Understanding Apache Spark and Hadoop Jobs

sipsdaoracle
Posted on February 20, 2024

In the fast-changing world of technology, where new tools and concepts pop up constantly, understanding terms like Spark and Hadoop can feel overwhelming. Even after trying to research them online, it's easy to feel lost in the details. That's why I decided to dive into the world of Apache Spark and Hadoop jobs. I created this blog to help beginners like myself grasp what they're all about and how they're used in real-world scenarios.
Introduction:
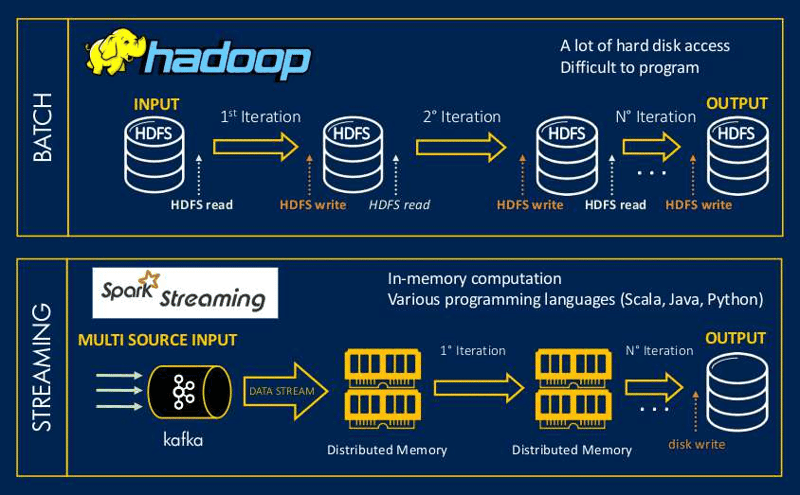
Apache Spark and Hadoop stand out as two powerhouse tools for efficiently managing massive datasets. Both Apache Spark and Hadoop are open-source frameworks meticulously engineered to distribute and process data across clusters of computers, providing scalable solutions to address the complexities associated with big data.
Apache Spark excels in in-memory processing and real-time analytics, while Hadoop, with its distributed file system (HDFS) and MapReduce processing paradigm, specializes in batch processing and storage. In this blog, we will explore the concepts of Apache Spark and Hadoop jobs, exploring their functionalities and use cases.
Understanding Apache Spark:
Apache Spark is highly regarded for its impressive speed, flexibility, and ability to handle large amounts of data. At the core of Spark are its jobs, which serve as the fundamental components for processing data. These jobs are crucial for helping organizations gain valuable insights and drive innovation.
With its rapid processing speed and ability to handle complex analytical tasks, Spark jobs have become indispensable tools for data professionals like engineers, analysts, and scientists.
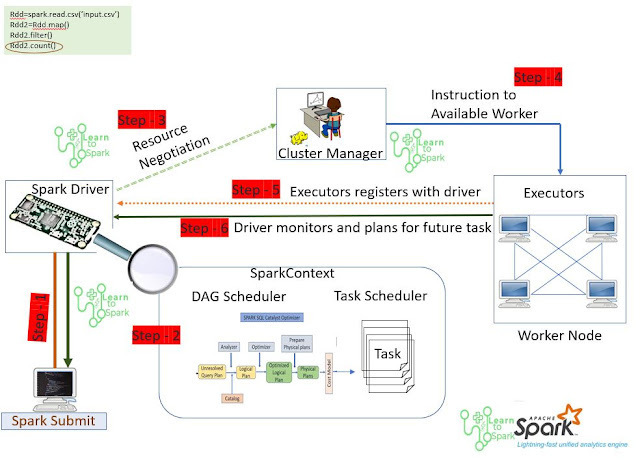
Here is an architecture diagram to illustrate Apache Spark:
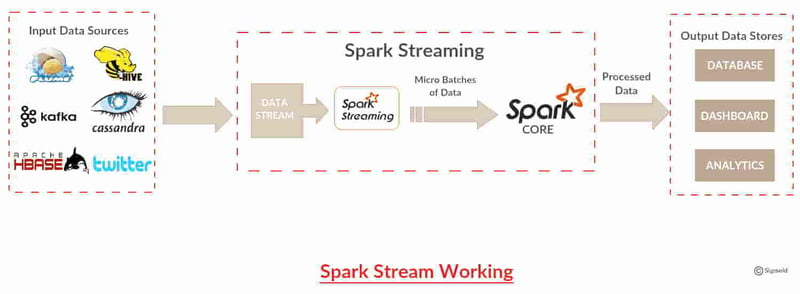
Use Case 1: Real-Time Analytics
Apache Spark is good at quickly analyzing data as it comes in, which makes it perfect for doing things in real time, like giving personalized recommendations to customers on e-commerce websites. Imagine a company wanting to do this to make their website more enjoyable for users.
Apache Spark can help by taking in all the data about what users are doing on the site as it happens, like clicks and views. Then, it can use that information to figure out what each user might like and suggest things they might want to buy. This helps make the website more fun for users and keeps them happy. Apache Spark is great at doing this fast, so businesses can keep up with all the action happening online and make sure their customers are happy.
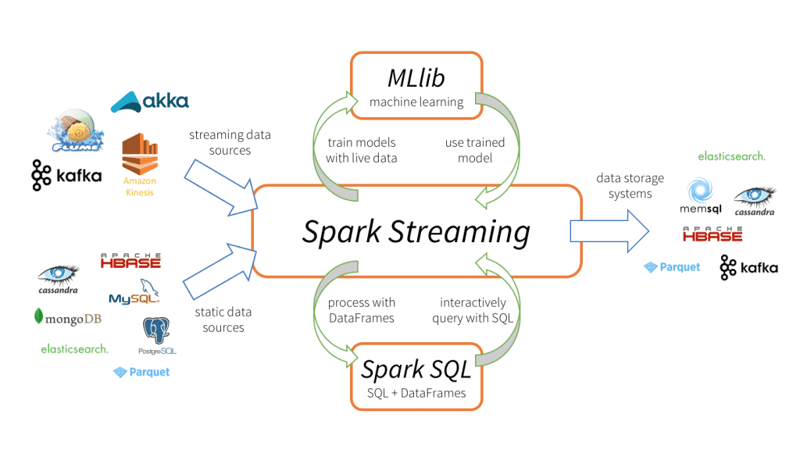
Use Case 2: Machine Learning at Scale
Spark's machine learning library, MLlib, enables scalable and distributed machine learning. Imagine a scenario where healthcare providers are faced with the daunting task of analyzing enormous volumes of patient data to foresee medical outcomes. In this scenario, Spark's machine learning library, MLlib, emerges as a lifesaver. MLlib enables healthcare professionals to tackle this challenge by employing scalable and distributed machine learning techniques.
With Spark's assistance, they can efficiently process and analyze vast datasets, training sophisticated machine learning models to predict patient outcomes with precision. This transformative capability empowers healthcare providers to make informed decisions, guiding their medical strategies based on comprehensive insights gleaned from thorough data analysis. Thus, Spark's machine learning capabilities offer beginners an accessible and powerful tool to delve into the world of data-driven decision-making in healthcare and beyond.
Understanding Hadoop Jobs
Imagine you have a gigantic pile of data, like all the information stored on the internet or every transaction made by a company over many years. It's so much data that a regular computer can't handle it all at once. That's where Hadoop comes in. Hadoop is like a super-powered tool that can manage and process this massive amount of information efficiently.
Inside Hadoop, different kinds of jobs do specific tasks like bringing in data, sorting it out, and doing analysis or machine learning on it. These jobs are what makes Hadoop so useful for working with big data.
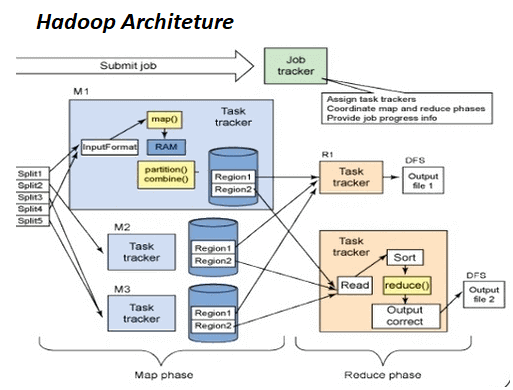
Hadoop's MapReduce
Hadoop's MapReduce is a key component of the Apache Hadoop ecosystem, designed to handle batch processing tasks efficiently. It comprises two main phases: the Map phase, where data is divided into smaller chunks and processed in parallel across multiple nodes, and the Reduce phase, where the results from the Map phase are aggregated to produce the final output. This distributed computing paradigm enables Hadoop to tackle large-scale data processing tasks with ease.
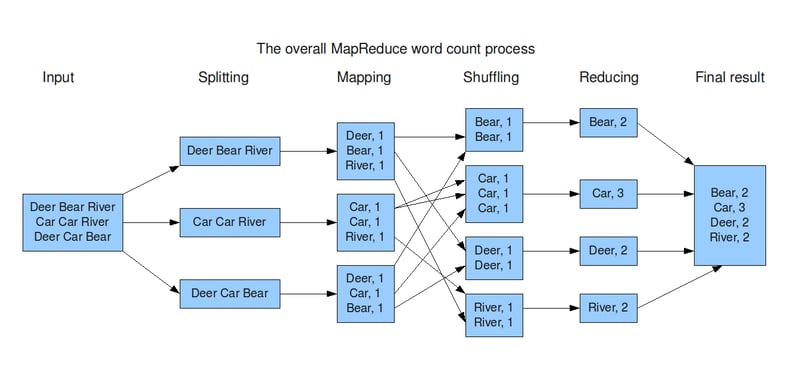
Use Case 1: Batch Processing
In the realm of big data, batch processing stands as a cornerstone for handling vast amounts of information efficiently. One of the most prominent tools in this domain is Hadoop's MapReduce, a framework renowned for its capability to process extensive datasets in a parallel and distributed manner.
To demonstrate how Hadoop's MapReduce is applied in real-world scenarios, imagine a situation where a financial organization must analyze extensive transaction data to detect fraud and ensure compliance. Utilizing Hadoop's MapReduce, this data can be processed in parallel and distributed fashion overnight, facilitating thorough analysis and identification of potentially fraudulent activities. Through the scalability and fault tolerance capabilities of Hadoop, businesses can extract valuable insights from their data while meeting regulatory standards.
Use Case 2: Data Warehousing
In scenarios where businesses need to store and analyze structured and unstructured data for reporting and analysis, Hadoop provides a cost-effective solution. Retailers, for example, can use Hadoop to store and analyze sales data, customer interactions, and social media sentiments to gain a holistic view of customer behavior and preferences.
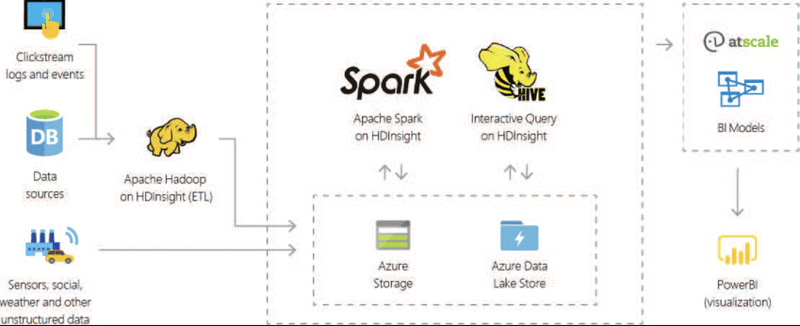
Integration of Apache Spark and Hadoop:
Apache Spark and Hadoop are two powerful tools often used separately, but they can also work well together. Spark can take advantage of Hadoop's ability to store data across many computers, called distributed storage. This means Spark can read data from and write data to Hadoop's storage system, known as HDFS. By combining Spark's fast and easy-to-use features with Hadoop's strong storage and ability to handle big batches of data at once, organizations get the best of both worlds.
Conclusion:
In the world of big data, Apache Spark and Hadoop are like superheroes for organizations. They help companies handle and understand huge amounts of data. Whether a company needs to analyze data in real time, use machine learning to learn from lots of data, process data in big batches, or store data for later use, these frameworks have tools to do it all. By learning about what Apache Spark and Hadoop can do, businesses can unlock the potential of big data to come up with new ideas and make smart choices.
Posted on February 20, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related