Serverless search on AWS with Tantivy and Rust

szymon-szym
Posted on January 2, 2024
There are a lot of definitions of "serverless", but for many people, one of the main advantages of this approach is the ability to scale down to zero. In other words, we don't pay for the service if we don't use it.
AWS offers the OpenSearch service with a serverless option. Due to the nature of OpenSearch it doesn't scale down to zero and I don't believe it would be even possible.
On the other hand, I can imagine some search scenarios, which doesn't need full-blown distributed search servers (like OpenSearch, Elasticsearch, SOLR, or Quickwit).
Maybe there are internal teams in the organization, that will search through some documents only during working hours and you don't need to keep data close to real-time, so it is OK to load new documents in batches once per day over the night? It sounds like one of the possible scenarios.
I am going to use Tantivy, which is a popular search library written in Rust (it is inspired by Lucene, which powers Elastic/OpenSearch). I want to build a solution, that won't use any compute resources other than lambda functions, so I am not paying for computing power when I am not using it. Potentially this approach might be useful when we want to handle relatively small traffic for which OpenSearch cluster is an overkill.
Goal
In my dummy project, I have posts from Hacker News stored in S3 as separate files. Here is the example of the file:
{"id":"12571570","title":"Why California's Property-Tax Regime Is the Worst","url":"http://www.slate.com/blogs/moneybox/2016/09/22/california_s_proposition_13_is_bad_policy_and_here_are_some_graphs_to_show.html","num_points":1,"num_comments":0,"author":"paulsutter","created_at":"9/24/2016 16:42"}
I have 1000 files like this, and I want to index them to allow text search. At this point, I won't perform searches based on numeric values or dates, but this would be easy to implement.
The situation I am trying to simulate is searching across documents stored on S3, like orders, emails, invoices, etc.
In my case, I will only search based on titles.
Architecture
The whole code is available in the repo
By default, Tantivy creates an index on the disk. I will use an indexer lambda function to gather data from S3 and perform indexing. The result is stored on EFS attached to lambda.
Searching is handled by a separate lambda function, which reads from the same EFS and returns the list of IDs matching the query.
This approach has significant drawbacks, so it could work only for specific use cases. In general, it is tricky to implement a database in the file system and EFS is not an exclusion here.
Infrastructure
This time I am going to use AWS CDK to define infrastructure.
I need VPC because EFS requires one. Besides this, I will define the S3 bucket and lambdas.
Let's start by creating a new project.
mkdir rust-search && cd $_
cdk init --language typescript
I will add a new folder for lambdas and run cargo lambda to create projects
mkdir lambdas && cd $_
cargo lambda new searcher
I pick "yes" because my searcher function will eventually operate behind API Gateway (I won't implement this part of this post)
I create one more lambda for indexing
cargo lambda new indexer
In this case, I checked cloudwatch event as an input. For now, I am going to invoke the indexer manually, but eventually, I will consider scheduled indexing activities.
Ok, the current folder structure looks like this:
Now let's define the pieces of infrastructure that we need
In the lib folder there is a rust_search-stack.ts:
import * as ec2 from 'aws-cdk-lib/aws-ec2';
import { Construct } from 'constructs';
export class RustSearchStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// define vpc without nat gateways
const vpc = new cdk.aws_ec2.Vpc(this, 'Search VPC', {
maxAzs: 2,
natGateways: 0,
gatewayEndpoints: {
S3: {
service: ec2.GatewayVpcEndpointAwsService.S3,
}
}
})
// s3 bucket for posts
const postsBucket = new cdk.aws_s3.Bucket(this, 'BucketPosts', {
removalPolicy: cdk.RemovalPolicy.DESTROY
})
// define elastic file system to be used by lambda
const fs = new cdk.aws_efs.FileSystem(this, 'FileSystem', {
vpc,
removalPolicy: cdk.RemovalPolicy.DESTROY,
encrypted: false
})
const accessPoint = fs.addAccessPoint('SearchAccessPoint', {
path: '/lambda',
createAcl: {
ownerGid: '1001',
ownerUid: '1001',
permissions: '750'
},
posixUser: {
uid: '1001',
gid: '1001'
}
})
// ......
}
Quite straightforward staff here. So far the most important part is not to create NAT gateways, to avoid unnecessary costs. We have our lambdas in VPC, so I also need an S3 Gateway Endpoint.
The building process for lambda functions is handled by cargo lambda. After running cargo lambda build --release in the function folder binary called bootstrap is created in the target/lambda/searcher folder
cd lambdas/searcher
cargo lambda build --release
When defining lambda in the CDK I will point to this file.
After building both projects (searcher and indexer) I can define functions in my infrastructure
//.....
//lambda searcher - rust project
const searcher = new cdk.aws_lambda.Function(this, 'Searcher', {
code: cdk.aws_lambda.Code.fromAsset('./lambdas/searcher/target/lambda/searcher'),
runtime: cdk.aws_lambda.Runtime.PROVIDED_AL2,
handler: 'does_not_matter',
vpc,
filesystem: cdk.aws_lambda.FileSystem.fromEfsAccessPoint(accessPoint, '/mnt/lambda'),
environment: {
'RUST_BACKTRACE': '1',
'PATH_EFS': '/mnt/lambda'
}})
//lambda indexer - rust project
const indexer = new cdk.aws_lambda.Function(this, 'Indexer', {
code: cdk.aws_lambda.Code.fromAsset('./lambdas/indexer/target/lambda/indexer'),
runtime: cdk.aws_lambda.Runtime.PROVIDED_AL2,
handler: 'does_not_matter',
vpc,
filesystem: cdk.aws_lambda.FileSystem.fromEfsAccessPoint(accessPoint, '/mnt/lambda'),
environment: {
'RUST_BACKTRACE': '1',
'PATH_EFS': '/mnt/lambda',
'POSTS_BUCKET_NAME': postsBucket.bucketName
}})
postsBucket.grantRead(indexer)
//......
Both lambdas need access to the EFS. Indexer additionally requires read access to S3 where posts are stored.
Let's build the project. In the project root folder
cdk synth
cdk bootstrap --profile <PROFILE_NAME>
In the cdk.out folder there are generated files, including the prepared template. I don't want to spend time on how CDK works under the hood, but it is amazing to see how very simple code was transformed into the template with generated subnets, security groups, IAM policies and so far and so on. I am not a huge fan of defining all those elements by myself, so I appreciate that this work is taken away from me.
Let's deploy the project.
cdk deploy --profile <PROFILE_NAME>
After a few minutes, we should have our cloud environment up and ready. However, it doesn't do much yet.
Indexing
As a first step, we need to index data to make it searchable.
I started by defining Post type inside main.rs
#[derive(Debug, Deserialize, Serialize)]
struct Post {
id: String,
title: String,
url: String,
num_points: u64,
num_comments: u64,
author: String,
created_at: String,
}
Get files from s3
I don't want to focus on this step at the moment, the full code is available in the repo. I simply listed all files in the posts folder in my bucket, downloaded them, and used serde to load them as the vector of Posts
Schema
To be able to index my data I need to define the Tantivy schema.
// ....
let mut schema_builder = Schema::builder();
schema_builder.add_text_field("id", TEXT | STORED);
schema_builder.add_text_field("author", TEXT | STORED);
schema_builder.add_text_field("title", TEXT );
schema_builder.add_u64_field("num_points", INDEXED | STORED);
schema_builder.add_u64_field("num_comments", INDEXED | STORED);
schema_builder.add_text_field("created_at", TEXT );
let schema = schema_builder.build();
Some fields will be returned as a result of the search, others are used only for indexing.
Based on the schema I prepared fields to be used by the indexer
let id = schema.get_field("id").unwrap();
let author = schema.get_field("author").unwrap();
let title = schema.get_field("title").unwrap();
let num_points = schema.get_field("num_points").unwrap();
let num_comments = schema.get_field("num_comments").unwrap();
let created_at = schema.get_field("created_at").unwrap();
And created indexer
let index_path = std::env::var("PATH_EFS")? + "/hacker-news-index";
let index =
match Index::create_in_dir(&index_path, schema.clone()) {
Ok(index) => index,
Err(_) => Index::open_in_dir(&index_path)?,
};
let mut index_writer = index.writer(50_000_000)?;
Because the whole idea is to create an index on the disk, I needed to get the path to the mounted EFS folder. For the next invocations, the index might be there already, so I open it if it is present.
I assigned 50mB memory to the indexer.
Now let's index each Post. Tantivy provides an ergonomic way to add documents using macro.
posts.iter().for_each(|post| {
_ = index_writer.add_document(doc!(
id => post.id.to_string(),
author => post.author.to_string(),
title => post.title.to_string(),
num_points => post.num_points,
num_comments => post.num_comments,
created_at => post.created_at.to_string(),
))
});
index_writer.commit()?;
println!("index stored: {:?}", index_path);
I run the function using the cloud watch event template from lambda's testing tab in the console. It took around 10 seconds to get 1000 files and index them. According to docs, indexing English Wikipedia on the local machine might take around ~10 minutes, which is pretty fast if you ask me.
Ok, now let's create searcher lambda and see how fast we can search among files.
Search
In the lambdas/searcher/src/main.rs I open the index and pass it to the handler
#[tokio::main]
async fn main() -> Result<(), Error> {
// index
let index_path = std::env::var("PATH_EFS")?;
let index = Index::open_in_dir(&index_path)?;
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
// disable printing the name of the module in every log line.
.with_target(false)
// disabling time is handy because CloudWatch will add the ingestion time.
.without_time()
.init();
run(service_fn(|ev| function_handler(ev, &index))).await
}
In the function handler, I take q from string params
async fn function_handler(event: Request, index: &Index) -> Result<Response<Body>, Error> {
// Extract some useful information from the request
let query_input = event
.query_string_parameters_ref()
.and_then(|params| params.first("q"))
.unwrap();
tracing::info!("query input: {}", query_input);
//...
Now, just like in the indexer, I define a schema to be used. This step is common between two lambdas so I will eventually extract it to a separate module and reuse it, but for now, I just copy it
//...
// schema builder
let mut schema_builder = Schema::builder();
schema_builder.add_text_field("id", TEXT | STORED);
schema_builder.add_text_field("author", TEXT | STORED);
schema_builder.add_text_field("title", TEXT);
schema_builder.add_u64_field("num_points", INDEXED | STORED);
schema_builder.add_u64_field("num_comments", INDEXED | STORED);
schema_builder.add_text_field("created_at", TEXT);
let schema = schema_builder.build();
let title = schema.get_field("title").unwrap();
//...
Once the index is opened I need to create a reader, searcher, and query parser. In my case, I am querying only through the title field, but I could add more fields to the query parser.
//...
let reader = index.reader_builder().try_into()?;
let searcher = reader.searcher();
let query_parser = QueryParser::for_index(&index, vec![title]);
//...
Now I can go and search. I used the TopDocs helper to get the top 3 results. It returns a vector of Document, which I would map to the vector of Option<&str> so I can serialize it for the response
// ...
let docs = top_docs
.iter()
.map(|(_, doc_address)| {
let doc_address = doc_address.to_owned();
searcher.doc(doc_address).unwrap()
})
.collect::<Vec<_>>();
let ids = docs
.iter()
.map(|doc| {
doc
.get_first(schema.get_field("id").unwrap())
.and_then(|value| value.as_text())
})
.collect::<Vec<Option<_>>>();
let resp = Response::builder()
.status(200)
.header("content-type", "text/html")
.body(serde_json::to_string(&ids)?.into())
.map_err(Box::new)?;
Ok(resp)
It is much easier to read the code inside IDE because types are mostly inferred
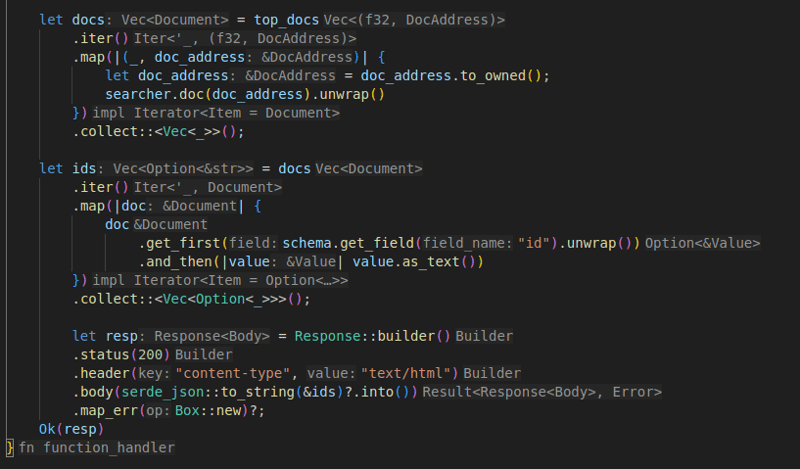
Testing
Ok, now let's see how fast my serverless search can be for my small sample of data.
I will use the test tab in the console. Let's see if there are posts related to "functional programming" in my dataset
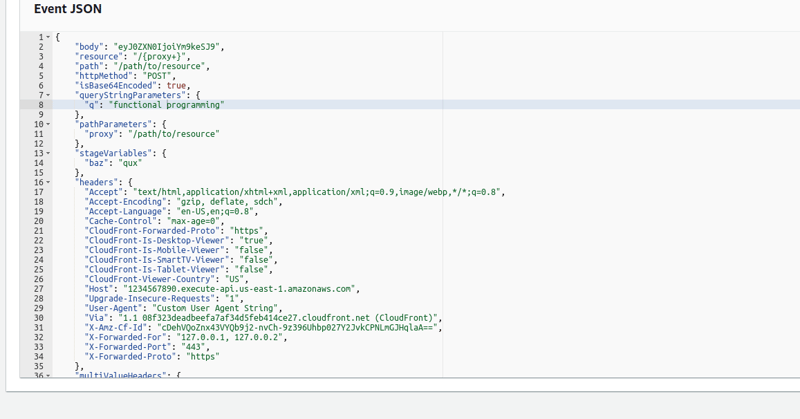
I received a response with a list of 3 IDs. Cold Lambda configured with minimal memory usually needs under 500ms for the operation
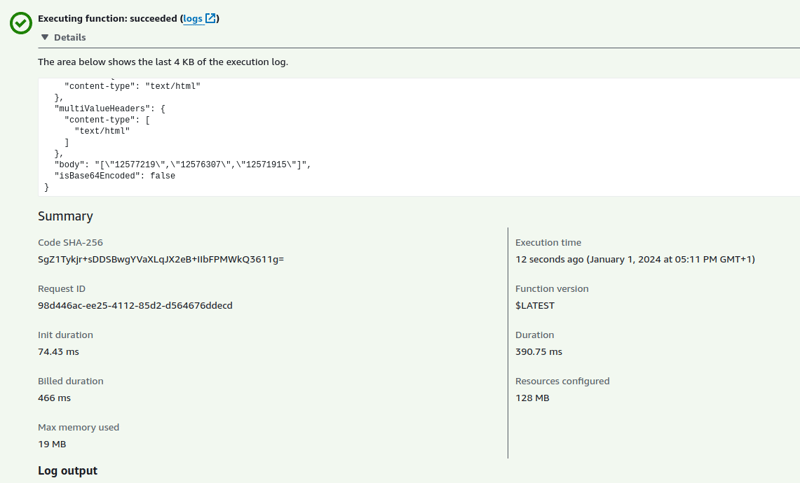
Hot one takes ~70-80ms
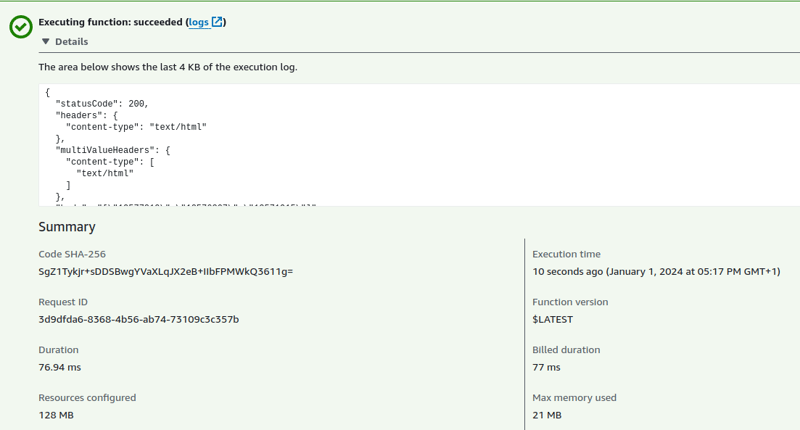
Summary
There are search use cases that don't require all functionalities of distributed search engines like OpenSearch. For them, it might make sense to look for options that can scale down to zero and help you to save some money.
Tantivy is a pretty powerful solution. Because it is written in Rust, it can be integrated directly into Rust-based lambda functions, providing very nice performance in a serverless manner.
As always, there is no silver bullet. Search is in general surprisingly complex topic. For some solutions, skipping full-blown distributed search engines like OpenSearch or Quickwit and implementing their search functionalities based on Tantivy, might be the valid option.
Posted on January 2, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

