Don't go all-in Clean Architecture: An alternative for NestJS applications

Thiago Valentim
Posted on March 19, 2024
Introduction
Hello again, my fellow readers! Lately, I've seen many people talking about Clean Architecture, both its pros and cons, and I thought it would be worth sharing some insights and takeaways from my past experiences as a Nest Consultant. In this short(er) post, I intend to show you the dangers of blindly adopting Clean Architecture in a new or existing project and what alternatives we have to ensure high-quality standards and ease of refactoring.
If you are that anxious type of person (or just don't have enough time to read the article now), I got you. You can check out the reference repository, which contains the implementation of the alternative I propose here: An application DSL.
If you are, however, interested in the details of how "Clean Architecture" might compromise your application, keep reading - I promise to be as concise as possible. Here's the summary of what we'll cover:
- Why would we use Clean Architecture
- Pitfalls of Clean Architecture
- Creating abstractions where it matters: DSL
- Using a DSL to leverage high protection against regressions and resistance to refactorings
Let's do this.
Why Clean Architecture
Clean Architecture is a term Uncle Bob coined in his homonymous book. I won't dive into its details now, as there are many resources out there with thorough explanations. Instead, we can focus on what I consider to be its main point: Independence.
If you read through the many definitions of Clean Architecture, you'll notice they have this sense of "Independability of details" in common. The idea is to divide our software into layers, each with its own well-defined responsibility, and the more high-level layers not depending on the lower-level ones (for instance, domain layer depending on infra layer). You can see this famous depiction of said architecture:
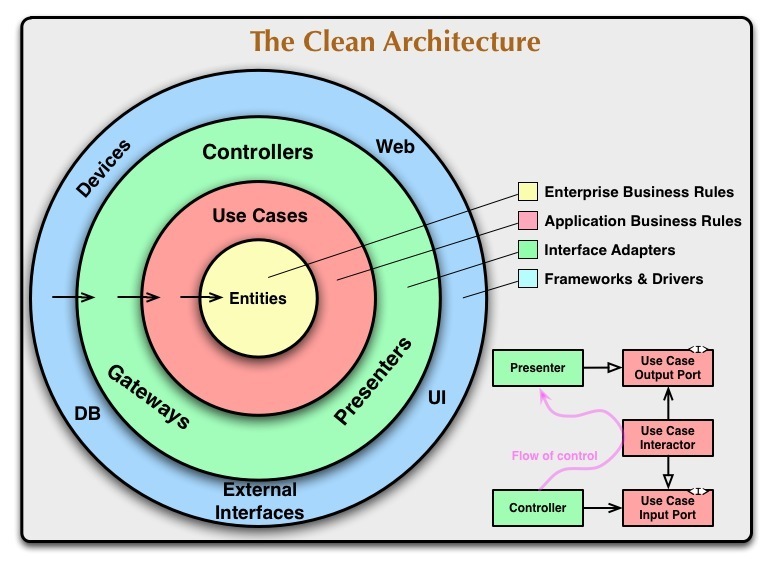
Pragmatically, we can apply this to a Nest application by creating an Interface for our services, separating the Presenter layer (Controller) from the Use Case (Services):
// user.service.interface.ts
export interface IUserService {
findAll(): Promise<User[]>;
}
// user.service.ts
import { Injectable } from '@nestjs/common';
import { IUserService } from './user.service.interface';
import { User } from './user.entity';
@Injectable()
export class UserService implements IUserService {
async findAll(): Promise<User[]> {
// Implementation to retrieve all users
}
}
// users.controller.ts
import { Controller, Get, Inject } from '@nestjs/common';
import { IUserService } from './user.service.interface';
import { User } from './user.entity';
@Controller('users')
export class UsersController {
constructor(
@Inject(UserService) private readonly userService: IUserService
) {}
@Get()
async findAll(): Promise<User[]> {
return this.userService.findAll();
}
}
In the example above, the UsersController uses the Dependency Inversion Principle (DIP) to separate the two layers we've mentioned. This approach decouples the controller and the implementation details of how the user service works. When we first see and apply this strategy, it sounds like a fantastic approach—but in reality, not always. I've been there, done that.
So, what's the problem? Isn't it great that we can easily separate and decouple these two layers?
The problem of Indirection
To be fair, indirection itself is not a problem. In fact, many complex systems are scalable precisely because of their well-thought abstractions and indirections. Recent advances in AI and LLMs are a good example of this. However, the issue arises when there is a proliferation of abstractions - which often happens when we go all-in for Clean Architecture.
Have you ever read an application's source code where you need to open dozens of tabs just to get to the gist of the business logic? This is generally an indication of excessive indirection. When we create interfaces for every layer and over-utilize DIP, we almost always get a complex-as-hell dependency tree. It hinders readability and understandability, especially for beginners.
Moreover, there's an additional problem of creating interfaces beforehand, which is nicely summarized by Vladimir Khorikov: "Abstractions are not created, they are discovered". That means good abstractions should only appear in your code base once there are at least two implementations for it. Otherwise, you'll risk creating a "pseudo-interface" only suitable for the underlying implementing class. You'll notice that pattern when you see an interface that looks like this:
interface Repository<Entity> {
find(options: {
select: keyof Entity,
where: WhereOptions<Entity>,
relations: Relations<Entity>
}): Promise<Entity>
}
This might look innocuous initially, but it uses many terms and structures of Typeorm's Repository class. That means it will grow over time to look more and more like Typeorm's Repository and will fall short when the need arises to implement it for a different library.
Alright, so, if creating these abstractions too early might be bad for our architecture, what should we do to ensure we are not relying too much on frameworks or libraries?
Acceptance Tests and DSL to the rescue
Wait, what? How are acceptance tests an alternative to a Software Architecture? A good question, indeed. The reasoning here is simple, though. Whenever someone wants to adopt Clean Arch, they almost always want to have loosely coupled layers. But why is that? Well, so that they can easily change the underlying implementation without affecting the whole application. In other words, they want Resistance to Refactoring. That's exactly where Acceptance Tests shine.
Acceptance Tests, as defined by Dave Farley, are tests that "focuses on the outcome/purpose of the software, and not the technologies or implementation details. From a back-end perspective, that means an e2e type of test that (often) sees the API as a black box. Here's an example acceptance test for a [POST] /signup endpoint in Nest:
import { Test, TestingModule } from '@nestjs/testing';
import { INestApplication } from '@nestjs/common';
import * as request from 'supertest';
import { AppModule } from './../src/app.module';
describe('Signup (e2e)', () => {
let app: INestApplication;
beforeEach(async () => {
const moduleFixture: TestingModule = await Test.createTestingModule({
imports: [AppModule],
}).compile();
app = moduleFixture.createNestApplication();
await app.init();
});
test('/signup (POST) returns 400 when email is invalid', () => {
return request(app.getHttpServer())
.post('/iam/signup')
.send({
email: 'invalid-email',
password: 'password',
passwordConfirmation: 'password',
})
.expect(400);
});
test("/signup (POST) returns 400 when password and confirmation don't match", () => {
return request(app.getHttpServer())
.post('/iam/signup')
.send({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password-different',
})
.expect(400);
});
test('/signup (POST) returns 201 and access token when email and password are valid', async () => {
return request(app.getHttpServer())
.post('/iam/signup')
.send({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
})
.expect(201)
.expect('Content-Type', /json/)
.expect((response) => {
expect(response.body.accessToken).toBeTruthy();
});
});
test('/signup (POST) returns 409 when email is in use', async () => {
await request(app.getHttpServer()).post('/iam/signup').send({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
});
return request(app.getHttpServer())
.post('/iam/signup')
.send({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
})
.expect(409);
});
});
When focusing our testing strategy on Acceptance Tests, we ensure the highest possible Resistance to Refactoring and maintain a high Protection Against Regressions (Bugs). This means we can safely change the underlying implementation details to suit our needs.
On that note, these tests still depend on the supertest library. Moreover, we often see database queries in these tests to ensure we have saved some state change, and that will also couple with the ORM or query builder (or, God Forbid, manual SQL queries) you chose, making your tests brittle.
So, the last addition to this is using a Domain-Specific Language (DSL) for tests. A DSL, as well-explained in this video, is either an external or internal language we can use to write our tests and code in business terms. That pattern has the least coupling with the implementation details and increases the test's readability. Here's what our tests look like when using it:
import { INestApplication } from '@nestjs/common';
import { Test, TestingModule } from '@nestjs/testing';
import { AppModule } from './../src/app.module';
import { DSL, dsl as createDSL } from './dsl/dsl';
describe('Signup (e2e)', () => {
let app: INestApplication;
let dsl: DSL;
beforeEach(async () => {
const moduleFixture: TestingModule = await Test.createTestingModule({
imports: [AppModule],
}).compile();
app = moduleFixture.createNestApplication();
await app.init();
dsl = createDSL(app);
});
afterEach(async () => {
await app.close();
});
test('/signup (POST) returns 400 when email is invalid', async () => {
const response = await dsl.iam.signup({
email: 'invalid-email',
password: 'password',
passwordConfirmation: 'password',
});
dsl.iam.assert(response).toBeBadRequest();
});
test("/signup (POST) returns 400 when password and confirmation don't match", async () => {
const response = await dsl.iam.signup({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password-different',
});
dsl.iam.assert(response).toBeBadRequest();
});
test('/signup (POST) returns 201 and access token when email and password are valid', async () => {
const response = await dsl.iam.signup({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
});
dsl.iam.assert(response).toBeUserSignedUpSuccessfully();
});
test('/signup (POST) returns 409 when email is in use', async () => {
await dsl.iam.signup({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
});
const response = await dsl.iam.signup({
email: 'mail@mail.com',
password: 'password',
passwordConfirmation: 'password',
});
dsl.iam.assert(response).toBeUserExistsConflict();
});
});
The dsl object above encapsulates HTTP request calls to our application, and it's divided by domains - in this case, we have Identity and Access Management (IAM). This allows us to abstract how our application is called and also how we assert that something has happened, as in the dsl.iam.assert(response).toBeUserSignedUpSuccessfully() call. The underlying implementation could be a call to a database, a check in an array, or anything else.
This DSL also encourages reusability. When testing for a sign-in feature, we can use the DSL above to sign up a user beforehand, not needing to manually insert a "user" into our database using a specific library. With that powerful tool in hand, you almost don't need any other type of test to ensure your application is always working as intended.
Conclusion
As seen above, Clean Architecture has relevant tenets: encapsulation, low coupling, and separation of concerns. That said, we also discussed how it might increase indirections, which hinder an application's maintainability. So, if you plan on applying it to a new or existing project, first consider why you want to do it. If you're looking for ease of refactoring, focusing on Acceptance Tests and creating a DSL might be a better alternative. In that case, you'll have fewer interfaces and classes to read while keeping the implementation detail loosened from the application's behavior.
I hope this article has shed some light on this controversial topic. Leave a comment if you have more thoughts on that note - it's always worth sharing our experiences 😉. See you in the next one!
Posted on March 19, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.