How percentile approximation works (and why it's more useful than averages)

davidkohn88
Posted on November 24, 2021

Table of contents
- Things I forgot from 7th grade math: percentiles vs. averages
- Long tails, outliers, and real effects: Why percentiles are better than averages for understanding your data
- How percentiles work in PostgreSQL
- Percentile approximation: what it is and why we use it in TimescaleDB hyperfunctions
- Percentile approximation deep dive: approximation methods, how they work, and how to choose
- Wrapping it up
Get a primer on percentile approximations, why they're useful for analyzing large time-series data sets, and how we created the percentile approximation hyperfunctions to be efficient to compute, parallelizable, and useful with continuous aggregates and other advanced TimescaleDB features.
In my recent post on time-weighted averages, I described how my early career as an electrochemist exposed me to the importance of time-weighted averages, which shaped how we built them into TimescaleDB hyperfunctions. A few years ago, soon after I started learning more about PostgreSQL internals (check out my aggregation and two-step aggregates post to learn about them yourself!), I worked on backends for an ad analytics company, where I started using TimescaleDB.
Like most companies, we cared a lot about making sure our website and API calls returned results in a reasonable amount of time for the user; we had billions of rows in our analytics databases, but we still wanted to make sure that the website was responsive and useful.
There’s a direct correlation between website performance and business results: users get bored if they have to wait too long for results, which is obviously not ideal from a business and customer loyalty perspective. To understand how our website performed and find ways to improve, we tracked the timing of our API calls and used API call response time as a key metric.
Monitoring an API is a common scenario and generally falls under the category of application performance monitoring (APM), but there are lots of similar scenarios in other fields including:
- Predictive maintenance for industrial machines
- Fleet monitoring for shipping companies
- Energy and water use monitoring and anomaly detection
Of course, analyzing raw (usually time-series) data only gets you so far. You want to analyze trends, understand how your system performs relative to what you and your users expect, and catch and fix issues before they impact production users, and so much more. We built TimescaleDB hyperfunctions to help solve this problem and simplify how developers work with time-series data.
For reference, hyperfunctions are a series of SQL functions that make it easier to manipulate and analyze time-series data in PostgreSQL with fewer lines of code. You can use hyperfunctions to calculate percentile approximations of data, compute time-weighted averages, downsample and smooth data, and perform faster COUNT DISTINCT queries using approximations. Moreover, hyperfunctions are “easy” to use: you call a hyperfunction using the same SQL syntax you know and love.
We spoke with community members to understand their needs, and our initial release includes some of the most frequently requested functions, including percentile approximations (see GitHub feature request and discussion). They’re very useful for working with large time-series data sets because they offer the benefits of using percentiles (rather than averages or other counting statistics) while still being quick and space-efficient to compute, parallelizable, and useful with continuous aggregates and other advanced TimescaleDB features.
If you’d like to get started with the percentile approximation hyperfunctions - and many more - right away, spin up a fully managed TimescaleDB service: create an account to try it for free for 30 days. (Hyperfunctions are pre-loaded on each new database service on Timescale Cloud, so after you create a new service, you’re all set to use them).
If you prefer to manage your own database instances, you can download and install the timescaledb_toolkit extension on GitHub, after which you’ll be able to use percentile approximation and other hyperfunctions.
Finally, we love building in public and continually improving:
- If you have questions or comments on this blog post, we’ve started a discussion on our GitHub page, and we’d love to hear from you. And, if you like what you see, GitHub ⭐ are always welcome and appreciated too!
- You can view our upcoming roadmap on GitHub for a list of proposed features, as well as features we’re currently implementing and those that are available to use today.
Things I forgot from 7th grade math: percentiles vs. averages
I probably learned about averages, medians, and modes in 7th grade math class, but if you’re anything like me, they may periodically get lost in the cloud of “things I learned once and thought I knew, but actually, I don’t remember quite as well as I thought.”
As I was researching this piece, I found a number of good blog posts (see examples from the folks at Dynatrace, Elastic, AppSignal, and Optimizely) about how averages aren’t great for understanding application performance, or other similar things, and why it’s better to use percentiles.
I won’t spend too long on this, but I think it’s important to provide a bit of background on why and how percentiles can help us better understand our data.
First off, let’s consider how percentiles and averages are defined. To understand this, let’s start by looking at a normal distribution:

The normal distribution is what we often think of when we think about statistics; it’s one of the most frequently used and often used in introductory courses. In a normal distribution, the median, the average (also known as the mean), and the mode are all the same, even though they’re defined differently.
The median is the middle value, where half of the data is above and half is below. The mean (aka average) is defined as the sum(value) / count(value), and the mode is defined as the most common or frequently occurring value.
When we’re looking at a curve like this, the x-axis represents the value, while the y-axis represents the frequency with which we see a given value (i.e., values that are “higher” on the y-axis occur more frequently).
In a normal distribution, we see a curve centered (the dotted line) at its most frequent value, with decreasing probability of seeing values further away from the most frequent one (the most frequent value is the mode). Note that the normal distribution is symmetric, which means that values to the left and right of the center have the same probability of occurring.
The median, or the middle value, is also known as the 50th percentile (the middle percentile out of 100). This is the value at which 50% of the data is less than the value, and 50% is greater than the value (or equal to it).
In the below graph, half of the data is to the left (shaded in blue), and a half is to the right (shaded in yellow), with the 50th percentile directly in the center.

This leads us to percentiles: a percentile is defined as the value where x percent of the data falls below the value.
For example, if we call something “the 10th percentile,” we mean that 10% of the data is less than the value and 90% is greater than (or equal to) the value.

And the 90th percentile is where 90% of the data is less than the value and 10% is greater:
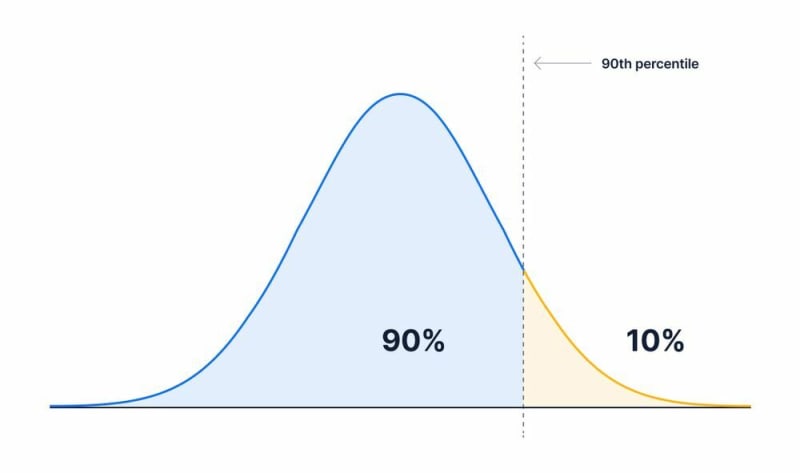
To calculate the 10th percentile, let’s say we have 10,000 values. We take all of the values, order them from smallest to largest, and identify the 1001st value (where 1000 or 10% of the values are below it), which will be our 10th percentile.
We noted before that the median and average are the same in a normal distribution. This is because a normal distribution is symmetric. Thus, the magnitude and number of points with values larger than the median are completely balanced (both in magnitude and number of points smaller than the median).
In other words, there is always the same number of points on either side of the median, but the average takes into account the actual value of the points.
For the median and average to be equal, the points less than the median and greater than the median must have the same distribution (i.e., there must be the same number of points that are somewhat larger and somewhat smaller and much larger and much smaller). (Correction: as pointed out to us in a helpful comment on Hacker News, technically this is only true for symmetric distributions, asymmetric distributions it may or may not be true for and you can get odd cases of asymmetric distributions where these are equal, though they are less likely!)
Why is this important? The fact that median and average are the same in the normal distribution can cause some confusion. Since a normal distribution is often one of the first things we learn, we (myself included!) can think it applies to more cases than it actually does.
It’s easy to forget or fail to realize, that only the median guarantees that 50% of the values will be above, and 50% below – while the average guarantees that 50% of the weighted values will be above and 50% below (i.e., the average is the centroid, while the median is the center).

🙏 Shout out to the folks over at Desmos for their great graphing calculator, which helped make these graphs, and even allowed me to make an interactive demonstration of these concepts!
But, to get out of the theoretical, let’s consider something more common in the real world, like the API response time scenario from my work at the ad analytics company.
Long tails, outliers, and real effects: Why percentiles are better than averages for understanding your data
We looked at how averages and percentiles are different – and now, we’re going to use a real-world scenario to demonstrate how using averages instead of percentiles can lead to false alarms or missed opportunities.
Why? Averages don’t always give you enough information to distinguish between real effects and outliers or noise, whereas percentiles can do a much better job.
Simply put, using averages can have a dramatic (and negative) impact on how values are reported, while percentiles can help you get closer to the “truth.”
If you’re looking at something like API response time, you’ll likely see a frequency distribution curve that looks something like this:

In my former role at the ad analytics company, we’d aim for most of our API response calls to finish in under half a second, and many were much, much shorter than that. When we monitored our API response times, one of the most important things we tried to understand was how users were affected by changes in the code.
Most of our API calls finished in under half a second, but some people used the system to get data over very long time periods or had odd configurations that meant their dashboards were a bit less responsive (though we tried to make sure those were rare!).
The type of curve that resulted is characterized as a long-tail distribution where we have a relatively large spike at 250 ms, with a lot of our values under that and then an exponentially decreasing number of longer response times.
We talked earlier about how in symmetric curves (like the normal distribution), but a long-tail distribution is an asymmetric curve.
This means that the largest values are much larger than the middle values, while the smallest values aren’t that far from the middle values. (In the API monitoring case, you can never have an API call that takes less than 0 s to respond, but there’s no limit to how long they can take, so you get that long tail of longer API calls).
Thus, the average and the median of a long-tail distribution start to diverge:
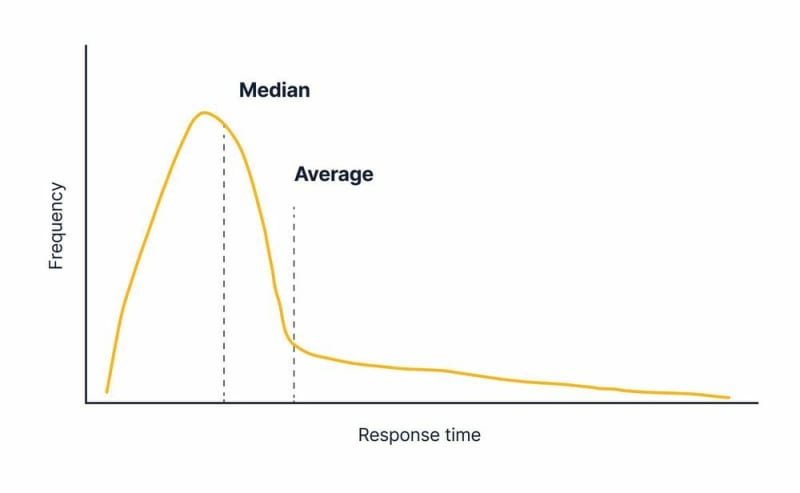
In this scenario, the average is significantly larger than the median because there are enough “large” values in the long tail to make the average larger. Conversely, in some other cases, the average might be smaller than the median.
But at the ad analytics company, we found that the average didn’t give us enough information to distinguish between important changes in how our API responded to software changes vs. noise/outliers that only affected a few individuals.
In one case, we introduced a change to the code that had a new query. The query worked fine in staging, but there was a lot more data in the production system.
Once the data was “warm” (in memory), it would run quickly, but it was very slow the first time. When the query went into production, the response time was well over a second for ~10% of the calls.
In our frequency curve, a response time over a second (but less than 10s) for ~10% of the calls resulted in a second, smaller hump in our frequency curve and looked like this:

In this scenario, the average shifted a lot, while the median slightly shifted, it’s much less impacted.
You might think that this makes the average a better metric than the median because it helped us identify the problem (too long API response times), and we could set up our alerting to notify when the average shifts.
Let’s imagine that we’ve done that, and people will jump into action when the average goes above, say, 1 second(s).
But now, we get a few users who start requesting 15 years of data from our UI...and those API calls take a really long time. This is because the API wasn’t really built to handle this “off-label” use.
Just a few calls from these users easily shifted the average way over our 1s threshold.
Why? The average (as a value) can be dramatically affected by outliers like this, even though they impact only a small fraction of our users. The average uses the sum of the data, so the magnitude of the outliers can have an outsized impact, whereas the median and other percentiles are based on the ordering of the data.

The point is that the average doesn’t give us a good way to distinguish between outliers and real effects and can give odd results when we have a long-tail or asymmetric distribution.
Why is this important to understand?
Well, in the first case, we had a problem affecting 10% of our API calls, which could be 10% or more of our users (how could it affect more than 10% of the users? Well, if a user makes 10 calls on average, and 10% of API calls are affected, then, on average, all the users would be affected... or at least some large percentage of them).
We want to respond very quickly to that type of urgent problem, affecting a large number of users. We built alerts and might even get our engineers up in the middle of the night and/or revert a change.
But the second case, where “off-label” user behavior or minor bugs had a large effect on a few API calls, was much more benign. Because relatively few users are affected by these outliers, we wouldn’t want to get our engineers up in the middle of the night or revert a change. (Outliers can still be important to identify and understand, both for understanding user needs or potential bugs in the code, but they usually aren’t an emergency).
Instead of using the average, we can instead use multiple percentiles to understand this type of behavior. Remember, unlike averages, percentiles rely on the ordering of the data rather than being impacted by the magnitude of data. If we use the 90th percentile, we know that 10% of users have values (API response times in our case) greater than it.
Let’s look at the 90th percentile in our original graph; it nicely captures some of the long tail behavior:

When we have some outliers caused by a few users who’re running super long queries or a bug affecting a small group of queries, the average shifts, but the 90th percentile is hardly affected.

But, when the tail is increased due to a problem affecting 10% of users, we see that the 90th percentile shifts outward pretty dramatically – which enables our team to be notified and respond appropriately:

This (hopefully) gives you a better sense of how and why percentiles can help you identify cases where large numbers of users are affected – but not burden you with false positives that might wake engineers up and give them alarm fatigue!
So, now that we know why we might want to use percentiles rather than averages, let’s talk about how we calculate them.
How percentiles work in PostgreSQL
To calculate any sort of exact percentile, you take all your values, sort them, then find the nth value based on the percentile you’re trying to calculate.
To see how this works in PostgreSQL, we’ll present a simplified case of our ad analytics company’s API tracking.
We’ll start off with a table like this:
CREATE TABLE responses(
ts timestamptz,
response_time DOUBLE PRECISION);
In PostgreSQL we can calculate a percentile over the column response_time using the percentile_disc aggregate:
SELECT
percentile_disc(0.5) WITHIN GROUP (ORDER BY response_time) as median
FROM responses;
This doesn’t look the same as a normal aggregate; the WITHIN GROUP (ORDER BY …) is a different syntax that works on special aggregates called ordered-set aggregates.
Here we pass in the percentile we want (0.5 or the 50th percentile for the median) to the percentile_disc function, and the column that we’re evaluating (response_time) goes in the order by clause.
It will be more clear why this happens when we understand what’s going on under the hood. Percentiles give a guarantee that x percent of the data will fall below the value they return. To calculate that, we need to sort all of our data in a list and then pick out the value where 50% of the data falls below it, and 50% falls above it.
For those of you who read the section of our previous post on how PostgreSQL aggregates work, we discussed how an aggregate like avg works.
As it scans each row, the transition function updates some internal state (for avg it’s the sum and the count), and then a final function processes the internal state to produce a result (for avg divide sum by count).

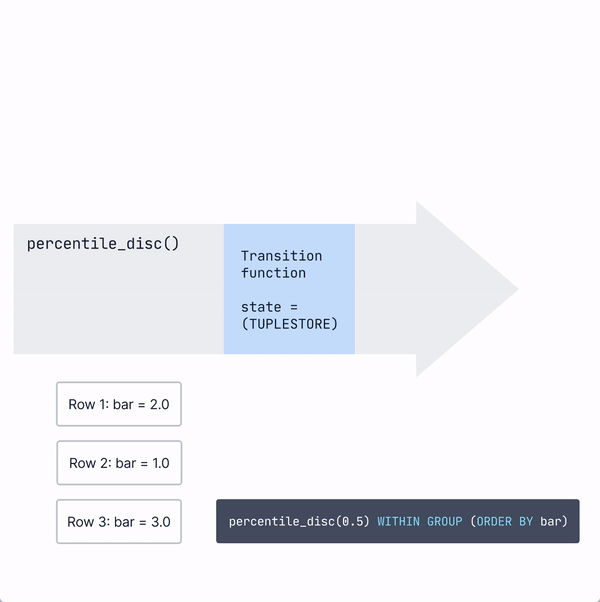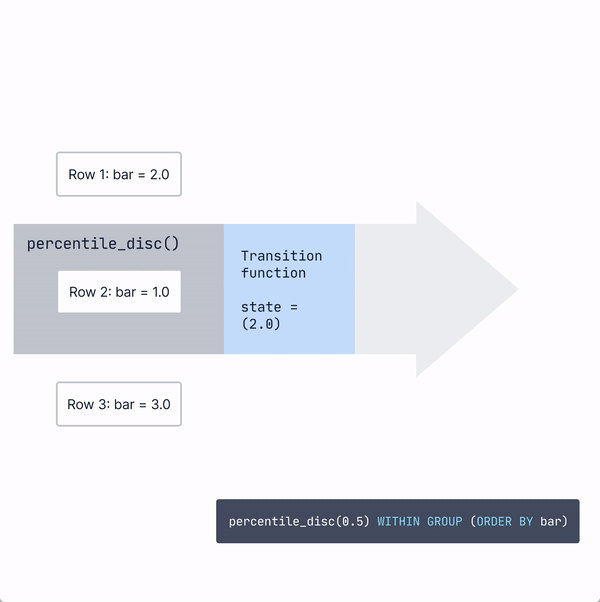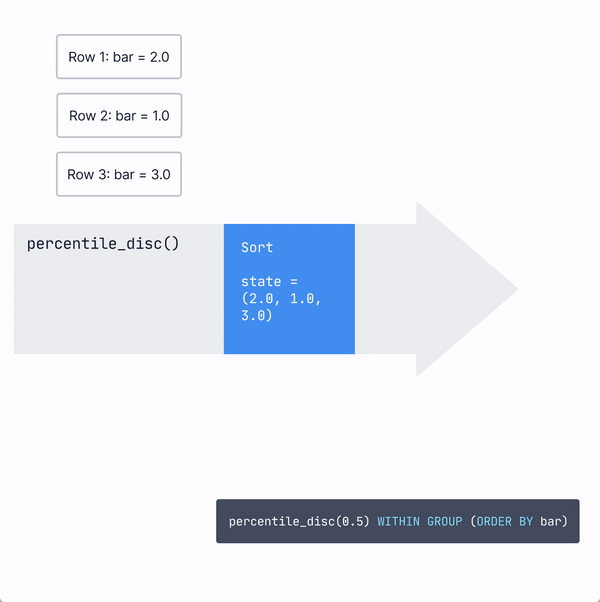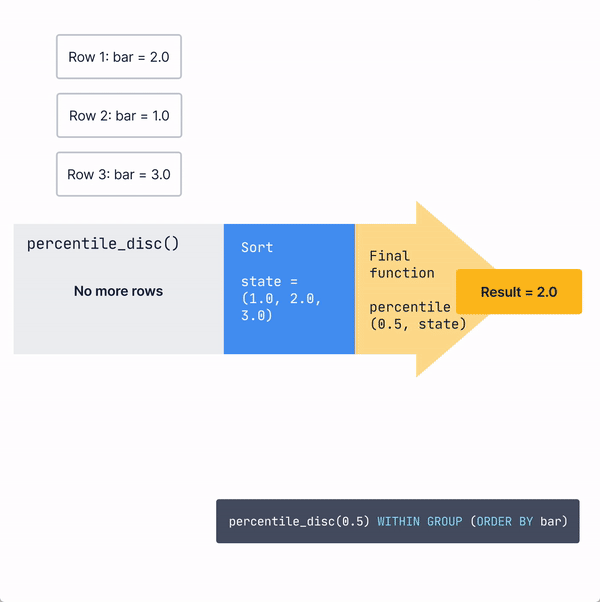
The ordered set aggregates, like percentile_disc, work somewhat similarly, with one exception: instead of the state being a relatively small fixed-size data structure (like sum and count for avg ), it must keep all the values it has processed to sort them and calculate the percentile later.
Usually, PostgreSQL does this by putting the values into a data structure called a tuplestore that stores and sorts values easily.
Then, when the final function is called, the tuplestore will first sort the data. Then, based on the value input into the percentile_disc), it will traverse to the correct point (0.5 of the way through the data for the median) in the sorted data and output the result.
Instead of performing these expensive calculations over very large data sets, many people find that approximate percentile calculations can provide a “close enough” approximation with significantly less work...which is why we introduced percentile approximation hyperfunctions.
Percentile approximation: what it is and why we use it in TimescaleDB hyperfunctions
In my experience, people often use averages and other summary statistics more frequently than percentiles because they are significantly “cheaper” to calculate over large datasets, both in computational resources and time.
As we noted above, calculating the average in PostgreSQL has a simple, two-valued aggregate state. Even if we calculate a few additional, related functions like the standard deviation, we still just need a small, fixed number of values to calculate the function.
In contrast, to calculate the percentile, we need all of the input values in a sorted list.
This leads to a few issues:
- Memory footprint: The algorithm has to keep these values somewhere, which means keeping values in memory until they need to write some data to disk to avoid using too much memory (this is known as “spilling to disk”). This produces a significant memory burden and/or majorly slows down the operation because disk accesses are orders of magnitude slower than memory.
- Limited Benefits from Parallelization: Even though the algorithm can sort lists in parallel, the benefits from parallelization are limited because it still needs to merge all the sorted lists into a single, sorted list in order to calculate a percentile.
- High network costs: In distributed systems (like TimescaleDB multi-node), all the values must be passed over the network to one node to be made into a single sorted list, which is slow and costly.
- No true partial states: Materialization of partial states (e.g., for continuous aggregates) is not useful because the partial state is simply all the values that underlie it. This could save on sorting the lists, but the storage burden would be high and the payoff low.
- No streaming algorithm: For streaming data, this is completely infeasible. You still need to maintain the full list of values (similar to the materialization of partial states problem above), which means that the algorithm essentially needs to store the entire stream!
All of these can be manageable when you’re dealing with relatively small data sets, while for high volume, time-series workloads, they start to become more of an issue.
But, you only need the full list of values for calculating a percentile if you want exact percentiles. With relatively large datasets, you can often accept some accuracy tradeoffs to avoid running into any of these issues.
The problems above, and the recognition of the tradeoffs involved in weighing whether to use averages or percentiles, led to the development of multiple algorithms to approximate percentiles in high volume systems. Most percentile approximation approaches involve some sort of modified histogram to represent the overall shape of the data more compactly, while still capturing much of the shape of the distribution.
As we were designing hyperfunctions, we thought about how we could capture the benefits of percentiles (e.g., robustness to outliers, better correspondence with real-world impacts) while avoiding some of the pitfalls that come with calculating exact percentiles (above).
Percentile approximations seemed like the right fit for working with large, time-series datasets.
The result is a whole family of percentile approximation hyperfunctions, built into TimescaleDB. The simplest way to call them is to use the percentile_agg aggregate along with the approx_percentile accessor.
This query calculates approximate 10th, 50th, and 90th percentiles:
SELECT
approx_percentile(0.1, percentile_agg(response_time)) as p10,
approx_percentile(0.5, percentile_agg(response_time)) as p50,
approx_percentile(0.9, percentile_agg(response_time)) as p90
FROM responses;
(If you’d like to learn more about aggregates, accessors, and two-step aggregation design patterns, check out our primer on PostgreSQL two-step aggregation.)
These percentile approximations have many benefits when compared to the normal PostgreSQL exact percentiles, especially when used for large data sets.
Memory footprint
When calculating percentiles over large data sets, our percentile approximations limit the memory footprint (or need to spill to disk, as described above).
Standard percentiles create memory pressure since they build up as much of the data set in memory as possible...and then slow down when forced to spill to disk.
Conversely, hyperfunctions’ percentile approximations have fixed size representations based on the number of buckets in their modified histograms, so they limit the amount of memory required to calculate them.
Parallelization in single and multi-node TimescaleDB
All of our percentile approximation algorithms are parallelizable, so they can be computed using multiple workers in a single node; this can provide significant speedups because ordered-set aggregates like percentile_disc are not parallelizable in PostgreSQL.
Parallelizability provides a speedup in single node setups of TimescaleDB – and this can be even more pronounced in multi-node TimescaleDB setups.
Why? To calculate a percentile in multi-node TimescaleDB using the percentile_disc ordered-set aggregate (the standard way you would do this without our approximation hyperfunctions), you must send each value back from the data node to the access node, sort the data, and then provide an output.
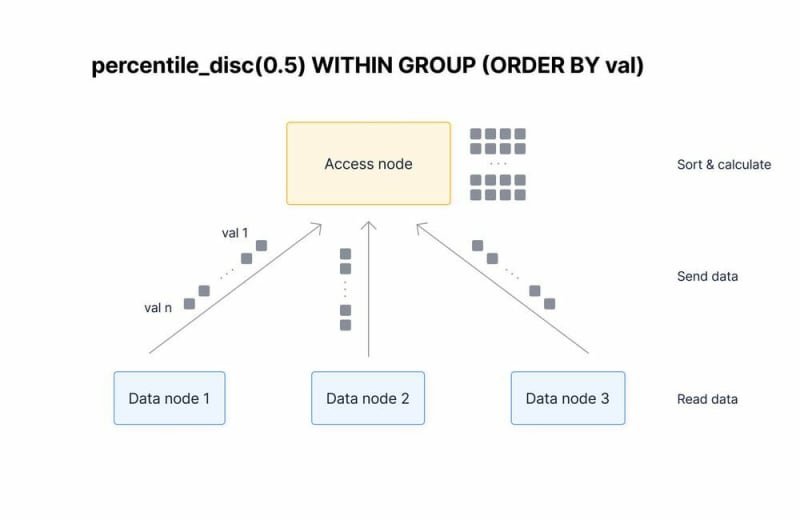
The “standard” way is very, very costly because all of the data needs to get sent to the access node over the network from each data node, which is slow and expensive.
Even after the access node gets the data, it still needs to sort and calculate the percentile over all that data before returning a result to the user. (Caveat: there is the possibility that each data node could sort separately, and the access node would just perform a merge sort. But, this wouldn’t negate the need for sending all the data over the network, which is the most costly step.)
With approximate percentile hyperfunctions, much more of the work can be pushed down to the data node. Partial approximate percentiles can be computed on each data node, and a fixed size data structure returned over the network.
Once each data node calculates its partial data structure, the access node combines these structures, calculates the approximate percentile, and returns the result to the user.
This means that more work can be done on the data nodes and, most importantly, far, far less data has to be passed over the network. With large datasets, this can result in orders of magnitude less time spent on these calculations.

Materialization in continuous aggregates
TimescaleDB includes a feature called continuous aggregates, designed to make queries on very large datasets run faster.
TimescaleDB continuous aggregates continuously and incrementally store the results of an aggregation query in the background, so when you run the query, only the data that has changed needs to be computed, not the entire dataset.
Unfortunately, exact percentiles using percentile_disc cannot be stored in continuous aggregates because they cannot be broken down into a partial form, and would instead require storing the entire dataset inside the aggregate.
We designed our percentile approximation algorithms to be usable with continuous aggregates. They have fixed-size partial representations that can be stored and re-aggregated inside of continuous aggregates.
This is a huge advantage compared to exact percentiles because now you can do things like baselining and alerting on longer periods, without having to re-calculate from scratch every time.
Let’s go back to our API response time example and imagine we want to identify recent outliers to investigate potential problems.
One way to do that would be to look at everything that is, say, above the 99th percentile in the previous hour.
As a reminder, we have a table:
CREATE TABLE responses(
ts timestamptz,
response_time DOUBLE PRECISION);
SELECT create_hypertable('responses', 'ts'); -- make it a hypertable so we can make continuous aggs
First, we’ll create a one hour aggregation:
CREATE MATERIALIZED VIEW responses_1h_agg
WITH (timescaledb.continuous)
AS SELECT
time_bucket('1 hour'::interval, ts) as bucket,
percentile_agg(response_time)
FROM responses
GROUP BY time_bucket('1 hour'::interval, ts);
Note that we don’t perform the accessor function in the continuous aggregate; we just perform the aggregation function.
Now, we can find the data in the last 30s greater than the 99th percentile like so:
SELECT * FROM responses
WHERE ts >= now()-'30s'::interval
AND response_time > (
SELECT approx_percentile(0.99, percentile_agg)
FROM responses_1h_agg
WHERE bucket = time_bucket('1 hour'::interval, now()-'1 hour'::interval)
);
At the ad analytics company, we had a lot of users, so we’d have tens or hundreds of thousands of API calls every hour.
By default, we have 200 buckets in our representation, so we’re getting a large reduction in the amount of data that we store and process by using a continuous aggregate. This means that it would speed up the response time significantly. If you don’t have as much data, you’ll want to increase the size of your buckets or decrease the fidelity of the approximation to achieve a large reduction in the data we have to process.
We mentioned that we only performed the aggregate step in the continuous aggregate view definition; we didn’t use our approx_percentile accessor function directly in the view. We do that because we want to be able to use other accessor functions and/or the rollup function, which you may remember as one of the main reasons we chose the two-step aggregate approach.
Let’s look at how that works, we can create a daily rollup and get the 99th percentile like this:
SELECT
time_bucket('1 day', bucket),
approx_percentile(0.99, rollup(percentile_agg)) as p_99_daily
FROM responses_1h_agg
GROUP BY 1;
We could even use the approx_percentile_rank accessor function, which tells you what percentile a value would fall into.
Percentile rank is the inverse of the percentile function; in other words, if normally you ask, what is the value of nth percentile? The answer is a value.
With percentile rank, you ask what percentile would this value be in? The answer is a percentile.
So, using approx_percentile_rank allows us to see where the values that arrived in the last 5 minutes rank compared to values in the last day:
WITH last_day as (SELECT
time_bucket('1 day', bucket),
rollup(percentile_agg) as pct_daily
FROM foo_1h_agg
WHERE bucket >= time_bucket('1 day', now()-'1 day'::interval)
GROUP BY 1)
SELECT approx_percentile_rank(response_time, pct_daily) as pct_rank_in_day
FROM responses, last_day
WHERE foo.ts >= now()-'5 minutes'::interval;
This is another way continuous aggregates can be valuable.
We performed a rollup over a day, which just combined 24 partial states, rather than performing a full calculation over 24 hours of data with millions of data points.
We then used the rollup to see how that impacted just the last few minutes of data, giving us insight into how the last few minutes compare to the last 24 hours. These are just a few examples of how the percentile approximation hyperfunctions can give us some pretty nifty results and allow us to perform complex analysis relatively simply.
Percentile approximation deep dive: approximation methods, how they work, and how to choose
Some of you may be wondering how TimescaleDB hyperfunctions’ underlying algorithms work, so let’s dive in! (For those of you who don’t want to get into the weeds, feel free to skip over this bit.)
Approximation methods and how they work
We implemented two different percentile approximation algorithms as TimescaleDB hyperfunctions: UDDSketch and T-Digest. Each is useful in different scenarios, but first, let’s understand some of the basics of how they work.
Both use a modified histogram to approximate the shape of a distribution. A histogram buckets nearby values into a group and tracks their frequency.
You often see a histogram plotted like so:

If you compare this to the frequency curve we showed above, you can see how this could provide a reasonable approximation of the API response time vs frequency response. Essentially, a histogram has a series of bucket boundaries and a count of the number of values that fall within each bucket.
To calculate the approximate percentile for, say, the 20th percentile, you first consider the fraction of your total data that would represent it. For our 20th percentile, that would be 0.2 * total_points.
Once you have that value, you can then sum the frequencies in each bucket, left to right, to find at which bucket you get the value closest to 0.2 * total_points.
You can even interpolate between buckets to get more exact approximations when the bucket spans a percentile of interest.
When you think of a histogram, you may think of one that looks like the one above, where the buckets are all the same width.
But choosing the bucket width, especially for widely varying data, can get very difficult or lead you to store a lot of extra data.
In our API response time example, we could have data spanning from tens of milliseconds up to ten seconds or hundreds of seconds.
This means that the right bucket size for a good approximation of the 1st percentile, e.g., 2ms, would be WAY smaller than necessary for a good approximation of the 99th percentile.
This is why most percentile approximation algorithms use a modified histogram with a variable bucket width.
For instance, the UDDSketch algorithm uses logarithmically sized buckets, which might look something like this:

The designers of UDDSketch used a logarithmic bucket size like this because what they care about is the relative error.
For reference, absolute error is defined as the difference between the actual and the approximated value:
To get relative error, you divide the absolute error by the value:
If we had a constant absolute error, we might run into a situation like the following:
We ask for the 99th percentile, and the algorithm tells us it’s 10s +/- 100ms. Then, we ask for the 1st percentile, and the algorithm tells us it’s 10ms +/- 100ms.
The error for the 1st percentile is way too high!
If we have a constant relative error, then we’d get 10ms +/- 100 microseconds.
This is much, much more useful. (And 10s +/- 100 microseconds is probably too tight, we likely don’t really care about 100 microseconds if we’re already at 10s.)
This is why the UDDSketch algorithm uses logarithmically sized buckets, where the width of the bucket scales with the size of the underlying data. This allows the algorithm to provide constant relative error across the full range of percentiles.
As a result, you always know that the true value of the percentile will fall within some range
On the other hand, T-Digest uses buckets that are variably sized, based on where they fall in the distribution. Specifically, it uses smaller buckets at the extremes of the distribution and larger buckets in the middle.
So, it might look something like this:

This histogram structure with variable-sized buckets optimizes for different things than UDDSketch. Specifically, it takes advantage of the idea that when you’re trying to understand the distribution, you likely care more about fine distinctions between extreme values than about the middle of the range.
For example, I usually care a lot about distinguishing the 5th percentile from the 1st or the 95th from the 99th, while I don’t care as much about distinguishing between the 50th and the 55th percentile.
The distinctions in the middle are less meaningful and interesting than the distinctions at the extremes. (Caveat: the TDigest algorithm is a bit more complex than this, and this doesn’t completely capture its behavior, but we’re trying to give a general gist of what’s going on. If you want more information, we recommend this paper).
Using advanced approximation methods in TimescaleDB hyperfunctions
So far in this post, we’ve only used the general-purpose percentile_agg aggregate. It uses the UDDSketch algorithm under the hood and is a good starting point for most users.
We’ve also provided separate uddsketch and tdigest aggregates to allow for more customizability.
Each takes the number of buckets as their first argument (which determines the size of the internal data structure), and uddsketch also has an argument for the target maximum relative error.
We can use the normal approx_percentile accessor function just as we used with percentile_agg, so, we could compare median estimations like so:
SELECT
approx_percentile(0.5, uddsketch(200, 0.001, response_time)) as median_udd,
approx_percentile(0.5, tdigest(200, response_time)) as median_tdig
FROM responses;
Both of them also work with the approx_percentile_rank hyperfunction we discussed above.
If we wanted to see where 1000 would fall in our distribution, we could do something like this:
SELECT
approx_percentile_rank(1000, uddsketch(200, 0.001, response_time)) as rnk_udd,
approx_percentile_rank(1000, tdigest(200, response_time)) as rnk_tdig
FROM responses;
In addition, each of the approximations have some accessors that only work with their items based on the approximation structure.
For instance, uddsketch provides an error accessor function. This will tell you the actual guaranteed maximum relative error based on the values that the uddsketch saw.
The UDDSketch algorithm guarantees a maximum relative error, while the T-Digest algorithm does not, so error only works with uddsketch (and percentile_agg because it uses uddsketch algorithm under the hood).
This error guarantee is one of the main reasons we chose it as the default, because error guarantees are useful for determining whether you’re getting a good approximation.
Tdigest, on the other hand, provides min_val & max_val accessor functions because it biases its buckets to the extremes and can provide the exact min and max values at no extra cost. Uddsketch can’t provide that.
You can call these other accessors like so:
SELECT
approx_percentile(0.5, uddsketch(200, 0.001, response_time)) as median_udd,
error(uddsketch(200, 0.001, response_time)) as error_udd,
approx_percentile(0.5, tdigest(200, response_time)) as median_tdig,
min_val(tdigest(200, response_time)) as min,
max_val(tdigest(200, response_time)) as max
FROM responses;
As we discussed in the last post about two-step aggregates, calls to all of these aggregates are automatically deduplicated and optimized by PostgreSQL so that you can call multiple accessors with minimal extra cost.
They also both have rollup functions defined for them, so you can re-aggregate when they’re used in continuous aggregates or regular queries.
(Note: tdigest rollup can introduce some additional error or differences compared to calling the tdigest on the underlying data directly. In most cases, this should be negligible and would often be comparable to changing the order in which the underlying data was ingested.)
We’ve provided a few of the tradeoffs and differences between the algorithms here, but we have a longer discussion in the docs that can help you choose. You can also start with the default percentile_agg and then experiment with different algorithms and parameters on your data to see what works best for your application.
Wrapping it up
We’ve provided a brief overview of percentiles, how they can be more informative than more common statistical aggregates like average, why percentile approximations exist, and a little bit of how they generally work and within TimescaleDB hyperfunctions.
If you’d like to get started with the percentile approximation hyperfunctions - and many more - right away, spin up a fully managed TimescaleDB service: create an account to try it for free for 30 days. (Hyperfunctions are pre-loaded on each new database service on Timescale Cloud, so after you create a new service, you’re all set to use them).
If you prefer to manage your own database instances, you can download and install the timescaledb_toolkit extension on GitHub, after which you’ll be able to use percentile approximation and other hyperfunctions.
We believe time-series data is everywhere, and making sense of it is crucial for all manner of technical problems. We built hyperfunctions to make it easier for developers to harness the power of time-series data.
We’re always looking for feedback on what to build next and would love to know how you’re using hyperfunctions, problems you want to solve, or things you think should - or could - be simplified to make analyzing time-series data in SQL that much better. (To contribute feedback, comment on an open issue or in a discussion thread in GitHub.)
Posted on November 24, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
November 24, 2021