Writing code fast and writing fast code are two very different things. One could even say they are opposites. If you are in the habit of writing code very fast there's a great chance that it will be slow. Writing fast code is not just about choosing the fastest language, the fastest platform, the fastest libraries etc. Anyone could do that. What makes code truly fast is the little things; the loops, the conditionals, the assignments, function calls etc.
Introduction
I woke up Thursday morning, groggy, upset and very, very sleepy. My head was hurting. I had been coding all night and I had finally finished the first version of fdir; the fastest directory crawler for NodeJS. I opened my laptop after a good breakfast, splendid tea and a nice walk; ran the benchmark again: fdir was up against 13 other contenders. Always fdir would come out on top in both synchronous and asynchronous crawling. But it was not ready yet...
The First Try
Writing fast code starts from the very first line.
The purpose of fdir is simple; crawl as many directories as possible in as short a time as possible. The first version of fdir used recursion; it went something like this:
This could already beat almost everything out there. There's nothing special in it. Just some loops, recursion etc. etc. So what made it faster than everything?
The first line.
withFileTypes: true to be specific. This allowed me to skip the fs.lstatSync syscall for each item in a directory. Yup. You can imagine the speed boost.
This line must be making you jump out of your underwear. Why didn't you use path.join?!!
Because it's slow. It's much slower than just using path.sep. I benchmarked it. It's about 50% slower.
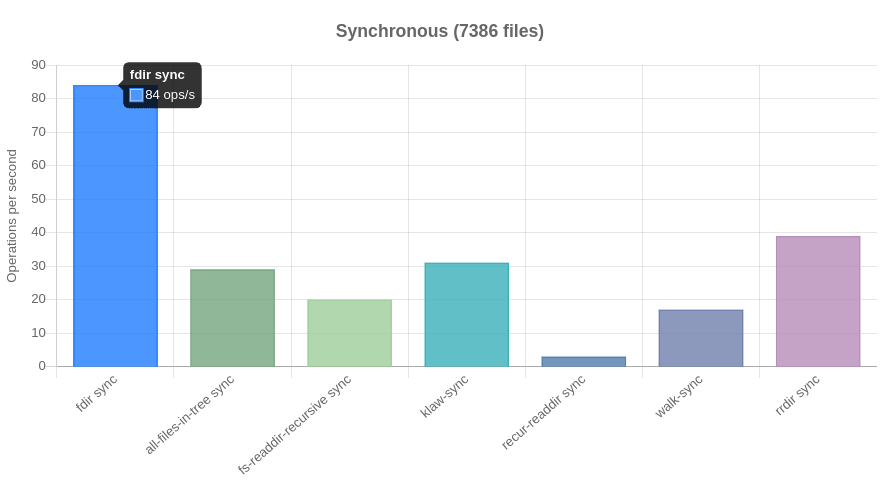
v1 Benchmark:
As you can see, only rrdir.sync comes even close to fdir and that's because it uses a similar approach.
The Defenders Arrive
Saturday evening, I was posting about fdir on Reddit. 2 hours later, the author of rrdir opened a PR to update his library to improve async performance. I was heavily refactoring fdir and adding support for Node version < 10 so his PR couldn't be merged. After an hour, though, I manually updated his library and ran the benchmarks again.
Two hours after that, the author of fs-recursive opened a PR to include his library in the benchmark. The title of the PR was: "I am fastest now". And it was. By quite the margin (50%). Of course I merged it.
And of course, I couldn't let fs-recursive take the first place. I had spent "one whole night" writing the fastest crawler. I couldn't back down now. So I rewrote the whole algorithm. From top to bottom. It removed recursion (from fdir.sync), stopped array recreation, only used a single Promise per fdir.async call etc. etc. The code now looked like this:
The code is pretty self-explanatory; we keep adding directories to the dirs array so the loop never ends until there are no more directories. But fdir.sync was already the first so I didn't really need to optimize it further but I couldn't resist. Removing the multiple array initialisation, recursion gave a good speed boost and overall made the code quite clean (imo).
The real challenge was optimizing the async version. As you all know, looping with asynchronous/callback functions is quite a PITA. So after everything this came into being:
functionasync(dir,options){returnnewPromise(function(resolve){constpaths=[];constdirs=[dir];letcursor=0;letreadCount=0;letcurrentDepth=options.maxDepth;functionwalk(){// cache the total directories before starting the walklettotal=dirs.length;for(;cursor<total;++cursor){constdir=dirs[cursor];fs.readdir(dir,readdirOpts,function(_,dirents){dirents.forEach(function(dirent){letfullPath=`${dir}${path.sep}${dirent.name}`;if(dirent.isDirectory()){dirs.push(fullPath);}else{paths.push(fullPath);}});// check if we have walked all the directories we hadif(++readCount===total){// check if we got any new onesif(dirs.length===cursor){resolve(paths);}else{// walk again if we have new directories.walk();}}});}}walk();});}
The concept is quite similar to fdir.sync but we retained recursion (although a new version of it). I couldn't find a way to reliably remove recursion.
The Results
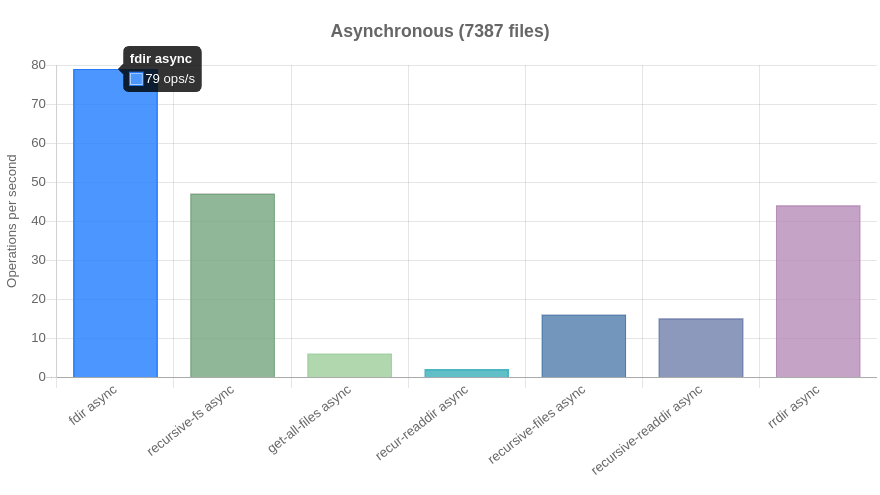
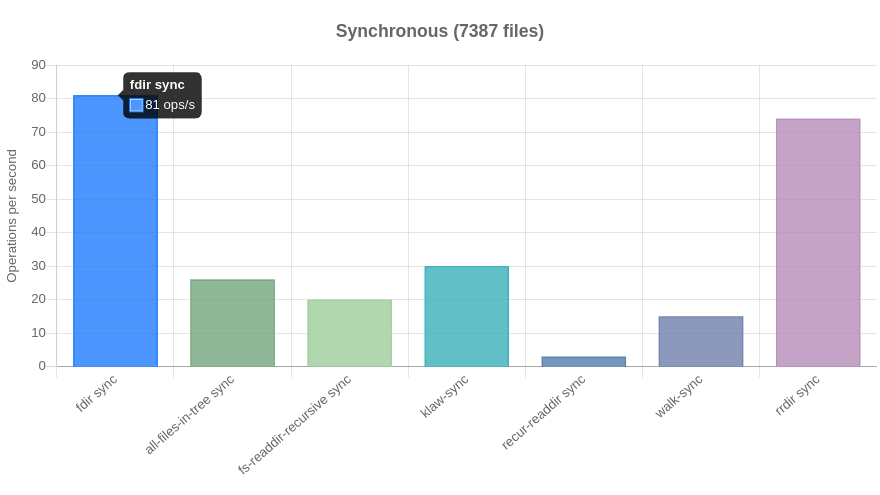
And, fdir was back on top.
Async:
Sync:
The Takeaway
The moment you have all been waiting for. The takeaways. What I learned. What I didn't. Etc. etc. However, I don't have "don't use X but Y" kind of lessons for you. I am sorry. The reason is, performance is dependent upon use-case.
Don't write code fast. You will have to rewrite it again and again. And if it's a large codebase, it will very soon become a PITA. So write it carefully, take all the precautions, do all the optimizations.
A single millisecond matters. Oftentimes, we do not add an optimization just because it adds only a millisecond. But "drop by drop a river is born" right?
NodeJS is very fast, you just have to write honest code. Don't make it complex just for the hell of it. Keep it simple, keep it fast.
Benchmark. Benchmark. Benchmark. JavaScript has a lot of ways of doing one thing, multiple loops, iterators etc. You won't know what's fastest until you benchmark. I ran benchmarks for each line of my code that could have an alternative. Remember, every millisecond matters.
But I am gonna give a few "use X not Y" lessons anyway.
Use as few conditionals as possible. Each branch adds an overhead and although the engine optimizes it, you have to be careful.
Prepare for errors beforehand. Try-catch is expensive. Be careful.
for, forEach and array.reduce are all very fast. Use whichever works for you. Actually, use them all and see which one makes your code faster.
Research the API before using it. More often than note, there's something in the API that will reduce unnecessary calls, bootstrapping, error-checks etc. Like withFileTypes: true.
Use string methods as less as possible. Actually, use strings as less as possible. Pushing a string into an array is much slower than pushing an int. (I didn't get to apply this).
So What Happens Now?
Well, I will keep benchmarking and finding ways to make it faster. I will try using WebAssembly, Workers etc etc. Innovation, my friend, innovation. Currently, fdir can crawl about 1 million files in ~900ms but I want to reduce it down to 500ms. The current code is as optimized as it can get. So let's see what I try.