Understanding IPFS in Depth(2/6): What is InterPlanetary Linked Data(IPLD)?

vasa
Posted on December 31, 2019
This article was first published on our open-source platform, SimpleAsWater.com. If you are interested in IPFS, Libp2p, Ethereum, Zero-knowledge Proofs, DeFi, CryptoEconomics, IPLD, Multiformats, and other Web 3.0 projects, concepts and interactive tutorials, then be sure to check out SimpleAsWater.
This post is a continuation(part 2) in a new “Understanding IPFS in Depth” series which will help anybody to understand the underlying concepts of IPFS. If you want an overview of what is IPFS and how it works, then you should check out the first part too 😊
Understanding IPFS in Depth(1/6): A Beginner to Advanced Guide
In our first part of the series we briefly discussed IPLD. We saw that IPLD deals with “defining the data” in IPFS(well, not just in IPFS). In this part, we will dive fully into IPLD and discuss:
- The Significance of IPLD: What is the philosophy behind it, Why do we need it and Where does it fit into IPFS?
- How does IPLD Work?: An Explanation of its specification and how does it coordinate with other components of IPFS?
- Playing with IPLD: Well, It’s always fun to play 😊
If you like high-tech Web3 concepts like IPLD explained in simple words with interactive tutorials, then check out SimpleAsWater.com.
I hope you learn a lot about IPFS from this series. Let’s start!
The Significance of IPLD
IPLD is not just a part of the IPFS project, but a separate project in itself. To understand its significance in the decentralized world we have to understand the concept of Linked Data: The Semantic Web.
What is Linked Data & Why do we Need it?
The Semantic Web or Linked Data is a term coined by Sir Tim Berners Lee in a seminal article published in Scientific American in 2001. Berners Lee articulated a vision of a World Wide Web of data that machines could process independently of humans, enabling a host of new services transforming our everyday lives. While the paper’s vision of most web pages containing structured data that could be analyzed and acted upon by software agents has NOT materialized, the Semantic Web has emerged as a platform of increasing importance for data interchange and integration through the growing community implementing data sharing using international semantic web standards, called Linked Data.
There are many current examples of the use of semantic web technologies and Linked Data to share valuable structured information in a flexible and extensible manner across the web. Semantic Web technologies are used extensively in the life sciences to facilitate drug discovery by finding paths across multiple datasets showing associations between drugs and side effects via genes linked to each. The New York Times has published its vocabulary of approximately 10,000 subject headings developed over 150 years as Linked Data and will expand coverage to approximately 30,000 topic tags; they encourage the development of services consuming these vocabularies and linking them with other online resources. The British Broadcasting Corporation uses Linked Data to make content more findable by search engines and more linkable through social media; to add additional context from supplemental resources in domains like music or sports, and to propagate linkages and editorial annotations beyond their original entry target to bring relevant information forward in additional contexts. The home page of the United States data.gov site states, “As the web of linked documents evolves to include the Web of linked data, we’re working to maximize the potential of Semantic Web technologies to realize the promise of Linked Open Government Data.” And also all the social media websites use Linked Data to create a web of People to make their platform as engaging as possible.
So we do have some Linked Data but we still have a long way to go in order to harness the true power of Linked Data.
Now imagine if you could refer your latest commits in a git branch to a bitcoin transaction to timestamp your work. So, by linking your git commit, you can view the commit from your blockchain explorer. Or, if you could link your Ethereum contract to media on IPFS, perhaps modifying it and tracking its changes on each function execution.
All this is possible using IPLD.
IPLD is the data model of the content-addressable web(as discussed in part1).
It allows us to treat all hash-linked data structures as subsets of a unified information space, unifying all data models that link data with hashes as instances of IPLD.
Or in other words, IPLD is a set of standards and implementations for creating decentralized data-structures that are universally addressable and linkable. These structures allow us to do for data what URLs and links did for HTML web pages.
Content addressing through hashes has become a widely-used means of connecting data in distributed systems, from the blockchains that run your favorite cryptocurrencies, to the commits that back your code, to the web’s content at large. Yet, whilst all of these tools rely on some common primitives, their specific underlying data structures are NOT interoperable(as right now I can’t connect my git commit to a blockchain transaction).
IPLD is a single namespace for all hash-inspired protocols. Through IPLD, links can be traversed across protocols, allowing you to explore data regardless of the underlying protocol.
Before diving deeper into IPLD, Let’s see the properties of IPLD.
Properties of IPLD
The sky’s the limit as IPLD allows you to work across protocol boundaries. The point is that IPLD provides libraries that make the underlying data interoperable across tools and across protocols by default.
A canonical data model
A self-contained descriptive model that uniquely identifies any hash-based data structure and ensures the same logical object always maps to the exact same sequence of bits.
Protocol independent resolution
IPLD brings isolated systems together(like connecting Bitcoin, Ethereum and git), making integration with existing protocols simple.
Upgradeable
With Multiformats(we will dive more into this in part 4) support, IPLD is easily upgradeable and will grow with your favorite protocols.
Operates across formats
Express your IPLD objects in various serializable formats like JSON, CBOR, YAML, XML and many more, making IPLD a cinch to use with any framework.
Backward compatible
Non-intrusive resolvers make IPLD easy to integrate within your existing work.
A namespace for all protocols
IPLD allows you to explore data across protocols seamlessly, binding hash-based data structures together through a common namespace.
Now, let’s dive deeper into the IPLD.
Diving Deeper into IPLD Specs
IPLD is not a single specification, it is a set of specifications.

The goal of this stack is to enable decentralized data-structures which in turn will enable more decentralized applications.
Many of the specifications in this stack are inter-dependent.
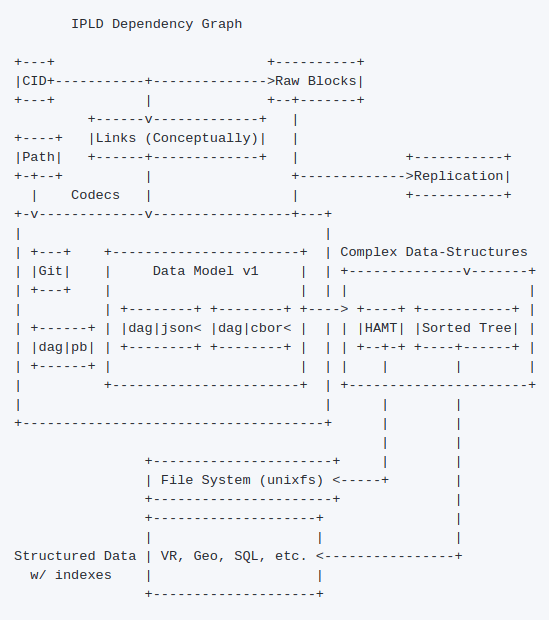
These diagrams show a high level of project specification of IPLD. Even if you don’t understand it fully it’s totally OK.
To learn more about IPLD, here is a great talk by Juan Benet.
OK. Enough of theoretical stuff. Let’s dive into the most fun part of this post 😊
In IPFS, IPLD helps to structure and link all the data chunks/objects. So, as we saw in part 1, IPLD was responsible for organizing all the data chunks that constituted the image of the kitty🐱.
Playing with IPLD
In IPFS, IPLD helps to structure and link all the data chunks/objects. So, as we saw in part 1, IPLD was responsible for organizing all the data chunks that constituted the image of the kitty🐱.
In this part, we will create a medium.com like publication system, and link the tags, articles, and authors using IPLD. This will help you to get a more intuitive understanding of IPLD. You can also find the complete tutorial on Github.
Let’s get started!
Before creating the publication system, we’ll be exploring the IPFS DAG API, which lets us store data objects in IPFS in IPLD format. (You can store more exciting things in IPFS, like your favorite cat GIF, but we will stick to simpler things for now.)
If you are not familiar with Merkle tries and DAGs then head over here. If you have an understanding of what these terms mean then continue…
Create a folder name ipld-blogs. Run npm init and press Enter for all the questions.
Now install the dependencies using:
npm install ipfs-http-client cids --save
After installing the module your project structure will look like this:
Creating an IPLD format node
You can create a new node by passing a data object into the ipfs.dag.put method, which returns a Content Identifier (CID) for the newly created node.
ipfs.dag.put({name: ‘vasa’})
A CID is an address for a block of data in IPFS that is derived from its content. Every time someone puts the same {name: 'vasa'} data into IPFS, they'll get back an identical CID to the one you got. If they put in {name: 'vAsa'} instead, the CID will be different.
Paste this code in tut.js and run node tut.js
//Initiate ipfs and CID instance
const ipfsClient = require('ipfs-http-client');
const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
/*
Creating an IPLD format node:
ipfs.dag.put(dagNode, [options], [callback])
For more information see:
https://github.com/ipfs/interface-js-ipfs-core/blob/master/SPEC/DAG.md#ipfsdagputdagnode-options-callback
*/
ipfs.dag.put({name: "vasa"}, { format: 'dag-cbor', hashAlg: 'sha2-256' }, (err, cid)=>{
if(err){
console.log("ERR\n", err);
}
//featching multihash buffer from cid object.
const multihash = cid.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
const cids = new CID(1, 'dag-cbor', multihash);
//Printing out the cid in a readable format
console.log(cids.toBaseEncodedString());
//zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S
});
You will get this CID zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S. We have successfully created an IPLD format node.
Connecting IPLD objects
One important feature of Directed Acyclic Graphs (DAGs) is the ability to link them together.
The way you express links in the ipfs DAG store is with the CID of another node.
For example, if we wanted one node to have a link called “foo” pointed to another CID instance previously saved as barCid, it might look like:
{
foo: barCid
}
When we give a field a name and make its value a link to a CID, we call this a named link.
Below is the code showing how to create a named link.
//Initiate ipfs and CID instance
const ipfsClient = require('ipfs-http-client');
const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
/*
Creating an IPLD format node:
ipfs.dag.put(dagNode, [options], [callback])
For more information see:
https://github.com/ipfs/interface-js-ipfs-core/blob/master/SPEC/DAG.md#ipfsdagputdagnode-options-callback
*/
async function linkNodes(){
let vasa = await ipfs.dag.put({name: 'vasa'});
//Linking secondNode to vasa using named link.
let secondNode = await ipfs.dag.put({linkToVasa: vasa});
}
linkNodes();
Reading Nested data using Links
You can read data from deeply nested objects using path queries.
ipfs.dag.get allows queries using IPFS paths. These queries return an object containing the value of the query and any remaining path that was unresolved.
The cool thing about this API is that it can also traverse through links. Here is an example of how you can read nested data using links.
//Initiate ipfs and CID instance
const ipfsClient = require('ipfs-http-client');
const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
function errOrLog(err, result) {
if (err) {
console.error('error: ' + err)
} else {
console.log(result)
}
}
async function createAndFeatchNodes(){
let vasa = await ipfs.dag.put({name: 'vasa'});
//Linking secondNode to vasa using named link.
let secondNode = await ipfs.dag.put({
publication: {
authors: {
authorName: vasa
}
}
});
//featching multihash buffer from cid object.
const multihash = secondNode.multihash;
//passing multihash buffer to CID object to convert multihash to a readable format
const cids = new CID(1, 'dag-cbor', multihash);
//Featching the value using links
ipfs.dag.get(cids.toBaseEncodedString()+'/publication/authors/authorName/name', errOrLog);
/* prints { value: 'vasa', remainderPath: '' } */
}
createAndFeatchNodes();
You can also explore your IPLD nodes using this cool IPLD explorer. Like, if I want to see this CID: zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S, I will go to this link:
https://explore.ipld.io/#/explore/zdpuAujL3noEMamveLPQWJPY6CYZHhHoskYQaZBvRbAfVwR8S
Now, as we have explored IPFS DAG API we are ready to work with IPLD and create our publication system.
Creating a Publication System
We will create a simple blogging application. This blogging application can:
Add a new Author IPLD object. An author will have 2 fields: name and profile(a tag line for your profile).
Create a new Post IPLD object. A post will have 4 fields: author, content, tags and publication date-time.
Read a Post using post CID.
Below is the code implementation for the above goals.
/*
PUBLICATION SYSTEM
Adding new Author
An author will have
-> name
-> profile
Creating A Blog
A Blog will have a:
-> author
-> content
-> tags
-> timeOfPublish
List all Blogs for an author
Read a Blog
*/
//Initiate ipfs and CID instance
const ipfsClient = require('ipfs-http-client');
const CID = require('cids');
//Connecting ipfs instance to infura node. You can also use your local node.
const ipfs = new ipfsClient({ host: 'ipfs.infura.io', port: '5001', protocol: 'https' });
//Create an Author
async function addNewAuthor(name) {
//creating blog author object
var newAuthor = await ipfs.dag.put({
name: name,
profile: "Entrepreneur | Co-founder/Developer @TowardsBlockChain, an MIT CIC incubated startup | Speaker | https://vaibhavsaini.com"
});
console.log("Added new Author "+name+": " + newAuthor);
return newAuthor;
}
//Creating a Blog
async function createBlog(author, content, tags) {
//creating blog object
var post = await ipfs.dag.put({
author: author,
content: content,
tags: tags,
timeOfPublish: Date()
});
console.log("Published a new Post by " + author + ": " + post);
return post;
}
//Read a blog
async function readBlog(postCID) {
ipfs.dag.get(postCID + "", (err, post) => {
if (err) {
console.error('Error while reading post: ' + err)
} else {
console.log("Post Details\n", post);
ipfs.dag.get(postCID + "/author", (err, author) => {
if (err) {
console.error('Error while reading post author: ' + err)
} else {
console.log("Post Author Details\n", author);
}
});
}
});
}
function startPublication() {
addNewAuthor("vasa").then(
(newAuthor) => {
createBlog(newAuthor,"my first post", ["ipfs","ipld","vasa","towardsblockchain"]).then(
(postCID) => readBlog(postCID))
});
}
startPublication();
On running this code and it will first create an author via addNewAuthor, which will return the authors CID. Then this CID will be passed to createBlog function which will return the postCID. This postCID will be used by readBlog function to fetch the post details.
You can create more complex applications using IPLD…
Ok. that’s it for this part. If you have any question, then you can shoot them in the comments.
I hope you have learned a lot of thing from this post. In the next post, we will dive into the naming System of the distributed web, IPNS. So stay tuned…
This article was first posted on SimpleAsWater.com
Posted on December 31, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.