The 4 Types of Activity timeouts in Temporal

swyx
Posted on June 22, 2021

One benefit of moving business logic to Temporal is how Temporal implements retries and timeouts for Activities in a standardized way. This has the effect of adding a reliability layer atop unreliable Activities and Workers, in a durable and scalable fashion. However, understanding the terminology can be a bit intimidating at first glance.
This post (together with the embedded talk) aims to give you a solid mental model on what each Activity timeout does and when to use it.
Note: You can also set Workflow timeouts and retry policies you can set. This post deals only with Activity timeouts.
Talk version: whiteboard session
You can watch this 18 minute talk where our CEO Maxim Fateev explains the 4 Types of Activity timeouts you see in Temporal.
The rest of this post summarizes the main points covered in this whiteboard session, for those who prefer a written version.
Written version: TL;DR
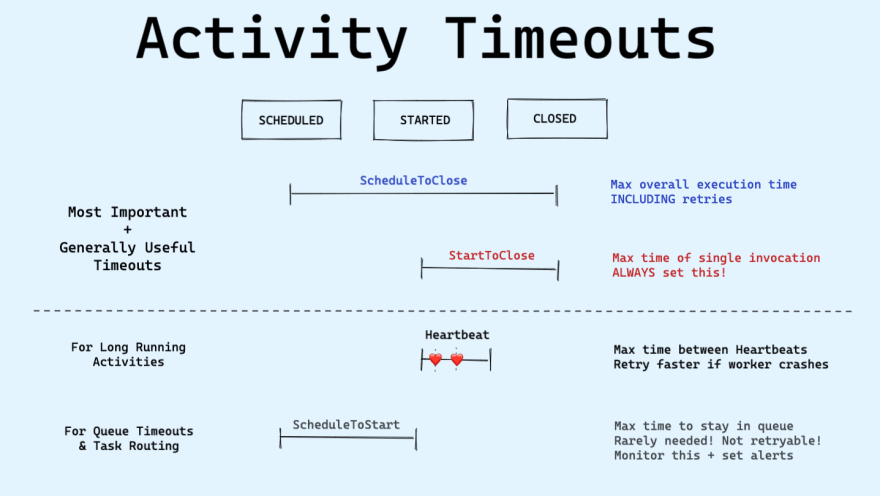
Temporal has four timeouts — two that are commonly used, and two that are useful only in specific cases:
- Schedule-To-Close: Limits the maximum execution time including retries.
- Start-To-Close: Limits the maximum execution time of a single execution. We recommend ALWAYS setting this!
- Heartbeat: Limits the maximum time between Heartbeats. For long running Activities, enables a quicker response when s Heartbeat fails to be recorded.
- Schedule-To-Start: Limits the maximum time that an Activity Task can sit in a Task Queue. Mainly to identify whether a Worker is down or for Task routing. This is rarely needed!
You can find the precise APIs in the reference documentation for each SDK: Java and Go.
Lifecycle of an Activity
To really understand how timeouts work, we should understand the typical lifecycle of an Activity as it journeys through the various parts of the system.
Step 1 - Workflow Worker
An activity SimpleActivity is first invoked inside a Workflow Worker on Task Queue sampleTaskQueue. The precise method of invocation differs by SDK, and timeouts are also specified up front as part of Activity options:
ao := workflow.ActivityOptions{
TaskQueue: "sampleTaskQueue",
ScheduleToCloseTimeout: time.Second * 500,
// ScheduleToStartTimeout: time.Second * 60, // usually not needed! see below
StartToCloseTimeout: time.Second * 60,
HeartbeatTimeout: time.Second * 10,
WaitForCancellation: false,
}
ctx = workflow.WithActivityOptions(ctx, ao)
var result string
err := workflow.ExecuteActivity(ctx, SimpleActivity, value).Get(ctx, &result)
if err != nil {
return err
}
Behind the scenes, the SDK transforms this into a ScheduleActivity Command, which is sent to the Temporal Server.
This Command includes various metadata, including the activity type (SimpleActivity), activity task queue (sampleTaskQueue), and activity ID. A RetryPolicy was not specified, so Temporal uses the default Retry Policy.
Step 2 - Temporal Server
Receiving the Command, Temporal Server adds an Activity Task to the Bar Activity Task Queue.
There is an atomic guarantee that these both happen together, to prevent race conditions.
We explained why this is important and how Temporal accomplishes this in Designing A Workflow Engine.
The Activity Execution is now in a
SCHEDULEDstate.
Step 3 - Activity Worker
An Activity Worker that has been polling the Bar Activity Task Queue picks up the Activity Task and begins execution.
The Activity Execution is now in a
STARTEDstate.
Step 4 - Temporal Server
Once the Activity Execution finishes successfully, the Activity Worker sends a CompleteActivityTask message (together with the result of the Activity Execution) to Temporal Server, which now gives control back to the Workflow Worker to continue to the next line of code and repeat the process.
The Activity Execution is now in a
CLOSEDstate.
We have just described the "Happy Path" of an Activity Execution.
However, what happens when an Activity Worker crashes midway through an execution?
Start-To-Close Timeout
We use the Start-To-Close timeout to control the maximum amount of time a single Activity Execution can take. We recommend always setting this timeout.

The classic example for why the Start-To-Close timeout is relevant, is when an Activity Task has been picked up from the Activity Task Queue (STARTED state) but the Worker crashes after that (so the Activity Execution never reaches CLOSED state).
- Without a timeout configured, Temporal would never proactively timeout this Activity Execution to initiate a retry. The Activity Execution becomes "stuck" and the end user would experience an indefinite delay of their Workflow Execution with no feedback.
- With the timeout configured, Temporal registers an
ActivityTaskTimedOutevent internally which triggers the Server to attempt a retry based on the Activity Execution'sRetryPolicy:- The Server adds the Activity Task to the Activity Task Queue again.
- The Server increments the attempt count in the Workflow Execution's mutable state.
- The Activity Task is picked up again by an Activity Worker.
- In the Temporal Server, the Start-To-Close timer is reset and will fire again if this second attempt fails.
The tricky part of setting Start-To-Close is that it needs to be set longer than the maximum possible Activity Execution, since you want to avoid premature timeouts for Activity Executions that genuinely take that long.
Practically, if an Activity Execution can take anywhere from 5 minutes to 5 hours, you need to set Start-To-Close to be longer than 5 hours.
If you have a long running Activity Execution like that, then we suggest using Heartbeat timeouts.
Schedule-To-Close Timeout
The Schedule-To-Close Timeout is used to control the overall maximum amount of time allowed for an Activity Execution, including all retries.
This timeout only makes sense if the Activity Execution has a RetryPolicy with MaximumAttempts > 1.

If you let it, Temporal will retry a failing Activity Execution for up to 10 years! (with exponential backoff up to a defined maximum interval)
Most Temporal developers will want to fine-tune retries to balance the user experience against the unreliability of the Activity Execution.
While you can control intervals between retries and maximum number of retries in the RetryPolicy, the Schedule-To-Close Timeout is the best way to control retries based on the overall time that has elapsed.
We recommend using the Schedule-To-Close Timeout to limit retries rather than tweaking the number of Maximum Attempts, because that more closely matches the desired user experience in the majority of cases.
Heartbeat Timeout
For long running Activity Executions, we recommend recording Heartbeats to create more frequent ping-backs from the Activity Worker to the Temporal Server.
Then, set a Heartbeat Timeout to fail the Activity Execution when the Temporal doesn't receive a Heartbeat from your Activity Execution at the expected frequency.

Heartbeats must be recorded from Activity Definitions (Activity code) using SDK APIs:
progress := 0
for hasWork {
// Send heartbeat message to the server.
activity.RecordHeartbeat(ctx, progress)
// Do some work.
...
progress++
}
Setting a Heartbeat Timeout enables you to retry Activity Executions more quickly (e.g. the next minute after a Heartbeat is missed) than the Start-To-Close Timeout, which must be set to as long as the longest possible Activity Execution (e.g. five hours later when we are sure the Activity Execution should have been completed).
There are some minor nuances to Heartbeats that may be of interest:
- You can freely record Heartbeats as often as you want (e.g. once a minute, or every time a loop iterates). The SDKs throttle the Heartbeats that get sent back to the Server anyway.
- If a Heartbeat Timeout isn't set and the Activity Execution tries to record a Heartbeat, nothing will be recorded since that information will never be used.
Schedule-To-Start Timeout
The Schedule-To-Start Timeout sets a limit on the amount of time that an Activity Task can sit in a Task Queue.
We recommend that most users monitor the temporal_activity_schedule_to_start_latency metric and set alerts for that as a production scaling metric, rather than setting an explicit timeout for it.

As a queue timeout, ScheduleToStart is unique in that it doesn't result in a retry — all a retry would do is pop the activity right back on to the same queue!
The Schedule-To-Start Timeout is most useful when you have a concrete plan to reroute an Activity Task to a different Task Queue, if a given Task Queue is not draining at an expected rate.
You can also reschedule a whole set of other Activity Executions or do other compensation logic based on this timeout.
This is a powerful feature for building ultra-reliable systems, however most users will not need this since you can horizontally scale the number of Workers easily.
Generally, issues with Schedule-To-Start are better addressed by scaling Activity Workers accordingly, rather than by adding timeouts.
Putting it all together - a recruiting example
We've recently found the terminology of timeouts useful even internally for our recruiting and realized that this could be a relatable analogy for most people.
As we are hiring heavily at Temporal, there is a lot of interview scheduling going on intermixed with our regular day jobs. You could model the end-to-end hiring process for a candidate as a single "Workflow" with multiple "Activities": sourcing, interviewing, making a decision, and then the offer process.
Specifically for the "Activity" of interviewing we've encountered some pain points:
- Some interviews were scheduled for 90 minutes, which we found to be way too long
- Some interviews had no-shows for any number of reasons ranging from miscommunication to Life™ getting in the way, and we were unclear on when to call an end to the interview and try to reschedule
- Sometimes a process would just drag out for weeks and weeks, leaving other candidates waiting.
To resolve this, we could think about setting some timeout policies (for clarity, none of these are real numbers):
- A Start-To-Close Timeout of 45 minutes so we don't spend too much time per interview.
- A Heartbeat Timeout of 10 minutes to see if we should cancel on no-shows.
- A Schedule-To-Close Timeout of 4 weeks to limit the length of time we spend accommodating other people's schedules vs our own.

Should we set a Schedule-To-Start timeout? You could imagine candidates sitting a queue waiting to be interviewed, with not enough interviewer "Workers" to process them. A timeout here wouldn't help much, because there's no other queue to put them on. Better to set up monitoring and alerting on Schedule-To-Start latency, and scale up workers accordingly as needed (autoscaling is currently not possible).
Posted on June 22, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related