
Suhem Parack
Posted on July 1, 2022
The Perspective API allows developers and researchers to study and analyze text to detect toxicity in it. In this tutorial, I will show you how you can detect toxicity in a Twitter user's mentions, using the Perspective API and the Twitter API v2 in Python.
Note: This is just sample code. Twitter does not own the Perspective API. It is a product of a collaborative research effort by Jigsaw and Google’s Counter Abuse Technology team. According to their website, they define 'toxicity' as a rude, disrespectful, or unreasonable comment that is likely to make someone leave a discussion.
Prerequisite
Because this tutorial uses code in Python, make sure you have Python installed on your machine. In order to get a Twitter user's mentions with the Twitter API v2, you need a Twitter developer account and your bearer token to connect to the Twitter API. Similarly, to use the Perspective API to analyze the a Twitter user's mentions, you need to apply for access to Perspective API and obtain your API key.
Applying for a Twitter developer account and getting your bearer token for the Twitter API v2
To sign up for access to the Twitter API v2, visit this page and follow instructions to sign up for essential access. You will be asked to verify your email as part of this process. Additionally, you need to have phone number registered with your account in order to use the API.
After you have created your account, you will be asked some basic questions:
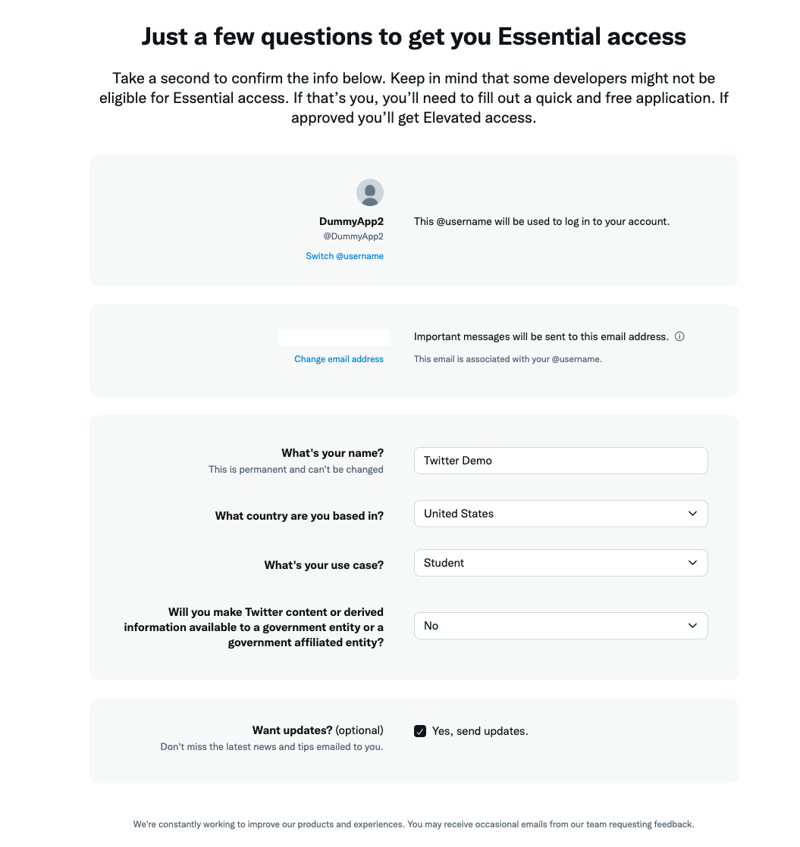
Review and agree to the developer agreement and policy

Next, you will be asked to verify your email
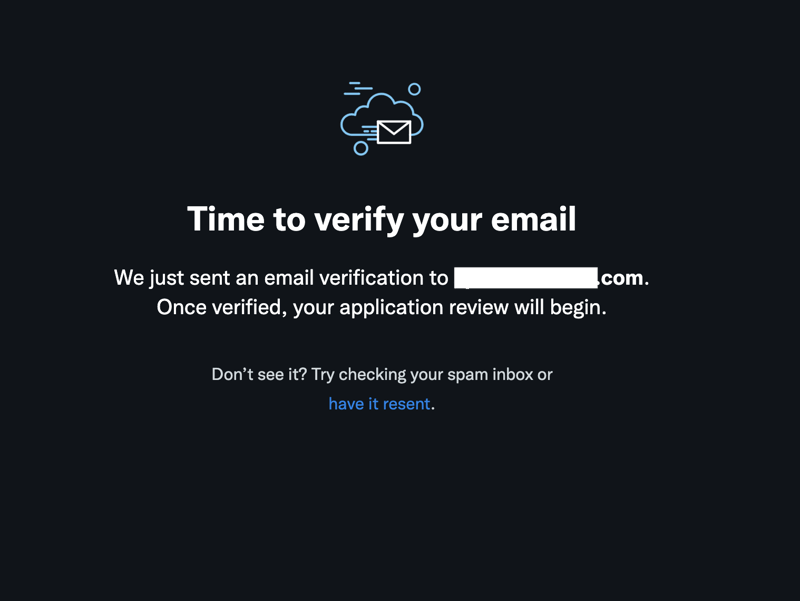
You should received an email that looks like this:
Once you click confirm, you will be directed to the developer portal. You can create an app by giving it a name
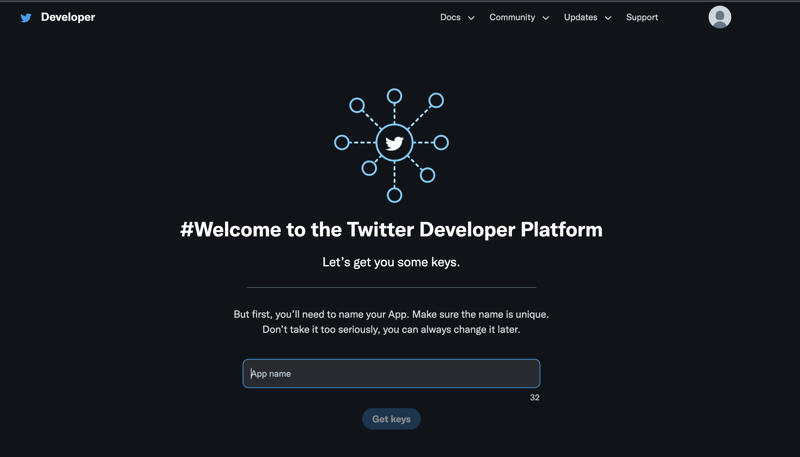
Once you click Get Keys, you will be able to see your keys and bearer token. Please keep those in a safe place, as you will be using those to connect to the Twitter API v2.

Applying for access to the Perspective API and getting your API key
For instructions on signing up for a Perspective API developer account and obtaining your API key, check out the Perspective API developer documentation
Installing the Tweepy & googleapiclient packages in Python
To work with the Twitter API v2 in Python, we will use the Tweepy package. To install it, run the following:
pip3 install tweepy
To work with the Perspective API in Python, we will use the Google API Client. To install it, run the following:
pip3 install googleapiclient
Building the function for using the Perspective API
We have a method that will take the Tweet text as input and call the Perspective API with that Tweet text. Replace the API_KEY value in this function with your own API key from Perspective.
def analyze(text):
# Replace with your own Perspective API key
API_KEY = 'PERSPECTIVE_API_KEY'
client = discovery.build(
"commentanalyzer",
"v1alpha1",
developerKey=API_KEY,
discoveryServiceUrl="https://commentanalyzer.googleapis.com/$discovery/rest?version=v1alpha1",
static_discovery=False,
)
analyze_request = {
'comment': {'text': text},
'requestedAttributes': {
'TOXICITY': {}
}
}
return client.comments().analyze(body=analyze_request).execute()
Getting a user's mentions using the Twitter API v2
In order to get the user's Twitter mentions, you will have to use the get_users_mentions method and pass it the user_id. By default, you will get 10 mentions per API call, and you can get up to 100 mentions per API call. If you want additional mentions, you can specify the number in the limit parameter below.
# Replace with the number of Tweets you'd like
limit = 25
# Replace your bearer token below
client = tweepy.Client('TWITTER_BEARER_TOKEN')
# Replace with the username of your choice
user = client.get_user(username='twitterdev')
user_id = user.data['id']
for tweet in tweepy.Paginator(client.get_users_mentions, id=user_id, max_results=25).flatten(limit=limit):
tweet_id = tweet['id']
tweet_text = tweet['text']
Passing the Tweet text to the Perspective API for analysis
We pass the Tweet text to the analyze method. The response of the analyze method is a JSON that looks like this:
{
"attributeScores": {
"TOXICITY": {
"spanScores": [
{
"begin": 0,
"end": 99,
"score": {
"value": 0.010204159,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.010204159,
"type": "PROBABILITY"
}
}
},
"languages": [
"en"
],
"detectedLanguages": [
"en"
]
}
We call the analyze method in a try and except block and are interested in the summaryScore from this response. In the except block, we print the reason for the error. In most cases in this sample, the reason will be if a Tweet is in a language that the Perspective API does not support for detecting toxicity. For a list of supported languages check out the Perspective API documentation
try:
response = analyze(tweet_text)
if 'attributeScores' in response:
if 'TOXICITY' in response['attributeScores']:
toxicity = response['attributeScores']['TOXICITY']
summary_score = toxicity['summaryScore']
toxicity_str = "Toxicity score: {}".format(summary_score['value'])
print(tweet_id)
print(tweet_text)
print(toxicity_str)
except HttpError as error:
print(error.reason)
Putting it all together
Below is the complete working script for this code sample:
import tweepy
from googleapiclient.errors import HttpError
from googleapiclient import discovery
def analyze(text):
# Replace with your own Perspective API key
API_KEY = 'PERSPECTIVE_API_KEY'
client = discovery.build(
"commentanalyzer",
"v1alpha1",
developerKey=API_KEY,
discoveryServiceUrl="https://commentanalyzer.googleapis.com/$discovery/rest?version=v1alpha1",
static_discovery=False,
)
analyze_request = {
'comment': {'text': text},
'requestedAttributes': {
'TOXICITY': {}
}
}
return client.comments().analyze(body=analyze_request).execute()
def main():
# Replace with the number of Tweets you'd like
limit = 25
# Replace your bearer token below
client = tweepy.Client('TWITTER_BEARER_TOKEN')
# Replace with the username of your choice
user = client.get_user(username='twitterdev')
user_id = user.data['id']
for tweet in tweepy.Paginator(client.get_users_mentions, id=user_id, max_results=25).flatten(limit=limit):
tweet_id = tweet['id']
tweet_text = tweet['text']
try:
response = analyze(tweet_text)
if 'attributeScores' in response:
if 'TOXICITY' in response['attributeScores']:
toxicity = response['attributeScores']['TOXICITY']
summary_score = toxicity['summaryScore']
toxicity_str = "Toxicity score: {}".format(summary_score['value'])
print(tweet_id)
print(tweet_text)
print(toxicity_str)
except HttpError as error:
print(error.reason)
if __name__ == "__main__":
main()
That is it for the tutorial. If you have any questions or feedback about this guide, please feel free to reach out to me on Twitter!
Posted on July 1, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
