How Render Scaled Knative to Support 100k+ Free-Tier Apps

Stephen Barlow
Posted on October 3, 2023

By Hieu Nguyen - October 3, 2023
In November 2021, Render introduced a free tier for hobbyist developers and teams who want to kick the tires. Adoption grew at a steady, predictable rate—until Heroku announced the end of their free offering ten months later:
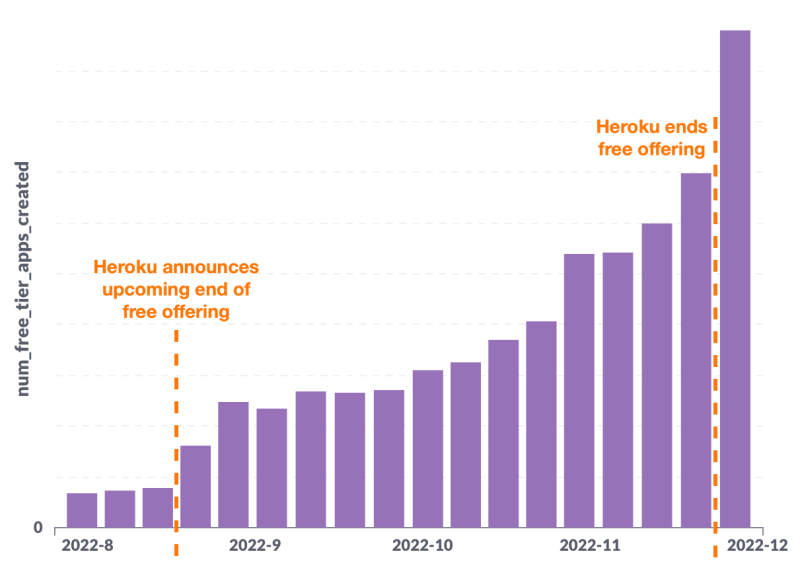
Render's free-tier adoption rate doubled immediately and grew from there (awesome), causing our infrastructure to creak under the load (less awesome). In the span of a month, we experienced four incidents related to this surge. We knew that if Free usage continued to grow (and it very much has—as of this writing, tens of thousands of free-tier apps are created each week), we needed to make it much more scalable. This post describes the first step we took along that path.
How we initially built Free
Some background: unlike other services on Render, free-tier web services "scale to zero" (as in, they stop running) if they go 15 minutes without receiving traffic. They start up again whenever they next receive an incoming request. This hibernation behavior helps us provide a no-cost offering without breaking the bank.
However, this desired behavior presented an immediate development challenge. Render uses Kubernetes (K8s) behind the scenes, and K8s didn't natively support scale-to-zero (it still doesn't, as of September 2023). In looking for a solution that did, we found and settled on Knative (kay-NAY-tiv). Knative extended Kubernetes with serverless support—a natural fit for services that would regularly spin up and down.
In the interest of shipping quickly, we deployed Knative with its default configuration. And, until our growth spurt nearly a year later, those defaults worked without issue.
Where we hit a wall
With the free-tier surge, the total number of apps on Render effectively quadrupled. This put significant strain on the networking layer of each of our Kubernetes clusters. To understand the nature of that strain, let's look at how this layer operates.
Two networking components run on every node in every cluster: Calico and kube-proxy.
Calico mainly takes care of IP address management, or IPAM: assigning IP addresses to Pods and Services (we're using capital-S Service to refer to a Kubernetes Service, to distinguish from the services that customers create on Render.). It also enforces Network Policies by managing iptables rules on the node.
kube-proxy configures a different set of routing rules on the node to ensure traffic destined for a Service is load-balanced across all backing Pods.
Both of these components do their jobs by listening for creates, updates, and deletes to all Pods and Services in the cluster. As you can imagine, having more Pods and Services that changed more frequently resulted in more work:
More work meant more CPU consumption. Remember, both Calico and kube-proxy run on every node. The more CPU these components used, the less we had left to run our customers' apps.
More work meant higher update latency. As the work queue grew, each networking change took longer to propagate due to increased time spent waiting in the queue. This delay is defined as the network programming latency, or NPL (read more about NPL here). When there was high NPL, traffic could be routed using stale rules that led nowhere (the Pod had already been destroyed), causing connections to fail intermittently.
To mitigate these issues, we needed to reduce the overhead each free-tier app added to our networking machinery.
"Serviceless" Knative
As mentioned, we'd deployed out-of-the-box Knative to handle free-tier resource provisioning. We took a closer look at exactly what K8s primitives were being provisioned for each free-tier app:
- One Pod (for running the application code). Expected.
-
2N + 1Services, whereNis the number of times the app was deployed. This is because Knative manages changes with Revisions, and retained resources belonging to historical Revisions. _Un_expected.
We figured the Pod needed to stay, but did we really need all those Kubernetes Services? What if we could get away with fewer—or even zero?
We dove deeper into how those resources interacted in a cluster:

And learned what each of the Knative-provisioned Services (in purple above) was for:
- The Placeholder Service was a dummy service that existed to prevent naming collisions among resources for Knative-managed apps. There was one for every free-tier app.
- The Public Service routed incoming traffic to the app from the public internet.
- The Private Service routed incoming cluster-local traffic based on whether the app was scaled up.
- If scaled up, traffic was routed to the Pod.
- If scaled down, traffic was routed to the cluster's Knative proxy (called the activator), which handled scaling up the app by creating a Pod.
Armed with this newfound knowledge, we devised a path to remove all of these Services.
Step by step
We started simple with the dummy Placeholder Service, which did literally nothing. There was no risk of naming collisions among our Knative-managed resources, so we updated the Knative Route controller to stop creating the Placeholder Service. ❌
Next! While the Public Service (for public internet routing) is needed for plenty of Knative use cases out there, in Render-land, all requests from the public Internet must pass through our load-balancing layer. This means requests are guaranteed to be cluster-local by the time they reach Pods, so the Public Service also had nothing to do! We patched Knative to stop reconciling it and its related Endpoint resources. ❌
Finally, the Private Service (for cluster-local routing). We put together the concepts that Services are used to balance load across backing Pods, and that a free-tier app can have at most only one Pod receiving traffic at a time, making load balancing slightly unnecessary. There were two changes we needed to make:
Streamline traffic to flow exclusively through the activator, as we no longer had a Service to split traffic to when the app is scaled up. With a little experimentation, we discovered that the activator could both wake Pods and reverse-proxy to a woke Pod, even though that behavior wasn't documented! We just needed to set the right headers.
Patch the activator to listen for changes to Pod readiness states, and route directly to Pod IP addresses (thanks, Calico!). By default, the activator listens for changes to EndpointSlices, but those are tied to the Services we were hoping to delete.
And just like that, the Private Service was no more. ❌
Want to go deeper under the hood? Check out an abridged version of the design doc for removing the Private Service.
At the end of this entire optimization pass, the networking architecture for a free-tier app had been simplified to the following:

Zero Kubernetes Services per free-tier app! Predictably, K8s Service counts plummeted across our clusters:

With these improvements, Calico and kube-proxy's combined usage fell by hundreds of CPU seconds in our largest cluster.
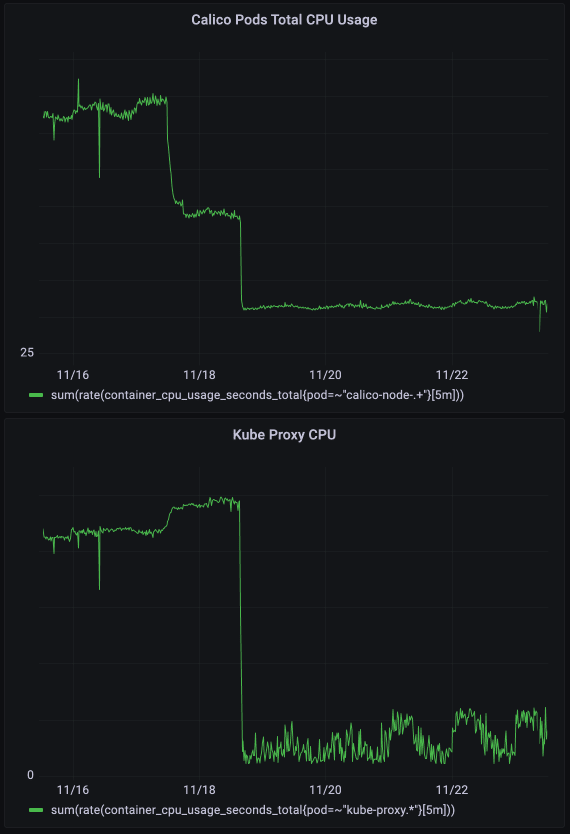
With compute resources freed up, free-tier network latency and stability improved dramatically. But even so, we knew we had more work to do.
A moving target
Our Knative tweaks bought us some much-needed breathing room, but ultimately, free-tier usage began to put a strain even on this optimized architecture. The time was quickly approaching for us to rip out Knative entirely, in favor of a home-grown solution that was tailor-made for Render's needs.
But that's a story for another post!
--
Related reading
Posted on October 3, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


