Under the hood: AvionDB P2P Syncing

vasa
Posted on May 22, 2020

One of the big challenges while working with distributed databases is to sync/replicate data between the peers.
There are multiple things that make replication challenging in distributed systems:
- Access Control: There should be a way to control the access to your data, so that you can decide which peer can access your data with what permissions (read, write, etc.)
- Different Runtimes: The replication should work across different devices: your PC, mobile, browser, etc. But all these devices don't have comparable networking, storage & compute resources.
- Restrictive Networks: Firewalls, NATs don't allow all the peers to talk to each other. So, we have to come up with new ways to connect peers that live behind these restrictive networks.
In the next couple of posts, we will discuss how we at Dappkit are working to make data replication developer friendly so that you as a developer don't have to think about all these challenges.
This post goes through an example of how today we replicate data between the peers using AvionDB, and our plans to make it much easier than what it is today.
A peer-to-peer to-do list
Well, a to-do list is not an app that will make you go nuts, but it does show the process of data replication with an easy to understand the application.
The app can be divided into 2 parts:
- Creating, listing & updating to-do(s).
- Syncing the to-do list across different peers.
Let's get right into it. You can find the working code & the final to-do app demo here.
Creating, listing & updating to-do(s)
This is the easy part of the app. We create a simple interface using bootstrap to create, list & update to-do(s).

You can see a QR code too, which we will use for scanning the URL so that you can sync the to-do list on your mobile. You can also use a link that you can directly put in your browser or share it with anyone who wants to sync the to-do list.
Now, we need to use AvionDB to store, list & update the to-do(s) that will be stored locally in your browser.
AvionDB uses IPFS internally to store its data, so we need to import AvionDB & IPFS.
We use the CDN links and add them to the public/index.html
so that we can access them across the whole application.

If you want to use npm modules, here are the modules for AvionDB & IPFS.
Now, we need to initialize AvionDB & IPFS.

This creates a Database named "TodoList", and a Collection named "todos" in it.
Now, we need to add, list & update todo in the "todos" collection.
Add To-do(s)
You can use functions like insert or insertOne to add todo(s).

Note that each record that is added in the collection will have an \_id field added to it automatically, which serves as a unique identifier of the record. You can override the default \_id by adding an \_id field with your record.
You can find more information on the functions here.
Get To-do(s)
You can fetch the to-do(s) using functions like find & findOne.
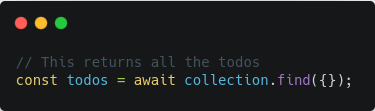
This query returns all the to-do(s) in the "todos" collection.
You can find more information on the functions here.
Update To-do(s)
You can update the to-do(s) using functions like update, updateMany, findOneAndUpdate, etc.

This updates the isDone status of a to-do.
You can find more information on the functions here.
Now, as we have created a simple todo app to store, fetch & update the to-do(s), let's see how we can sync/replicate our to-do(s) with multiple devices.
Syncing the to-do list across different peers
Now before going into the code, let's first understand a few concepts that will help you understand peer-to-peer syncing.
Let's take a real-world example.
As we are going through COVID pandemic, Ross & Rachel are attending their classes over the online lectures.
Now, Ross & Rachel want to exchange their notes & do a group study to prepare for their test.
In order to do so, here is what to need to do:
- Exchange their email addresses.
- Find a common platform to use for communication (Skype, Hangouts, Zoom, etc.). Maybe they also need to decide which language (English, French, Chinese, etc.) they would use to discuss over the call.
- Send an invite to their fellow participant.
- Join the call, exchange notes & do a group study.
This is very similar to what we are going to do to sync data between the AvionDB peers.
In order to sync the data between any 2 (or more) peers, we need to:
- First, find each-others addresses by which we can connect.
- Find a common protocol (WebSocket, WebRTC) that both peers can use to communicate.
- Establish a connection using the addresses & the common protocol.
- And at last sync the data (to-do list).
Let's go through each of these points and see how this works under the hood.
Finding Addresses
Each peer in the network has a unique address that can be used to uniquely identify the peer in the network, known as peerIds.
In the case of AvionDB, we use Libp2p (an internal part of IPFS) peerIds, which look something like this: Qme499EjQog7UjvuJiduzw1UKMe6hZ1rZ1wQrxz7qpq7TS.
These peerIds are generated using a project called Multiformats, which is used to create interoperable, future-proof protocols.
You don't need to go too deep into Libp2p or Multiformats. You just need to know that we use the peerIds as addresses (email Id, or a mobile number) to identify & communicate with other peers in the network.
Common Protocol for Communication
As we talked about Different Runtimes at the beginning of this post, different devices have different networking, storage & compute resources.
This means that a browser does not have as much networking, storage & compute resources as a PC.
As we talked about the Ross & Rachel example, we saw that we needed to decide on a common platform & language that they could use to communicate.
Similarly, a browser, a PC and a mobile need to decide what common protocols they use so that they can communicate with each other, despite their differences in networking, storage & compute resources.
A fact that you should know here is that all these platforms support websocket protocol over TCP. So, here websocket is the "common platform or language" that all the devices can use to communicate with each other.
Now, we have the common protocol, but there are restrictive environments such as firewalls & NATs that restrict the peers from discovering each other.
Here is where circuit-relay comes into the picture.
Circuit Relay
In p2p networks there are many cases where two nodes can't talk to each other directly. That may happen because of network topology, i.e. NATs, or execution environments - for example browser nodes can't connect to each other directly because they lack any sort of socket functionality and relying on specialized rendezvous nodes introduces an undesirable centralization point to the network. A circuit-relay is a way to solve this problem - it is a node that allows two other nodes that can't otherwise talk to each other, use a third node, a relay to do so.
How does circuit relay work?
Here is a simple diagram depicting how a typical circuit-relay connection might look:

Peer A tries to connect to Peer B but, UH-OH! There is a firewall in between that's preventing it from happening. If both Peer A and Peer B know about a relay, they can use it to establish the connection.
This is what it looks like, in simplified steps:
-
Peer Atries to connect toPeer Bover one of its known addresses - Connection fails because of firewall/NAT/incompatible transports/etc...
- Both
Peer AandPeer Bknow of the same relay -Peer C -
Peer Afalls back to dialing overPeer CtoPeer Busing its'/p2p-circuit'address, which involves: -
Peer Asends aHOPrequest toPeer C -
Relayextracts the destination address, figures out that a circuit toPeer Bis being requested -
Relaysends aSTOPrequest toPeer B -
Peer Bresponds with aSUCCESSmessage -
Relayproceed to create a circuit over the two nodes -
Peer AandPeer Bare now connected overPeer C
That's it!
What's up with this HOP and STOP?
Circuit relay consists of two logical parts — dialer/listener and relay (HOP). The listener is also known as the STOP node. Each of these — dial, listen, and relay — happen on a different node. If we use the nodes from the above example, it looks something like this:
- The
dialerknows how to dial a relay (HOP) -Node A - The relay (
HOP) knows how to contact a destination node (STOP) and create a circuit -Relaynode - The listener (
STOP) knows how to process relay requests that come from the relay (HOP) node -Node B
Fun fact - the *HOP* and *STOP* names are also used internally by circuit to identify the network message types.
A few caveats (and features)
There are a couple of caveats and features to be aware of:
- A
Relaywill only work if it already has a connection to theSTOPnode - No
multihopdialing is supported. It's a feature planned for upcoming releases from Libp2p (no date on this one) -
multihopdialing is when several relays are used to establish the connection. - It is possible to use explicit relay addresses to connect to a node, or even to listen for connections on. We will talk more about this below.
A word on circuit relay addresses
A circuit relay address is a multiaddress that describes how to either connect to a peer over a relay (or relays), or allow a peer to announce it is reachable over a particular relay or any relay it is already connected to.
Circuit relay addresses are very flexible and can describe many different aspects of how to establish the relayed connection. In its simplest form, it looks something like this:
/p2p-circuit/ipfs/QmPeer
If we want to be specific as to which transport we want to use to establish the relay, we can encode that in the address as well:
/ip4/127.0.0.1/tcp/65000/ipfs/QmRelay/p2p-circuit/ipfs/QmPeer
This tells us that we want to use QmRelay
located at address 127.0.0.1 and port 65000.
/ip4/127.0.0.1/tcp/65000/ipfs/QmRelay/p2p-circuit/ip4/127.0.0.1/tcp/8080/ws/ipfs/QmPeer
We can take it a step further and encode the same information for the destination peer. In this case, we have it located at 127.0.0.1 on port 8080 and using a Web sockets transport!
/ip4/127.0.0.1/tcp/65000/ipfs/QmRelay/p2p-circuit
If a node is configured with this address, it will use the specified host (/ip4/127.0.0.1/tcp/65000/ipfs/QmRelay) as a relay and it will be reachable over this relay.
- There could multiple addresses of this sort specified in the config, in which case the node will be reachable over all of them.
- This is useful if, for example, the node is behind a firewall but wants to be reachable from the outside over a specific relay.
Other use-cases are also supported by this scheme, e.g. we can have multiple hops (circuit-relay nodes) encoded in the address, something planed for future releases.
In our to-do list example we created a relay peer with the following multiaddress:
/dnsaddr/node1.dappkit.io/tcp/6969/wss/p2p/QmfLwmXF25u1n5pD8yXcbmZew3td66qPU1FroWNrkxS4bt
You can use this relay to connect your peers too!
Now as we have discussed how to get through different runtimes & restrictive networks, let's now move on to see how to establish a connection.
Establish a connection
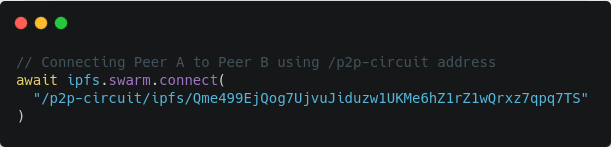
In order to connect to any peer using IPFS, we have a function ipfs.swarm.connect(multiaddress) where multiaddress is the address of any peer that a peer wants to connect to.
So, for example, if Peer A wants to connect to the relay – Peer C then we will do something like this:

After, we have connected Peer A & Peer B with the relay – Peer C we can now use the /p2p-circuit address of Peer B to connect to Peer A or vice-versa.
Voila! You have now connected the peers 🎉 Now we just need to replicate the data between the 2 peers.
Sync data between the peers
In order to sync data between the peers, we need the database address of "TodoList" database & the name of the collection that we created above.
To get this information we need to communicate this data between the peers. For this, we use something called Publish/Subscribe
Publish/Subscribe is a system where peers congregate around topics they are interested in. Peers interested in a topic are said to be subscribed to that topic:
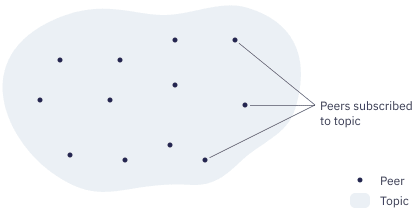
Peers can send messages to topics. Each message gets delivered to all peers subscribed to the topic:

So, if we create a topic: peerId of Peer A so that anyone who is subscribed to peerId of Peer A can get the messages from Peer A. This way Peer A can publish the database address of "TodoList" database & the name of the collection to all its subscribers in one go!
Here is the example code showing Peer B subscribed to Peer A using its peerId and using the published message (msg) to open the database & the collection.

Here is an example code showing Peer A publishing the message (msg) to the topic peerIdA.

And that's it! This is how we currently sync data between peers in AvionDB.
Here is a working demo of the to-do list app.
Here are some useful links:
But this is not something we want you to go through when you are creating your application. We want to give developers a simple way to sync data that abstracts away all this complexity of different runtimes, restrictive networks, etc.
So we are working on making this a better experience for the developers so that they can focus on building applications rather than tackling these core issues.
If you want to keep a close track on our progress then feel free to reach us out on our Discord server.
NOTE: We have not talked about Access Control in this post, but we have a ton of examples already built for different Web 2.0 & Web 3.0 based access control. Feel free to check them out here. We will be back with posts on access controller too. Meanwhile, if you have any questions, feel free to reach us out on our Discord server.
Posted on May 22, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related