columns id, balance , updated_at and owner_id.
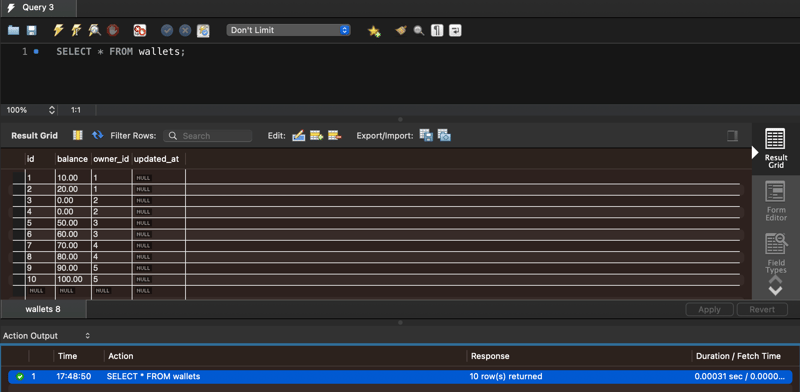
Best practice: Use transactions
We can wrap any transaction within a START TRANSACTION block. To verify atomicity, we'll kill the transaction with the ROLLBACK command.
START TRANSACTION;
UPDATE wallets SET balance = 100 WHERE owner_id = 2;
ROLLBACK;
In this example, no account will be updated thanks to the ROLLBACK command.
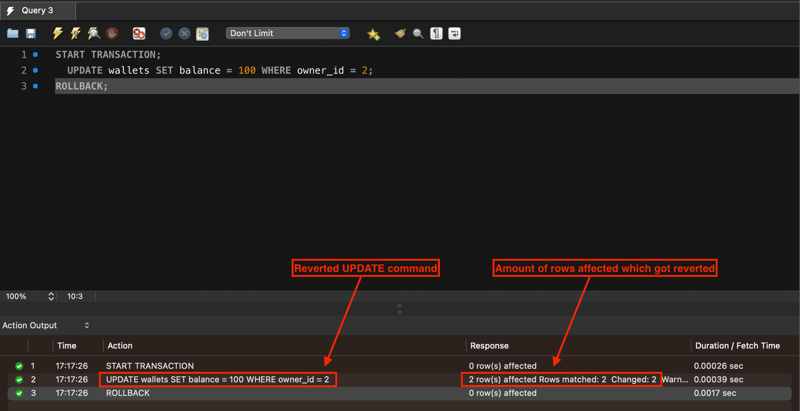
Additionally, the output will tell you how many rows the query would affect if you decide not to use ROLLBACK.
Best practice: Use savepoint
It's good practice to use the SAVEPOINT statement within a transaction to set save points. This makes it possible for you to rollback to a specific point in the transaction, rather than rolling back the entire transaction.
Here is an example of how you might use the SAVEPOINT statement within the previous example:
START TRANSACTION;
UPDATE wallets SET balance = balance + 100 WHERE owner_id = 1;
SAVEPOINT save_point_update_owner_1; -- Create a savepoint
UPDATE wallets SET balance = balance - 50 WHERE owner_id = 2;
IF (SELECT COUNT(*) FROM wallets WHERE balance < 0) > 0 THEN
ROLLBACK TO save_point_update_owner_1; -- Rollback to the savepoint
ELSE
COMMIT; -- Commit the entire transaction
END IF;
Let’s see this example step by step:
START TRANSACTION;: Begins a transaction, ensuring changes are grouped together.
First Update: Updates the balance for owner_id = 1.
SAVEPOINT save_point_update_owner_1;: Creates a savepoint named save_point_update_owner_1, marking a point to potentially revert to.
Second Update: Updates the balance for owner_id = 2.
Conditional Check: Checks if any balances have become negative.
ROLLBACK TO save_point_update_owner_1;: If negative balances exist, rolls back to the savepoint, undoing only the second update.
COMMIT;: If no negative balances exist, commits the entire transaction, including both updates.
Key points:
Flexibility: Savepoints allow selective rollbacks within a transaction, providing more control over changes.
Nesting: You can create multiple savepoints within a transaction for finer-grained control.
Rollback Scope: Rollback to a savepoint only undoes changes made after that savepoint, not the entire transaction.
Transaction Continuation: After rolling back to a savepoint, you can continue with the transaction and make further modifications.
Release: Savepoints are automatically released when a transaction is committed or rolled back entirely.
Best practice: Set timestamps for updated records
In the realm of data management, tracking changes to records is crucial for maintaining data integrity, version control, and auditing purposes. By setting timestamps for updated records, you gain valuable insights into:
When data was modified: Identify when specific changes occurred, enabling you to track data evolution and pinpoint potential errors or inconsistencies.
Frequency of updates: Analyze how often records are modified, aiding in understanding data usage patterns and identifying potential areas for optimization.
Here is an example of how you might want to set updated_at for an updated wallet:
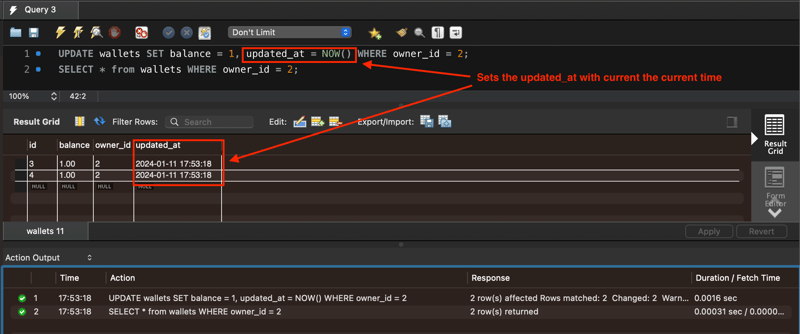
The NOW() function returns the current date and time.
Note: The date and time is returned as "YYYY-MM-DD HH-MM-SS" (string) or as YYYYMMDDHHMMSS.uuuuuu (numeric).
Deleting records
Best practice: Soft delete
Soft delete in MySQL refers to the technique of marking records as deleted without physically removing them from the database. This allows for potential recovery or access to historical data while still maintaining data integrity and consistency.
Here's how it typically works:
Add a Deleted Flag: A new column, often named is_deleted or deleted_at, is added to the table to store a deletion indicator.
Update the Flag: When a record is "deleted," instead of using the DELETE statement, you update the flag column to a value like 1 or a timestamp indicating deletion.
Query Adjustments: All subsequent queries that retrieve data must filter out the "deleted" records using a WHERE clause that checks the flag column (e.g., WHERE is_deleted = 0).
Benefits of Soft Delete in MySQL:
Recoverability: Accidentally deleted records can be restored by simply resetting the flag.
Auditing: You can track the history of deleted records for compliance or analysis.
Data Preservation: Maintains historical data for potential future use, even if it's not actively displayed.
Referential Integrity: Soft deletes help preserve referential integrity in related tables by avoiding broken foreign key relationships.
Please be mindful of legislation, if unsure, consult the company legal department. In some cases and in some localities the law requires us to actually delete the data, and in those cases the delete flag, while technically the safest solution, will not satisfy the law, the data needs to actually be physically destroyed.
Implementation Considerations:
Consistency: Ensure all queries account for the flag column to avoid displaying "deleted" records unintentionally.
Performance: Regularly purging truly unnecessary "deleted" records can improve performance and reduce storage overhead.
Indexing: Create appropriate indexes on the flag column to optimize query performance.
Application Logic: Adapt application code to handle soft deletes consistently, including both data retrieval and deletion operations.
Hard delete considerations
-
Confirm Before Deletion:
- Use
SELECTqueries to preview the data to be deleted and ensure accuracy. - Implement user prompts or warnings before execution to prevent accidental deletions.
- Use
-
Transactional Control:
- Enclose
DELETEstatements withinSTARTandCOMMITtransactions for atomicity and rollback if needed. - Use savepoints to create checkpoints for partial rollbacks if necessary.
- Enclose
-
Filtering and Targeting:
- Use precise
WHEREclauses to target specific records for deletion.Use savepoints to create checkpoints for partial rollbacks if necessary. - Avoid overly broad
DELETEstatements without conditions to prevent unintended data loss.
- Use precise
-
Optimize for Performance:
- Batch Deletions: Group multiple
DELETEstatements into a single transaction for efficiency, especially for large datasets. - Indexing: Ensure appropriate indexes exist on columns used in WHERE clauses to speed up deletion operations.
- Partitioning: Consider partitioning tables by date or other criteria for targeted deletions and improved performance.
- Batch Deletions: Group multiple
-
Logging and Auditing:
- Enable MySQL's general query log or binary log to track
DELETEstatements for auditing purposes. - Create custom triggers to log additional details about deletions, such as timestamps, user information, and affected data.
- Enable MySQL's general query log or binary log to track
-
Security and Permissions:
- Grant
DELETEprivileges only to authorized users or roles to prevent unauthorized data removal. - Consider using stored procedures with permission checks for controlled deletion access.
- Grant
-
Backups and Recovery:
- Maintain regular database backups to recover from accidental deletions or system failures.
- Practice restoring backups to ensure they function correctly in case of need.
Pro tip: Export the data you plan to delete using MySQLWorkbench.
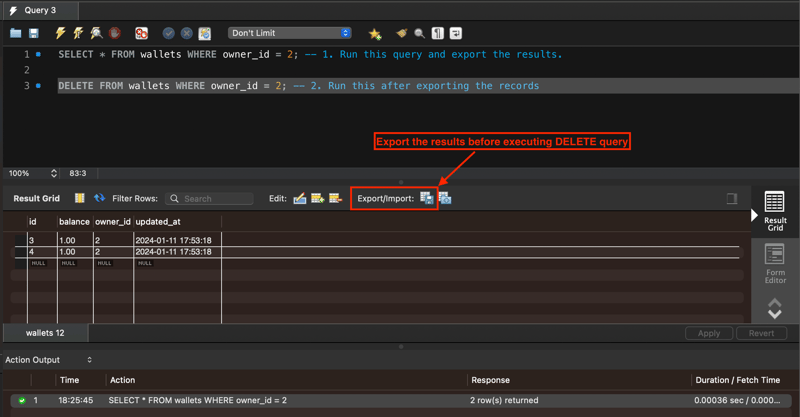
IMPORTANT: While this might help to recover the current table it’s not silver bullet, because cascade updates/deletes can occur during deletion of the current table. Hard delete could be difficult to recover, so don’t take this lightly. See “Referential Actions” section from MySQL docs.
Ruby on Rails DB best practices
Best practice: Altering schema with Rails migrations
Migrations are a feature of Active Record that allows you to evolve your database schema over time. Rather than write schema modifications in pure SQL, migrations allow you to use a Ruby DSL to describe changes to your tables.
Rules of thumb
NEVER alter existing migrations: Instead, you should write a new migration that performs the changes you require. Editing a freshly generated migration that has not yet been committed to source control (or, more generally, which has not been propagated beyond your development machine) is relatively harmless. See https://guides.rubyonrails.org/active_record_migrations.html#changing-existing-migrations.
Keep It Reversible: Ensure that your migrations are reversible. This means defining both up and down methods. This is crucial for rolling back changes if needed.
One Change per Migration: Each migration should represent a single logical change to the database schema. This makes it easier to manage and understand the evolution of your database.
Use Change Method Wisely: The change method is powerful, but be cautious when using it. Ensure that the changes made are reversible and won't cause issues during rollback.
Test Migrations: Test your migrations on a staging environment before applying them to production. This helps catch potential issues early on.
Best practice: Altering data with rake tasks
Rake tasks offer a powerful way to automate data manipulation in Rails applications. But when wielding this tool for altering data, it's essential to prioritize both effectiveness and cleanliness. Here are some best practices to make your data-altering Rake tasks shine:
Custom rake tasks have a .rake extension and are placed in Rails.root/lib/tasks. You can create these custom rake tasks with the bin/rails generate task command.
If you need to interact with your application models, perform database queries, and so on, your task should depend on the environment task, which will load your application code.
task task_that_requires_app_code: [:environment] do
User.create!
end
Just like migrations, rake tasks have some shared best practices like “Keep It Reversible“.
Let’s see an example of the “Keep it Reversible“ rule.
# lib/tasks/user_name_updates.rake
namespace :users do
desc "Update user names with a specified prefix and store original names in backup.csv"
task :update_names, [:prefix] => :environment do |task, args|
prefix = args[:prefix]
raise "Please provide a prefix" unless prefix
# Store original names in CSV for rollback
CSV.open("backup.csv", "w") do |csv|
csv << ["id", "original_name"]
User.find_each do |user|
csv << [user.id, user.name]
user.update!(name: "#{prefix} #{user.name}")
end
end
puts "User names updated successfully! Original names saved in backup.csv"
end
desc "Revert user name updates using data from backup.csv"
task revert_names: :environment do
if File.exist?("backup.csv")
original_names = CSV.read("backup.csv", headers: true)
ActiveRecord::Base.transaction do
original_names.each do |row|
user = User.find(row["id"])
user.update!(name: row["original_name"])
end
end
File.delete("backup.csv") # Remove CSV after successful revert
puts "User names reverted successfully! Backup file removed."
else
puts "Error: Backup file (backup.csv) not found."
end
end
end
To execute the tasks:
- Update names:
rails users:update_names[prefix_to_add] - Revert names:
rails users:revert_names
Best practice: Rails sandbox mode
If you wish to test out some code without changing any data, you can do that by invoking rails console --sandbox.

IMPORTANT: In sandbox mode, database rows are fully locked, which in real time prevents your live production services from modifying them. It’s much more recommended to use sandbox mode in non-production environments.
Rails DB transactions
This article from HoneyBadger explains most relevant topics about Rails DB transactions.
Key Takeaways
To complement this article and keep your data safe, here are some key takeaways.
-
Backups are Indispensable:
- Protect against data loss from hardware failures, human errors, or malicious attacks.
- Enable recovery to a known good state.
-
Backups Demand Verification:
- Regularly test restore processes to ensure backups are valid and usable.
- Prevent surprises when recovery is critical.
-
Testing in Non-Production Environments:
- Mitigates risks of unanticipated issues in production.
- Catches errors and unintended consequences early.
-
Code Reviews for Destructive Queries:
- Prevent accidental data loss or corruption.
- Ensure code aligns with intended actions.
-
Referential Actions Enforce Integrity:
- Maintain consistency and prevent orphaned records.
- Define how database operations cascade across related tables.
-
Recovery Strategies Provide Options:
- Full restore for complete database recovery.
- Point-in-time for restoring to a specific time.
- Transaction log for restoring individual transactions.
-
Change Data Capture (CDC) Enhances Data Protection and Insights:
- Tracks changes in real-time, enabling:
- Data replication for real-time analytics or disaster recovery.
- Audit trails for compliance and security.
- Efficient incremental updates.
By embracing these practices, you'll establish a resilient foundation for safeguarding your valuable data and maintaining business continuity in the face of unexpected challenges.
Resources:
- https://www.freecodecamp.org/news/how-to-use-mysql-transactions/
- https://dev.mysql.com/doc/refman/8.0/en/commit.html
- https://dev.mysql.com/doc/refman/8.0/en/savepoint.html
- https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_now
- https://dev.mysql.com/doc/refman/8.0/en/create-table-foreign-keys.html
- https://learn.microsoft.com/en-us/azure/azure-sql/database/change-data-capture-overview?view=azuresql
- https://github.com/jhawthorn/discard
- https://guides.rubyonrails.org/command_line.html#bin-rails-console
- https://api.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html
- https://edgeguides.rubyonrails.org/active_record_migrations.html
Posted on March 9, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.