Demystifying MLOps: Week 1

totalSophie
Posted on June 18, 2023

Notes from MLOps ZoomCamp
1.1 What is MLOps
MLOps (Machine Learning Operations) refers to the practices, processes, and tools used to manage the entire lifecycle of machine learning models. It bridges the gap between data scientists, software engineers, and operations teams to ensure successful deployment and maintenance of ML models.
Key Components
- Data Management and Versioning
- Model Training and Evaluation
- Deployment and Infrastructure
- Continuous Integration and Delivery
- Monitoring and Governance
1.2 Environment Preparation
You can use an EC2 instance or your local environment
Step 1
Download and install the Anaconda distribution of Python:
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
bash Anaconda3-2022.05-Linux-x86_64.sh
Step 2
Update existing packages:
sudo apt update
Step 3
Install Docker:
sudo apt install docker.io
Step 4
Create a separate directory for the installation and get the latest release of Docker Compose:
mkdir soft
cd soft
wget https://github.com/docker/compose/releases/download/v2.18.0/docker-compose-linux-x86_64 -O docker-compose
chmod +x docker-compose
nano ~/.bashrc
Add the following line to the .bashrc file:
export PATH="${HOME}/soft:${PATH}"
Save and exit the .bashrc file, then apply the changes:
source ~/.bashrc
Step 5
Run Docker to check if it's working:
docker run hello-world
1.3 Training a ride duration prediction model
Dataset
Dataset used is 2022 NYC green taxi trip records

More information on the data is found at https://www.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf
Download the dataset
!wget https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2022-01.parquet
Imports
Import required packages
import pandas as pd
import pickle
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_extraction import DictVectorizer
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
Reading the file:
jan_data = pd.read_parquet("./data/green_tripdata_2022-01.parquet")
jan_data.head()
| VendorID | lpep_pickup_datetime | lpep_dropoff_datetime | store_and_fwd_flag | RatecodeID | PULocationID | DOLocationID | passenger_count | trip_distance | fare_amount | extra | mta_tax | tip_amount | tolls_amount | ehail_fee | improvement_surcharge | total_amount | payment_type | trip_type | congestion_surcharge | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2022-01-01 00:14:21 | 2022-01-01 00:15:33 | N | 1 | 42 | 42 | 1 | 0.44 | 3.5 | 0.5 | 0.5 | 0 | 0 | 0.3 | 4.8 | 2 | 1 | 0 | |
| 1 | 1 | 2022-01-01 00:20:55 | 2022-01-01 00:29:38 | N | 1 | 116 | 41 | 1 | 2.1 | 9.5 | 0.5 | 0.5 | 0 | 0 | 0.3 | 10.8 | 2 | 1 | 0 | |
| 2 | 1 | 2022-01-01 00:57:02 | 2022-01-01 01:13:14 | N | 1 | 41 | 140 | 1 | 3.7 | 14.5 | 3.25 | 0.5 | 4.6 | 0 | 0.3 | 23.15 | 1 | 1 | 2.75 | |
| 3 | 2 | 2022-01-01 00:07:42 | 2022-01-01 00:15:57 | N | 1 | 181 | 181 | 1 | 1.69 | 8 | 0.5 | 0.5 | 0 | 0 | 0.3 | 9.3 | 2 | 1 | 0 | |
| 4 | 2 | 2022-01-01 00:07:50 | 2022-01-01 00:28:52 | N | 1 | 33 | 170 | 1 | 6.26 | 22 | 0.5 | 0.5 | 5.21 | 0 | 0.3 | 31.26 | 1 | 1 | 2.75 |
jan_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 62495 entries, 0 to 62494
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 VendorID 62495 non-null int64
1 lpep_pickup_datetime 62495 non-null datetime64[ns]
2 lpep_dropoff_datetime 62495 non-null datetime64[ns]
3 store_and_fwd_flag 56200 non-null object
4 RatecodeID 56200 non-null float64
5 PULocationID 62495 non-null int64
6 DOLocationID 62495 non-null int64
7 passenger_count 56200 non-null float64
8 trip_distance 62495 non-null float64
9 fare_amount 62495 non-null float64
10 extra 62495 non-null float64
11 mta_tax 62495 non-null float64
12 tip_amount 62495 non-null float64
13 tolls_amount 62495 non-null float64
14 ehail_fee 0 non-null object
15 improvement_surcharge 62495 non-null float64
16 total_amount 62495 non-null float64
17 payment_type 56200 non-null float64
18 trip_type 56200 non-null float64
19 congestion_surcharge 56200 non-null float64
dtypes: datetime64[ns](2), float64(13), int64(3), object(2)
memory usage: 9.5+ MB
Calculate duration of trip from dropoff and pickup times
jan_dropoff = pd.to_datetime(jan_data["lpep_dropoff_datetime"])
jan_pickup = pd.to_datetime(jan_data["lpep_pickup_datetime"])
jan_data["duration"] = jan_dropoff - jan_pickup
# Convert the values to minutes
jan_data["duration"] = jan_data.duration.apply(lambda td: td.total_seconds()/60)
Check the distribution of the duration
jan_data.duration.describe(percentiles=[0.95, 0.98, 0.99])
count 62495.000000
mean 19.019387
std 78.215732
min 0.000000
50% 11.583333
95% 35.438333
98% 49.722667
99% 68.453000
max 1439.466667
Name: duration, dtype: float64
sns.distplot(jan_data.duration)
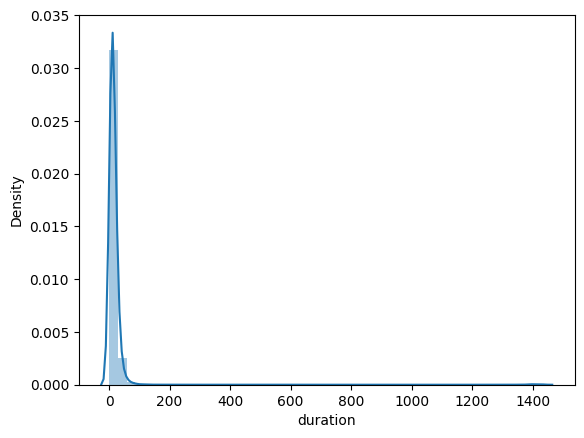
We can see the data is skewed due to the presence of outliers
Keeping only the records with the duration between 1 and 70 minutes
jan_data = jan_data[(jan_data.duration >= 1) & (jan_data.duration <= 60)]
One Hot Encoding
Using Dictionary Vectorizer for One Hot Encoding
Our categorical values that I will consider are the pickup and dropoff locations
categorical = ["PULocationID", "DOLocationID"]
numerical = ["trip_distance"]
Convert the column type to string from integers
jan_data.loc[:, categorical] = jan_data[categorical].astype(str)
# Change our values to dictionaries
train_jan_data = jan_data[categorical + numerical].to_dict(orient='records')
dv = DictVectorizer()
X_train_jan = dv.fit_transform(train_jan_data)
# Convert the feature matrix to an array
fm_array = X_train_jan.toarray()
# Get the dimensionality of the feature matrix
fm_array.shape
(59837, 471)
Python function that would do the above steps
Custom function to read and preprocess the data
def read_dataframe(filename):
# Read the parquet file
df = pd.read_parquet(filename)
# Calculate the duration
df_dropoff = pd.to_datetime(df["lpep_dropoff_datetime"])
df_pickup = pd.to_datetime(df["lpep_pickup_datetime"])
df["duration"] = df_dropoff - df_pickup
# Remove outliers
df["duration"] = df.duration.apply(lambda td: td.total_seconds()/60)
df = df[(jan_data.duration >= 1) & (df.duration <= 60)]
# Preparation for OneHotEncoding using DictVectorizer
categorical = ["PULocationID", "DOLocationID"]
df[categorical] = df[categorical].astype(str)
return df
Fitting Linear Regression Model
# Using January data as train and Feb as Validation
df_train = read_dataframe("./data/green_tripdata_2022-01.parquet")
df_val = read_dataframe("./data/green_tripdata_2022-02.parquet")
dv = DictVectorizer()
categorical = ["PULocationID", "DOLocationID"]
numerical = ["trip_distance"]
train_dicts= df_train[categorical + numerical].to_dict(orient='records')
X_train = dv.fit_transform(train_dicts)
val_dicts= df_val[categorical + numerical].to_dict(orient='records')
X_val = dv.transform(val_dicts)
target = 'duration'
y_train = df_train[target].values
y_val = df_val[target].values
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_val)
mean_squared_error(y_val, y_pred, squared=False)
8.364575685718151
Try other models like lasso and Ridge
Save the model
with open('models/lin_reg.bin', 'wb') as f_out:
pickle.dump((dv, lr), f_out)

Cover Photo by Alina Grubnyak on Unsplash
Posted on June 18, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

December 8, 2022