How to scrape Google search results with Python

hil
Posted on October 17, 2023

Learn how to quickly and effortlessly scrape Google search results using the SerpApi Python library. Bonus: export the data to a CSV file or a Database.
Google search results offer a goldmine for developers, SEO practitioners, and data scientists. Unfortunately, manually scraping this search result can be cumbersome. We'll learn how to use Python to collect data from Google efficiently. Whether working on search engine optimization, training AI models, or analyzing data patterns, this step-by-step guide will help you.
Not using Python? Read our introduction post on "How to Scrape Google Search Results"

Google search data scraper cover
How to scrape Google search results using Python?
There are at least three ways to do this:
- Custom Search JSON API by Google
- Create your DIY scraper solution
- Using SerpApi (Recommended)
1. Using Custom Search JSON API by Google.
You can use the "Google Custom Search JSON API". First, you must set up a Custom Search Engine (CSE) and get an API key from the Google Cloud Console. Once you have both, you can make HTTP requests to the API using Python's requests library or using the Google API client library for Python. By passing your search query and API key as parameters, you'll receive search results in JSON format, which you can then process as needed. Remember, the API isn't free and has usage limits, so monitor your queries to avoid unexpected costs.
2. Create your DIY scraper solution
If you're looking for a DIY solution to get Google search results in Python without relying on Google's official API, you can use web scraping tools like BeautifulSoup and requests. Here's a simple approach:
2.1. Use the requests library to fetch the HTML content of a Google search results page.
2.2. Parse the HTML using BeautifulSoup to extract data from the search results.
You might face issues like IP bans or other scraping problems. Also, Google's structure might change, causing your scraper to break. The point is that building your own Google scraper will come with many challenges.
3. Using SerpApi to make it all easy
SerpAPI provides a more structured and reliable way to obtain Google search results without directly scraping Google. SerpAPI essentially serves as a middleman, handling the complexities of scraping and providing structured JSON results. So you can save time and energy to collect data from Google without building your own Google Scraper or using other web scraping tools.
This blog post covers exactly how to scrape the Google search results in Python using SerpApi.
We'll use the new official Python library by SerpApi: serpapi-python.
That's the only tool that we need!

As a side note: You can use this library to scrape search results from other search engines, not just Google.
Normally, you'll write your DIY solution using something like BeautifulSoup, Selenium, Scrapy, Requests, etc., to scrape Google search results. You can relax now since we perform all these heavy tasks for you. So, you don't need to worry about all the problems you might've encountered while implementing your web scraping solution.
Setup
- Sign up for free at SerpApi. You can get 100 free searches per month.
- Get your SerpApi Api Key from this page.
- Create a new
.envfile, and assign a new env variable with value from API_KEY above.SERPAPI_KEY=$YOUR_SERPAPI_KEY_HERE - Install python-dotenv to read the
.envfile withpip install python-dotenv - Install SerpApi's Python library with
pip install serpapi - Create new
main.pyfile for the main program.
Your folder structure will look like this:
|_ .env
|_ main.py
Basic Google search result scraping with Python
Let's say we want to find Google search results for a keyword coffee from location Austin, Texas.
import os
import serpapi
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv('SERPAPI_KEY')
client = serpapi.Client(api_key=api_key)
result = client.search(
q="coffee",
engine="google",
location="Austin, Texas",
hl="en",
gl="us",
)
print(result)
Try to run this program with python main.py or python3 main.py from your terminal.
Feel free to change the value of theq parameterwith any keyword you want to search for.
The organic Google search results are available at result['organic_results']
Get other results
We can get all the information in Google results, not just the organic results list. For example, we can get the total_results, menu_items, local_results, related_questions, etc.
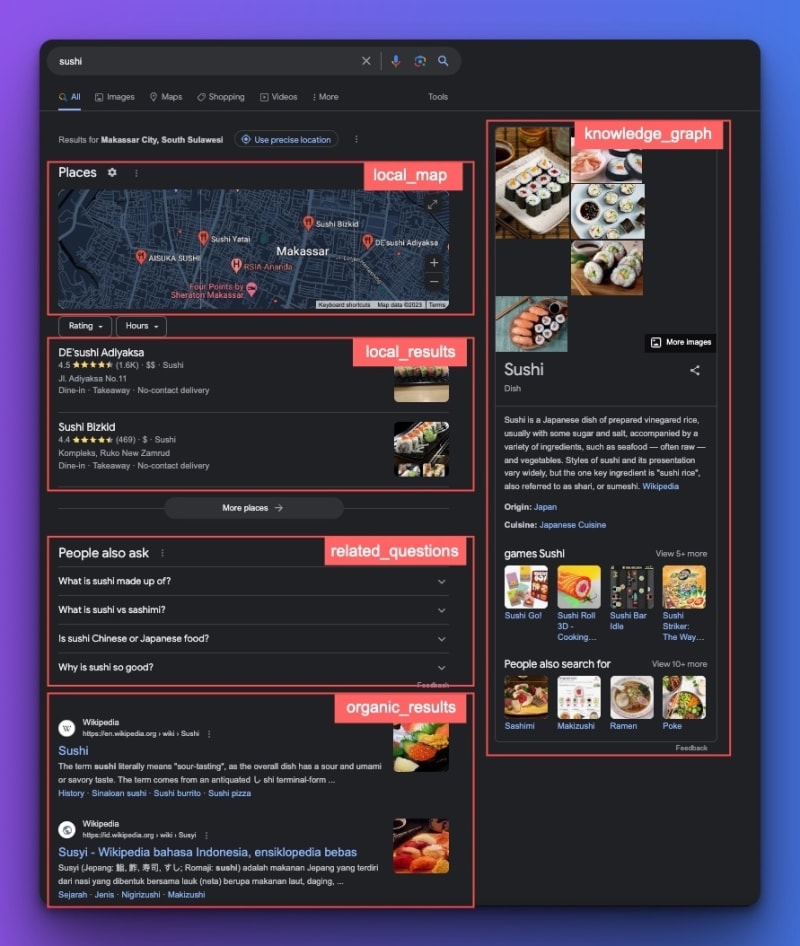
All this data available in the result we had earlier
print(result) # All information
print(result["search_information"]["total_results"]) # Get number of results available
print(result["related_questions"]) # Get all the related questions
Paginate Google search results
Based on Google Search Engine Results API documentation, we can get the second, third page, and so on, using the start and num parameter.
Start
This parameter defines the result offset. It skips the given number of results. It's used for pagination. (e.g.,
0(default) is the first page of results,10is the 2nd page of results,20is the 3rd page of results, etc.).
Num
This parameter defines the maximum number of results to return. (e.g.,
10(default) returns 10 results,40returns 40 results, and100returns 100 results).
The default amount of results is 10. It means:
- We can get the second page by adding the
start=10in the search parameter. - Third page with
start=20 - and so on.
Code sample to get the second page where we get ten results for each page.
...
result = client.search(
...
start=20
)
print(result)
Tips: If you need to fetch more than 10 results, you can use the num parameter directly. You can have up to 100 results per search. This way, getting all the 100 organic_results will only count as one search credit, compared to using pagination, which will use ten credits.
Code sample to get 100 results in one query.
result = client.search(
...
num=100
)
print(result)
You can also get the next page results with next_page() method, which is available in our new Python library.
...
result = client.search(...)
print(result)
print('------ NEXT PAGE RESULT ----')
print(result.next_page())
Export Google Scrape results to CSV
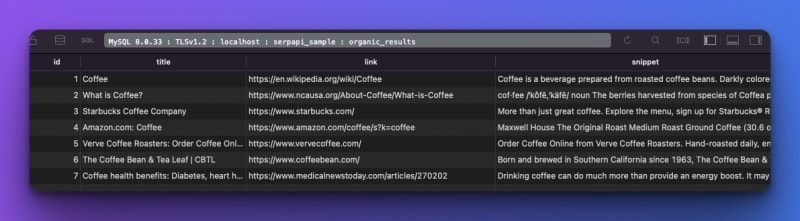
What if you need the data in csv format ? You can add the code below. This code sample shows you how to store all the organic results in the CSV file. We're saving the title, link, and snippet.
...
import csv
result = client.search(...)
organic_results = result["organic_results"]
with open('output.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# Write the headers
csv_writer.writerow(["Title", "Link", "Snippet"])
# Write the data
for result in organic_results:
csv_writer.writerow([result["title"], result["link"], result["snippet"]])
print('Done writing to CSV file.')
Now, you can view this data nicely by opening the output.csv file with Microsoft Excel or the Numbers application.

Export Google Scrape results to a Database
Now, let's learn how to save all this data in a database. We'll use mysql as an example here, but feel free to use another database engine as well. Like the previous sample, we'll store the title, link, and snippet from the organic results.
First, install the mysql-connector-python with
pip install mysql-connector-python
install MySQL connector python
Then, you can insert the JSON results into the connected database
...
import mysql.connector
result = client.search(...)
organic_results = result["organic_results"]
# Database connection configuration
db_config = {
"host": "localhost",
"user": "root",
"password": "",
"database": "database_name"
}
# Establish a database connection
connection = mysql.connector.connect(**db_config)
cursor = connection.cursor()
# Create a table for the data (if it doesn't exist)
create_table_query = """
CREATE TABLE IF NOT EXISTS organic_results (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
link TEXT NOT NULL,
snippet TEXT NOT NULL
);
"""
cursor.execute(create_table_query)
# Insert the JSON data into the database
for result in organic_results:
insert_query = "INSERT INTO organic_results (title, link, snippet) VALUES (%s, %s, %s)"
cursor.execute(insert_query, (result["title"], result["link"], result["snippet"]))
# Commit the transaction and close the connection
connection.commit()
cursor.close()
connection.close()
Faster Google search scraping with threading
What if we need to perform multiple queries? First, we'll see how to do it with a normal loop and how long it takes.
We're using time package to compare the speed between this program and the one using thread later.
....
import time
start_time = time.time()
keywords = ["Bill Gates", "Steve Jobs", "Steve Wozniak", "Linus Torvalds", "Tim Berners Lee"]
def fetch_results():
all_results = []
for keyword in keywords:
print("Making request for: " + keyword)
result = client.search(
q=keyword,
engine="google",
location="Austin, Texas",
hl="en",
gl="us"
)
all_results.extend(result.get("organic_results", []))
return all_results
results = fetch_results()
print(results)
print("--- Finished in %s seconds ---" % (time.time() - start_time))
It took around 12 seconds to finish.
Let's make this faster!
We'll need to use the threading module from Python's standard library to run the program concurrently. The basic idea is to run each API call in a separate thread so multiple calls can run concurrently.
Here's how we can adapt your program to use multithreading
...
import time
import threading
start_time = time.time()
keywords = ["Bill Gates", "Steve Jobs", "Steve Wozniak", "Linus Torvalds", "Tim Berners Lee"]
all_results = []
def fetch_results(keyword):
print("Making request for: " + keyword)
result = client.search(
q=keyword,
engine="google",
location="Austin, Texas",
hl="en",
gl="us",
no_cache=True
)
global all_results
all_results.extend(result.get("organic_results", []))
# Create and start a thread for each keyword
threads = []
for keyword in keywords:
thread = threading.Thread(target=fetch_results, args=(keyword,))
thread.start()
threads.append(thread)
# Wait for all threads to finish
for thread in threads:
thread.join()
print(all_results)
print("--- Finished in %s seconds ---" % (time.time() - start_time))
It took around 8 seconds. I expect the time gap will increase as the number of queries we need to perform grows.
That's how you can scrape Google Search results using Python.
If you're interested in scraping Google Maps, feel free to read How to scrape Google Maps places data and its reviews using Python.
Frequently asked question
Why use Python for web scraping?
Python stands out as a preferred choice for web scraping for several reasons. The vast array of libraries, such as BeautifulSoup and Scrapy, are specifically designed for web scraping tasks, streamlining the process and reducing the amount of code required. It also allows easy integration with databases and data analysis tools, making the entire data collection and analysis workflow seamless. Furthermore, Python's asynchronous capabilities can enhance the speed and efficiency of large-scale scraping tasks. All these factors combined make Python a top contender in web scraping.
Is it legal to scrape Google search results?
Web scraping's legality varies by country and the specific website's terms of service. While some websites allow scraping, others prohibit it. With that being said, You don't need to worry about the legality if you're using SerpApi to collect these search results.
"SerpApi, LLC promotes ethical scraping practices by enforcing compliance with the terms of service of search engines and websites. By handling scraping operations responsibly and abiding by the rules, SerpApi helps users avoid legal repercussions and fosters a sustainable web scraping ecosystem." - source: Safeguarding Web Scraping Activities with SerpAPi.
Posted on October 17, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related