Improving Teuthology Scheduling: GSoC 2020 with Ceph Foundation

Shraddha Agrawal
Posted on September 9, 2020

I was selected in Google Summer of Code 2020 with the Ceph Foundation to work on Teuthology scheduling improvements.
 Extremely delighted and grateful to be selected in @gsoc under the @Ceph Foundation 🙏💖
Extremely delighted and grateful to be selected in @gsoc under the @Ceph Foundation 🙏💖
Here's to another OSS packed summer, working on improving Teuthology scheduling, with my super mentors Josh Durgin and @ojha_neha 🍷✨
Best #MayTheFourthBeWithYou yet 🔥04:49 AM - 05 May 2020




Here is what I worked on this summer.
What is Teuthology?
Ceph is a highly distributed system with active kernel development. Teuthology (referring to the study of cephalopods) is Ceph's automation framework used to schedule and run a vast majority of its integration tests and was developed due to the lack of a pre-existing system that could serve Ceph's unique requirements of testing.
Understanding the Components
The various components that enable the testing framework, Teuthology:
Job queue: A priority queue maintained by the scheduler as the pool of jobs available to run. Beanstalkd queue is used in Teuthology. Various queues are maintained for different machine type of test nodes to run the job on.
Test nodes: We have a large cluster of various types of machines that are used for running tests. They are classified under various machine types. Jobs are run on one or more of these nodes by specifying their machine types and sometimes specific test nodes when scheduling jobs.
Teuthology Scheduler: Based on the incoming request from Teuthology users, it schedules a job, pushing the job information in the queue and paddles.
Teuthology Workers: Daemons that watch a queue, take a job from it, and proceed to run it. After the job finishes execution, workers keep repeating this. There are a number of workers per queue. This enables running jobs concurrently.
All the above is managed and used inside the Sepia Lab. The tests cannot be scheduled or run locally on developers' machines. To schedule tests, developers need access to Sepia Lab
The different services that interact with Teuthology:
Paddles: A JSON API used to report back on test results and is the jobs database. It contains complete information about the jobs, including when they are scheduled, nodes they are scheduled to run on, execution time and their status.
Pulpito: Frontend for Paddles. It is used to visualize the information contained in Paddles. It can be accessed here.
Jenkins: The package builder. It is used to built packages from the specified branch for the required distro. Packages are fetched from Jenkins to run jobs.
Shaman: REST API used to update and query the build status of the packages.
FOG Project: Used to capture and deploy the required Linux distros on test nodes.
The Current Working
When Ceph developers need to test their development branches or reviewers need to test changes before merging, integration tests are scheduled using Teuthology.
Devs run a similar command in Sepia Lab to schedule a job:
Teuthology-suite -m smithi -c wip-shraddhaag-add-dispatcher \
-p 45 -s rados/cephadm/upgrade
Teuthology scheduler queries the status of the build from Shaman to check if the build is ready corresponding to the branch and repository specified. If yes, other sanity checks are done and the job is scheduled by adding it to the beanstalk priority and its information is reported to Paddles, the jobs database. At this point, users' job is done and they can see the status of the job on Pulpito, the web UI for Paddles.
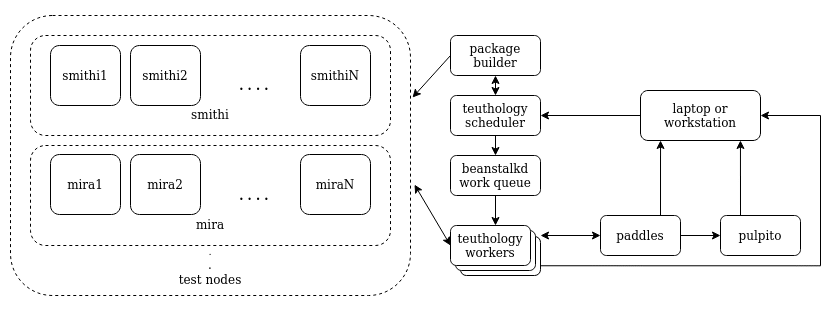
Behind the scenes, several workers are watching the queues, waiting for jobs to run. When a worker receives a job, it prepares the job and invokes Teuthology cmd, its child process, to start executing the job. The worker waits for its child process to finish execution and then moves ahead to take the next job in the queue. At a time, a worker only runs one job. There is also a maximum time limit set for a job's execution. If the execution takes longer, the worker interrupts the execution and kill its child process and reports the status of the job as 'dead'.
The child process is responsible for executing tasks described in the job's YAML files. Various tasks are specified that range from acquiring (locking) the required test nodes to run the job on, reimage these test nodes using the FOG project, run the tests, archiving the logs for further analysis and finally unlocking the test nodes (so that they can be used by other test). After executing all the tasks, the child process exits.
The Problem
The problems with the current implementation are:
- Lack of scheduling fairness
- Priority is not maintained
Lack of scheduling fairness
Some jobs aren't able to run at all due to low priority and high requirement of test nodes to execute the job. Since workers are always looking for jobs to execute without knowledge of the other jobs being executed by the rest of the workers, it often happens that a job is not executed at all because the required number of test machines are not free.
Priority is not maintained
Since jobs which are requirement heavy will be delayed execution in favor of ones that require fewer machines, priority is not maintained. Workers do not have knowledge of what jobs are being executed by other workers, so they do not wait for these jobs to finish execution first before locking machines for low priority jobs. Thus jobs are rather executed in order of available test nodes, job's requirement and its priority which isn't the ideal scenario.
Lets take an example, a job is scheduled which requires 5 machines to execute with a low priority. Since priority is low, it will be picked up much later by workers. When a worker does start its execution, it will try to lock 5 test nodes. At the same time, the other workers will be picking up jobs from queues and executing them, where they will try to lock machines required by their jobs. If these other jobs require fewer machines, they will be locked before our job locks machines, irrespective of the priority of the job. Since we have many workers per queue, they will always be looking to lock machines, chances of having 5 free machines for our worker to lock are very less. It's very likely that our job isn't able to start execution at all.
The Solution
The above problems can be solved if we have complete knowledge of the system when we are locking machines. Since execution does not need to know about the priority of the job, that can be executed independently without the entire system's knowledge. Separating the locking mechanism from the job execution such that it is done in a centrally controlled environment is key.
To achieve the above, we replaced the existing worker framework with a dispatcher.
Dispatcher
The dispatcher sits at the interface of the beanstalk queue and the workers, which are now called the job supervisors. Instead of various workers watching a queue, a single dispatcher keeps track of the queue. Instead of locking machines in the initial tasks upon execution of a job, the dispatcher locks the required number of machines and then invokes the job's execution by starting job supervisors. The dispatcher forgets about the job now and moves onto the next job in the queue.
Supervisors
Job supervisors are similar in working to workers with some key differences. While workers execute many jobs, one after the other, supervisor are job-specific. They supervise the execution of the job and then exit when it's completed. Unlike workers, they also don't have direct access to the priority queue to pull jobs from but are called with a specific job's information. They are responsible for reimaging the target test nodes and unlocking/nuking them after a job finishes executing all its tasks.
In case of job timeout, that is when a job exceeds the maximum execution time for a job, workers simply nuked target test nodes without archiving logs from these machines. This was a huge pain for developers to debug without the test logs to go through. Supervisors archive test logs from target test nodes in case of a job timeout before nuking machines.
How does it all come together?
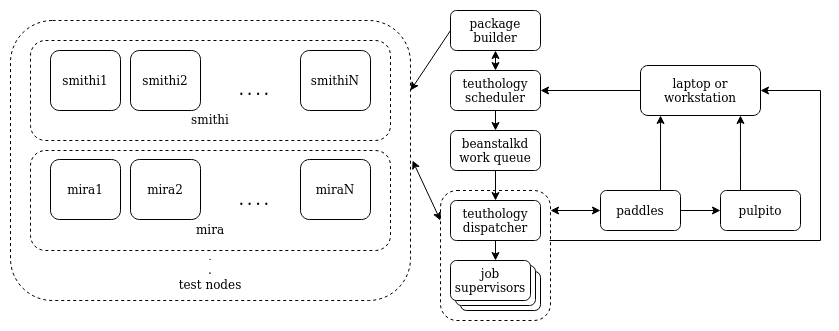
Dispatcher watches the queue, takes a job from it, waits for the required number of test nodes to be available, locks them and invokes job supervisor. The supervisor reimages the test nodes, constructs the Teuthology cmd and invokes it. Teuthology proceeds to run all the tasks and exits after the job execution is complete. At this point, the supervisor unlocks/nukes targets depending on the job status.
If the required number of test nodes are not available the dispatcher waits for them to be freed. During this time, no other job starts execution as dispatcher is busy. As other jobs finish execution and unlock nodes, the dispatcher is able to lock the required number of nodes, invoke that job's execution and move on to the next job in the queue. This ensures that jobs that have a higher requirement for test nodes to execute are not left waiting too long and at the same time maintains the priority order of the jobs.
Following PRs enable the above working:
- https://github.com/ceph/Teuthology/pull/1546
- https://github.com/ceph/ceph/pull/36738
- https://github.com/ceph/ceph/pull/36718
What lies ahead?
Same Teuthology workspace for each run.
While scheduling suites, we can specify what Teuthology branch to run the suite against. But in the middle of a run if the said branch is updated, some jobs are run using the old branch ref and some using the latest ref. This makes debugging harder since the error could be in the latest branch update which just adds onto places to look for bugs, not to mention one will only look into it if they realize in the first place that Teuthology might have updated mid-run. We want to avoid this nastiness by enabling Teuthology workspace for each run such that each job in a suite is run using the same ref.
Enable re-prioritizing jobs
We would like to add the ability to re-prioritize jobs after they are scheduled. This would be used to re-prioritize jobs, to bump them up in the priority queue after they have spend maximum waiting time in a certain priority level. This will ensure that even low priority jobs are executed eventually and not end up waiting in the queue indefinitely.
Running Teuthology locally
If you read through the blog till now, you might be wondering how does one go about setting up Teuthology locally. The simple answer is you can't, for now at least. There are a lot of pieces that need to be figured out to run Teuthology locally. But doing so will be extremely useful in shortening the development time for Teuthology.
No ride is void of challenges
There were a few instances this past summer when I felt overwhelmed.
The first hurdle was setting up the development environment. As I mentioned earlier, running a development setup for Teuthology was a big task. Recently no such drastic changes had been made to Teuthology, and so no one had deployed Teuthology for development that I could ask questions to. We were all figuring it out together. It was a good exercise and made me appreciate the extensive lengths people go to make sure their project's local development setup experience is as smooth as running a single command to have everything up and running.
I had a medical emergency in the second week of GSoC due to which I wasn't able to work for an entire week. This interruption came at a time when I was already struggling with trying to setup Teuthology. It got to me a little but my mentors were extremely supportive.
I was already done with the main aims of the project by the time we approached the last month of GSoC. Teuthology is also used in SUSE and they have some restrictions due to which we had to change the solution's implementation details entirely. On the first blush, this seemed like a challenge I won't be able to pull off. But in the end, I completed it well within the timeline and I'm happy about the change since the updated implementation is much more elegant.
Acknowledgements
I was studying the internal working of other task queues and message queues when I came across this project in GSoC while helping out a friend find a suitable project for them. The project really piqued my interest. I was elated to be selected in GSoC because I would be able to work on something I'm genuinely curious about.
I can safely say that this past summer has been an immensely gratifying learning experience. All of this has been possible only because of my rockstar mentors Neha Ojha and Josh Durgin. They not only helped me throughout the process but made sure to appreciate my work and gave me constructive feedback at every turn. I'm extremely grateful for the opportunity to learn from such talented people. Thank you to the wider Ceph community for bearing with me while I got up to speed with way things work. And last but not the least, thank you so much Kyrylo Shatskyy for helping me out in the last leg of this journey!
Thank you so much for this wonderful summer :)
Posted on September 9, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

