Generative AI: Novice Guide to Transformers

Sabah Shariq
Posted on March 29, 2024
Introduction
Transformer model brings a revolutionary change in Natural Language Processing by overcoming the limitations of Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN). It was first introduced in 2017 on a paper titled "Attention Is All You Need" by Vaswani et al. It is a type of neural network capable of understanding the context of sequential data, such as sentences, by analyzing the relationships between the words.
Transformers Structure
The transformer architecture consists of two main parts: an encoder and a decoder. The encoder takes a sequence of input tokens and produces a sequence of hidden states. The decoder then takes these hidden states and produces a sequence of output tokens. The encoder and decoder are both made up of a stack of self-attention layers.
Self-Attention
Let us start with revisiting what attention is in the NLP universe?
Attention allowed us to focus on parts of our input sequence while we predicted our output sequence. In simpler terms, self-attention helps us create similar connections but within the same sentence. Look at the following example:
- “I poured water from the bottle into the cup until it was full.” it => cup
- “I poured water from the bottle into the cup until it was empty.” it=> bottle
By changing one word “full” to “empty” the reference object for “it” changed. If we are translating such a sentence, we will want to know what the word “it” refers to.
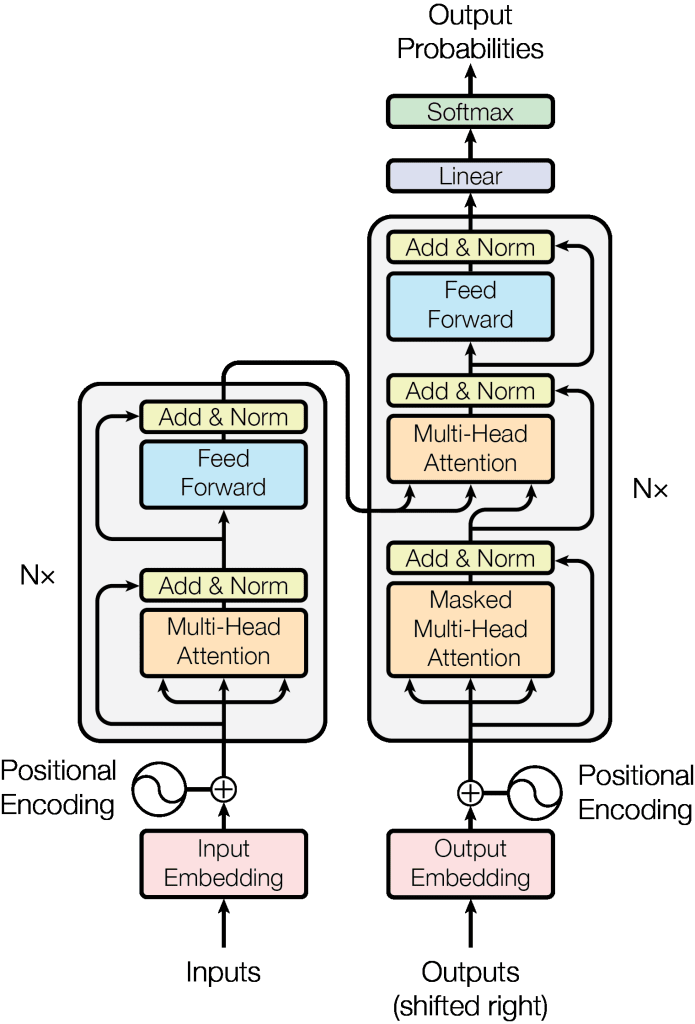
Transformers Model:
In transformers "token" and "vector" are fundamental concepts of how data is represented and processed within the model.
Token
In natural language processing, a token refers to a unit of text that has been segmented for processing. For example:
- At the word level: Each word in a sentence is treated as a separate token.
- At the subword level: Words are broken down into smaller subword units, such as prefixes, suffixes, or stems. This approach is particularly useful for handling morphologically rich languages or dealing with out-of-vocabulary words.
- At the character level: Each character in a word is treated as a separate token.
Tokens serve as the basic building blocks of input sequences in transformers. Before processing input data, it is tokenized into these units to represent the textual information in a format suitable for the model.
Vector
A vector refers to a mathematical representation of a token in a high-dimensional space. Each token is associated with a vector which captures its semantic and syntactic properties learned from the training data.
During the training process, the model learns to map tokens to vectors in such a way that tokens with similar meanings or contexts are represented by similar vectors, facilitating the model's ability to understand and process language effectively.
These token embeddings are the input to the transformer model. The model processes these embeddings through multiple layers of attention mechanisms and feedforward neural networks to generate contextualized representations of the tokens, capturing the relationships between them within the input sequence.
How Transformres works:
Word embeddings
Word embeddings in transformers are a way to represent words in a numerical form that a machine learning model can understand. Think of it like translating words into a language that computers speak.
Position embeddings
Position embeddings in transformers are a crucial component that helps the model understand the sequential order of tokens within an input sequence. In natural language processing tasks, such as text generation or language translation, the order of words or tokens in a sentence carries important semantic and syntactic information.
Encoder
The encoder is like a smart detective that reads and understands the input sequence. Its job is to take in a sequence of tokens (words or subwords) and convert each token into a rich representation called a context vector. The encoder does this by processing the tokens through multiple layers of attention mechanisms and feedforward neural networks. These context vectors capture the meaning and context of each token in the input sequence.
Decoder
The decoder is like a creative storyteller that uses the context vectors provided by the encoder to generate an output sequence. It takes the context vectors and produces tokens one by one, using them to guide its generation process. At each step, the decoder pays attention to the context vectors produced by the encoder to ensure that the generated tokens are relevant and coherent with the input sequence. This allows the decoder to generate meaningful output sequences based on the understanding provided by the encoder.
Attention
Attention helps the model to understand the context of a word by considering words that go before and after it.
Training
Transformer models are trained using supervised learning, where they learn to minimize a loss function that quantifies the difference between the model's predictions and the ground truth for the given task.
Where are transformers used?
Earlier we looked that transformers are used for natural language processing tasks. However now it is using in the fields like computer vision and speech recognition. Some examples are:
- Computer vision
- Speech recognition
- Question answering
- Text classification
Conclusion:
The Transformers architecture is poised to significantly advance the capabilities and applications of Generative AI, pushing the boundaries of what machines can create and how they assist in the creative process.
Posted on March 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.