
Renato Teixeira
Posted on February 12, 2024

Certamente você pode imaginar a importância de se versionar um código, para poder reverter alterações, recuperar dados perdidos, entre outras possibilidades. E aposto que você conhece alguém (não eu hehe) que controla a versão dos seus arquivos criando cópias deles com nomes cada vez mais criativos...

Até 1972, provavelmente era assim que qualquer pessoa faria o controle de versão dos seus códigos também, antes do lançamento do SCCS (Source Code Control System), um dos primeiros softwares de gerenciamento de versões centralizados que já foram lançados.
Mas não é o SCCS que nos interessa agora e sim o GIT, software de versionamento de código distribuído open-source que completa 20 anos do seu lançamento no ano que vem (07/04/2005).
Índice
- 1. O que é GIT?
- 2. Como o GIT funciona?
- 3. Instalando o GIT
- 4. Configurando o GIT
- 5. Iniciando um repositório local
- 6. Trabalhando com GIT
- 7. Conhecendo as branches
- 8. Sincronizando com o repositório remoto
- 9. Conclusão
- 10. Referências
1. O que é GIT?
GIT é um sistema de controle de versão distribuído open-source lançado em 2005, que foi desenvolvido por Linus Torvald (isso mesmo, o criador do kernel do Linux).
Com o GIT, é possível controlar as versões de um projeto localmente (na pasta de trabalho) e sincronizar todas as alterações para um repositório remoto (no GitHub, por exemplo).
2. Como o GIT funciona?
Imagine um arquivo físico onde há uma pasta com todos os arquivos do projeto. Dessa forma, sempre que alguém precisar manipular um arquivo, é preciso pegá-lo, removendo-o de dentro da pasta e retornando-o para a pasta após concluir o trabalho. Assim, é impossível que duas pessoas trabalhem num mesmo arquivo, evitando totalmente possíveis conflitos.
MAS NÃO É ASSIM QUE O GIT FUNCIONA! (ainda bem)
Esse é o funcionamento de um sistema de versionamento CENTRALIZADO, no qual o usuário precisa realizar o "check-out" e "check-in" de arquivos, ou seja, sempre que alguém precisa trabalhar em um determinado arquivo é necessário realizar o "check-out" desse arquivo, removendo-o do repositório, e depois de concluído o trabalho, realizar o "check-in" do arquivo, retornando-o para o repositório.
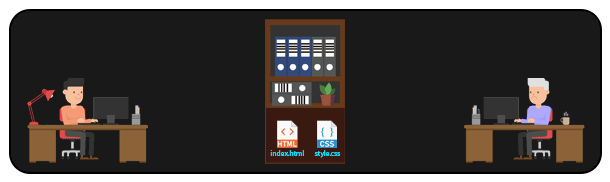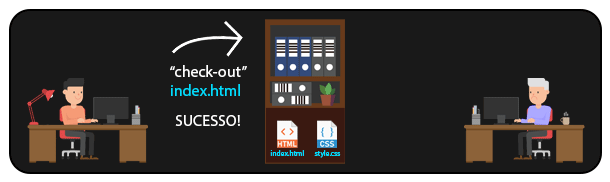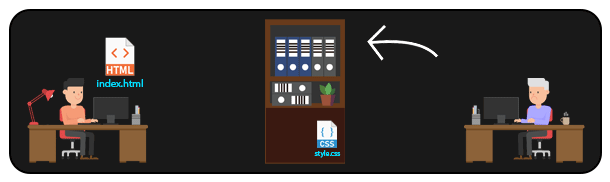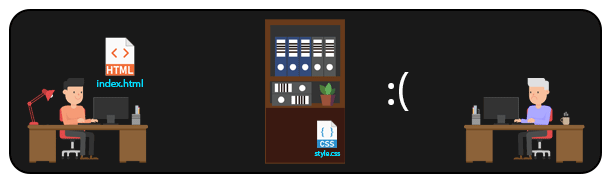
Em um sistema DISTRIBUÍDO como o GIT, é possível que várias pessoas acessem arquivos de um mesmo repositório remoto. Dessa forma, sempre que alguém precisar manipular um arquivo, basta cloná-lo (ou clonar todo o repositório) localmente para sua máquina, e depois enviar as modificações de volta ao repositório remoto. Assim, é possível que diversas pessoas trabalhem no mesmo projeto, manipulando até mesmo os mesmos arquivos.
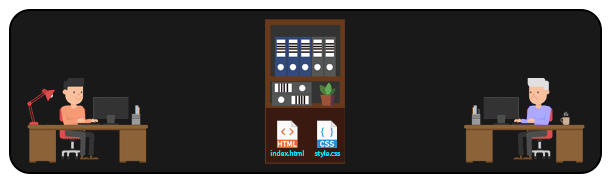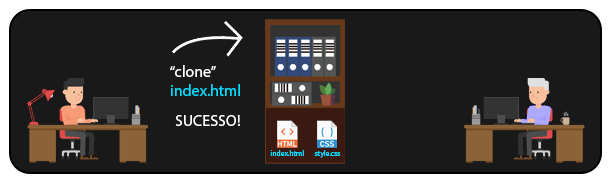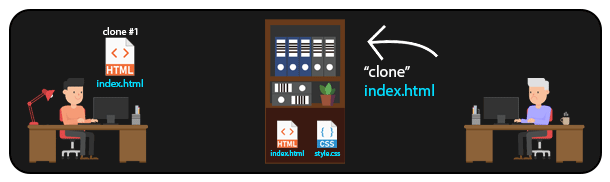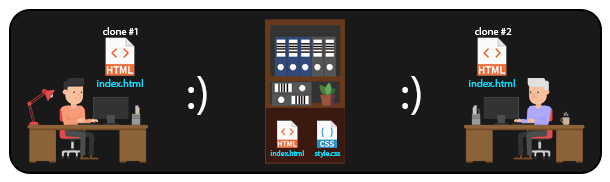
Esse tipo de abordagem é o que permite a distribuição de grandes projetos open-source, com pessoas de diversas partes do mundo trabalhando em um mesmo projeto, gerenciando as modificações e possíveis conflitos (sim, conflitos de merge podem acontecer aqui).
3. Instalando o GIT
Atualmente, GIT está disponível para os principais sistemas operacionais (Windows, Linux, MacOs...) e a sua instalação é bem simples, podendo ser feita por linha de comando ou através do instalador oficial em git-scm.com.
3.1 No Windows
Para instalar o GIT no Windows, basta acessar o site oficial e realizar o download do instalador.
Com isso, basta apertar seguir as instruções que tudo deve correr bem e será possível utilizar os comandos do GIT no seu terminal.
3.2 No Linux
Para o Linux, é possível instalar o GIT utilizando o comando abaixo:
sudo apt install git-all
Dessa forma, o GIT estará pronto para ser usado em seu terminal.
3.3 No MacOS
No Mac, a forma mais fácil de instalar o GIT é instalando o Homebrew e então executando o comando abaixo no terminal:
brew install git
Assim, o GIT também ficará disponível para ser utilizado em seu terminal.
4. Configurando o GIT
Após a instalação, é importante configurar o GIT utilizando os comandos abaixo:
git config --global user.name "[username]"
# ex.: John Doe
git config --global user. email "[email@email.com]"
# ex.: johndoe@email.com
Também é possível configurar usuários específicos para determinados repositórios locais removendo a tag
--global.
5. Iniciando um repositório local
Com o GIT configurado, podemos iniciar nosso repositório.
Para isso, é possível iniciar um novo repositório do zero ou clonar um repositório remoto existente.
5.1 Iniciando do zero (git init)
Para iniciar um novo repositório, basta navegar até a pasta raiz que desejamos tornar um repositório e executar o comando abaixo:
git init

Dessa forma, um diretório .git será criado dentro da pasta do projeto, que será responsável pelo controle de versão na pasta de trabalho desse repositório local.
5.2 Clonando um repositório (git clone)
Clonar um repositório remoto existente é tão fácil quanto iniciar um novo repositório do zero. Para isso, basta utilizar o comando git clone passando a URL do repositório à ser clonado como parâmetro dentro da pasta em que deseja clonar o repositório:
git clone [url-do-repositório-clonado]
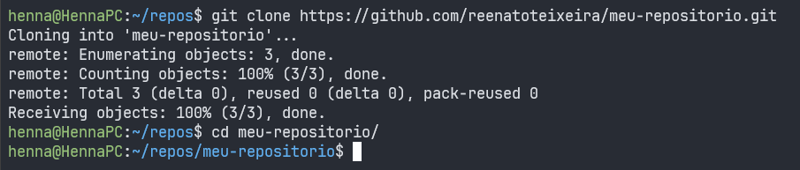
Dessa forma, todo o repositório sera clonado para sua máquina local, sendo automaticamente atrelado ao repositório remoto de origem.
Em um repositório clonado não haverá necessidade de utilizar o comando
git remoteno futuro.
6. Trabalhando com GIT
Tendo o repositório local inicializado, é possível trabalhar em nosso projeto utilizando o controle de versão do GIT localmente.
Dentro do nosso repositório local, podemos criar os arquivos necessários para o nosso projeto, mas eles não serão sincronizados automaticamente pelo GIT, para isso é necessário que informemos quando houver mudanças para serem versionadas.
Assim, podemos manipular os arquivos como quisermos e, após concluir as alterações desejadas, enviar os arquivos atualizados para o GIT.
Para isso, é importante entender que existe um fluxo infinito (sim, infinito) de 3 estágios no controle de versões:
MODIFY -> STAGE -> COMMIT
MODIFY: Primeiro estágio do controle de versões, aqui são colocados os arquivos que sofreram alguma alteração comparada à última versão disponível.
STAGE: Segundo estágio do controle de versões, aqui são colocados os arquivos modificados que queremos adicionar ao próximo commit.
COMMIT: Estágio final do controle de versões, quando confirmamos as modificações feitas, enviando os arquivos modificados que estavam em stage para o repositório local.
Com os arquivos commitados, temos uma nova versão disponível no repositório local, que pode novamente sofrer alterações, passando novamente para "modified", ter essas novas alterações colocadas em "stage" e novamente "commitadas", confirmando uma nova versão e assim por diante (e por isso "infinito" lol).
Um commit não exclui a versão antiga dos arquivos modificados, apenas inclui a nova versão com um apontamento para a última versão disponível, mantendo assim o rastreamento das versões de cada arquivo rastreado pelo GIT.
6.1 Adicionando e commitando (git add e git commit)
Apesar de parecer complexo, executar o fluxo de versionamento é bem simples. Após concluir as modificações desejadas, adicionamos os arquivos modificados que desejamos commitar em stage:
git add [nome-do-arquivo]
git add -A-> adiciona todos os arquivos modificados para stage de uma vez.
git add *.[extensão-do-arquivo]-> adiciona todos os arquivos modificados com a extensão especificada para stage de uma vez (ex.:git add *.html).
É possível verificar o status atual do nosso repositório a qualquer momento utilizando o comando git status:

Perceba que, ao executar o git status dentro do repositório após criar um novo arquivo, o novo arquivo é exibido como "Untracked". Isso significa que esse arquivo é novo e ainda precisa ser adicionado à algum commit para que seja rastreado pelo GIT.
É possível fazer com que o GIT ignore determinados arquivos ou pastas dentro do repositório. Para isso basta adicionar um arquivo à pasta raiz chamado
.gitignoree, dentro dele, destacar o nome dos arquivos ou pastas que devem ser ignorados.ATENÇÃO: Arquivos e pastas ignorados não aparecem mais no rastreamento do GIT, nem mesmo como "Untracked". Para retornar o rastreamento basta apagar os nomes do arquivo
.gitignore.
Para incluir um arquivo, podemos executar o comando git add que vimos antes com o nome do arquivo que desejamos adicionar ("index.html" nesse caso):
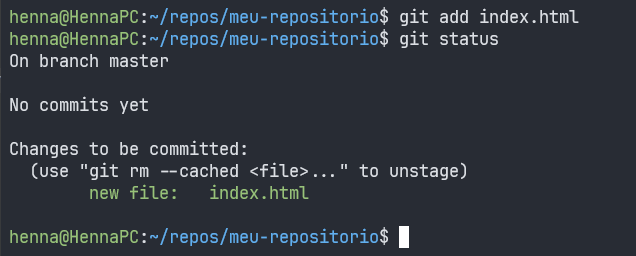
Dessa forma, ao executar novamente o git status podemos perceber que o novo arquivo foi adicionado ao "stage" e está finalmente pronto para ser enviado no nosso próximo commit, que pode ser feito utilizando o comando abaixo:
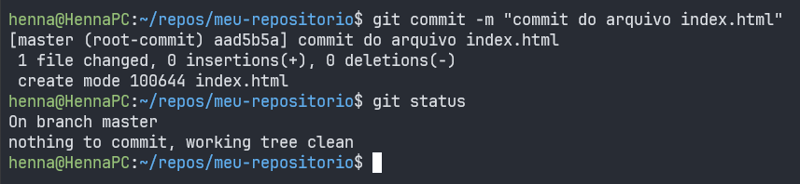
git commit -m "[mensagem-descritiva]"
COMMITS possuem ID's (hash) únicos e são IMUTÁVEIS, ou seja, não podem ser modificados após confirmados.
git commit -a-> realiza o commit direto, adicionando todos os arquivos modificados em stage e realizando o commit.
Após realizar o commit com sucesso, ao executar o git status percebemos que não há mais arquivos modificados para serem enviados, uma vez que todas as modificações foram efetivamente salvas no nosso repositório local com o último commit.
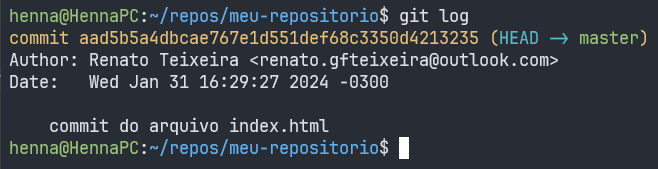
Ainda é possível comprovar as mudanças realizadas ao rever o log de commits do repositório, utilizando o comando git log, que mostra alguns metadados de todos os commits realizados como o código hash, branch, autor, data, etc.
Todo esse processo pode ser repetido para adicionar novos arquivos que sejam necessários ao seu projeto, modificá-los e enviá-los ao repositório local através de commits.

git log -N-> exibe o log dos últimos N commits.
git log [branch-A] [branch-B]-> exibe o log dos commits que estão na "branch-B" mas não estão na "branch-A".
git log --follow [nome-do-arquivo]-> exibe o log dos commits que alteraram o arquivo especificado, mesmo que ele tenha mudado de nome.
git diff-> lista as modificações feitas em relação à última versão disponível no repositório.
git diff [nome-do-arquivo]-> lista as modificações feitas no arquivo especificado em relação à sua última versão disponível no repositório.
6.2 Desfazendo mudanças antes e depois do commit
Antes de realizar um commit, todas as mudanças feitas no repositório local podem ser desfeitas, ou alteradas, mas após realizar o commit, não é possível alterá-lo. Isso porque commits são objetos imutáveis, ou seja, é impossível editar ou alterar as informações de um commit realizado.
Ainda assim, é possível realizar novos commits que desfazem alguma alteração, ou corrigem informações incorretas em commits anteriores. Para ambos os casos, podemos utilizar um dos comandos listados abaixo:
git checkout -- [nome-do-arquivo]
# Descarta as mudanças feitas no arquivo local, antes do commit (ação irreversível)
git reset --hard HEAD
# Descarta as mudanças feitas em um arquivo que está em stage, antes do commit
git reset --hard HEAD~1
# Descarta o último commit realizado no repositório local (somente o último commit)
git commit --amend
# Realiza um novo commit, substituindo o último commit feito no repositório local
git revert [hash-do-commit]
# Realiza um novo commit revertendo as alterações do commit especificado
7. Conhecendo as branches
Uma branch nada mais é do que uma ramificação do repositório e, até agora, todas as ações foram realizadas na branch master/main.
Por padrão, a primeira branch criada no repositório é a branch
master/main, que é a branch principal do repositório.
7.1 Pra que servem as branches?
A princípio pode não parecer grande coisa, mas as branches dão um poder enorme pro desenvolvimento do projeto.
Imagine que estamos desenvolvendo uma plataforma web e queremos testar uma nova feature, mas nosso repositório já está sendo hospedado ou compartilhado com outras pessoas e qualquer alteração problemática pode causar uma péssima experiência à essas pessoas. O que podemos fazer?
Se você pensou em duplicar a pasta do projeto, criando uma "versão de testes", você acertou! Bom, em partes...
Com o GIT, é possível fazer algo parecido utilizando as branches. Como elas são ramificações, podemos simplesmente criar uma nova branch, chamada de "teste" (por exemplo), e assim teremos uma versão do nosso projeto em uma branch totalmente isolada, pronta pra ser revirada sem qualquer risco de impactar a branch principal.

7.2 Criando branches (git branch)
Criar uma branch significa criar uma cópia paralela do repositório que pode ser trabalhada independentemente, sem impactar a branch master/main. Para isso, basta utilizar o comando abaixo:
git branch [nome-da-branch]
Executar o comando
git branchsem um nome exibe a lista de branches disponíveis no repositório, com um "*" na branch que está sendo utilizada atualmente.
Antes de executar o comando git branch teste, o comando git branch retornava somente a branch master.

Após criar uma nova branch, é possível alternar entre as branches disponíveis utilizando o comando abaixo:
git checkout [nome-da-branch]
Após executar o comando git checkout teste, podemos ver que a branch ativa é alternada. A partir desse momento todo o trabalho commitado estará sendo enviado para a branch teste do repositório, sem impactar a branch master/main.

É possível criar quantas branches forem necessárias e podemos interagir com as branches criadas utilizando os comandos abaixo:
git checkout -b [nome-da-branch]-> cria uma nova branch com o nome especificado e já alterna para ela.
git branch -d [nome-da-branch]-> exclui a branch especificada.
git branch -m [novo-nome]-> altera o nome da branch atual para o nome especificado.
7.3 Combinando branches (git merge)
Quando finalizamos o trabalho em uma branch diferente e temos segurança de que as alterações feitas não ocasionaram problemas no código, podemos mergear (combinar) a branch atual com a branch master/main, aplicando todas as mudanças da branch atual à branch principal do repositório.
Para realizar o merge de uma branch à outra, devemos alternar para a branch que vai receber as alterações e utilizar o comando abaixo:
git merge [nome-da-branch]
# faz o merge da branch especificada na branch atual
Nos nossos exemplos, como estamos na branch teste, devemos alternar para a branch master utilizando o comando git checkout e então executar o comando git merge com o nome da branch que desejamos combinar ("teste", nesse caso)
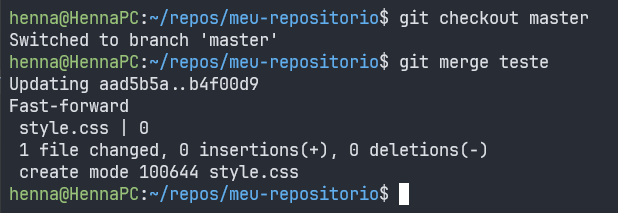
Dessa forma, todo o trabalho feito na branch teste (a criação do arquivo style.css, nesse caso) será combinado com a branch master.
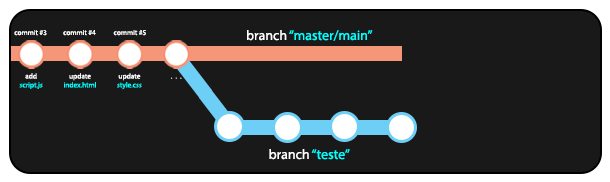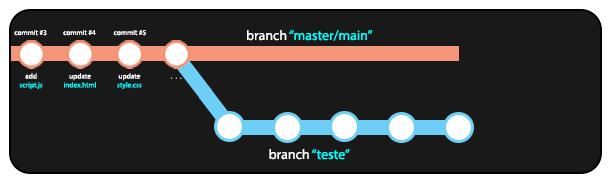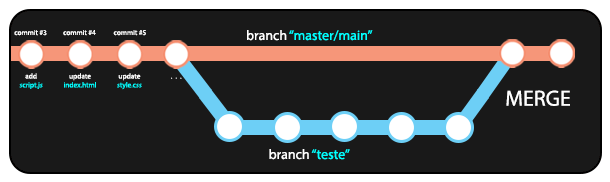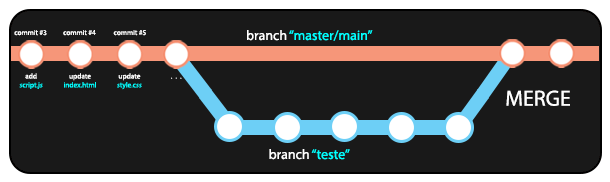
7.4 Conflitos no merge
Combinando diferentes branches com o git merge podemos nos deparar com alguns conflitos nos casos em que um ou mais arquivos tenham sido alterados nas mesmas linhas e a combinação não pode ser realizada de maneira automática.

Nesses casos, podemos executar o comando git status para verificar quais arquivos estão conflitando.

Será necessário resolver os conflitos antes de prosseguir com o merge, definindo quais alterações devem prevalecer ou refazendo as alterações para que sejam mutuamente comportadas. Para isso, o próprio GIT insere marcações dentro dos arquivos conflitantes que auxiliam a resolução.
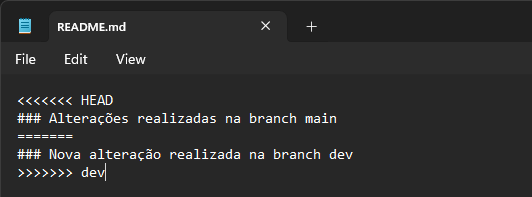
Após resolver os conflitos, basta recolocar os arquivos modificados em stage, realizar o commit das novas versões sem conflitos e executar novamente o comando git merge que tudo deve ser combinado sem maiores problemas.
8. Sincronizando com o repositório remoto
Sabemos que é possível relacionar o nosso repositório local à um repositório remoto para sincronizar todo o nosso trabalho remotamente e mantê-lo sempre atualizado.
Para isso, utilizaremos o comando git push, que envia todos os commits do repositório local para o repositório remoto, mas antes, precisamos configurar um repositório remoto apropriado.
8.1 Configurando um repositório remoto
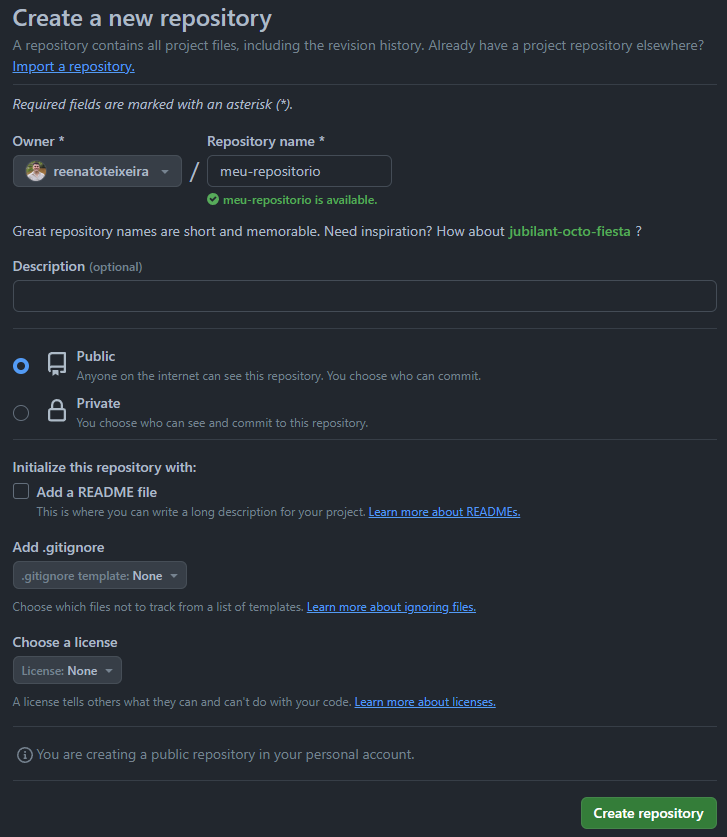
Iniciar um repositório remoto é bastante simples. Aqui vamos utilizar o GitHub para isso.
Primeiro, devemos iniciar um novo repositório vazio em nossa conta do GitHub (apenas escolhendo um nome e clicando em "Criar repositório"):
Após isso, precisamos configurar a relação entre o repositório remoto e o repositório local, executando o comando abaixo dentro do nosso repositório local:
git remote add origin [url-do-repositorio-remoto]

git remote -v-> exibe a URL do repositório remoto conectado ao repositório local atualmente.
Com o repositório remoto conectado, devemos alterar o nome da nossa branch master/main local para "main" com o comando git branch -m main (ignorar se a sua branch local já se chamar main):

É importante que a branch principal do repositório local tenha o mesmo nome da branch principal do repositório remoto ao qual vamos realizar o push.
Finalmente, após cumprir os passos acima, podemos sincronizar nosso trabalho local com o repositório remoto pela primeira vez utilizando o comando abaixo:
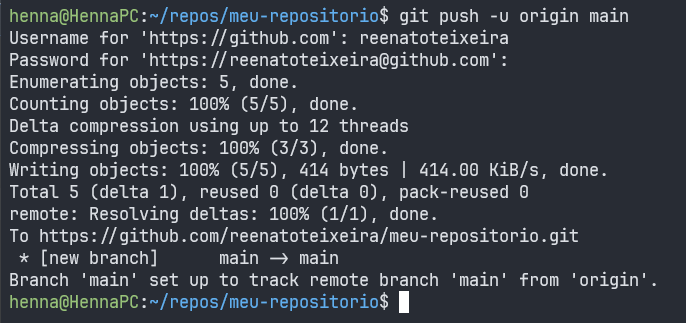
git push -u origin main

Ao executar o comando git push -u origin main pode ser necessário informar suas credenciais do GitHub (usuário e token de acesso).
Se você não sabe o que é um token de acesso do GitHub, ou ainda não tem seu token de acesso configurado, clique aqui.
Também é possível contornar isso configurando a autenticação com o CLI do GitHub. Saiba como clicando aqui.
Após autenticar, o git push deve ser executado com sucesso, sincronizando todos os commits do repositório local com o repositório remoto.
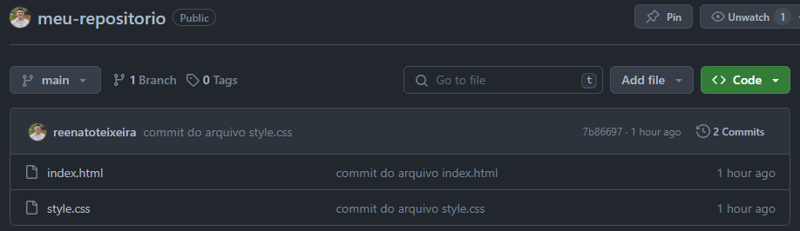
8.2 Git push depois da primeira vez (git push)
Depois de passar por todas as etapas acima, novas sincronizações podem ser realizadas somente utilizando o comando git push, sem que haja necessidade de passar qualquer parâmetro, como vemos abaixo.
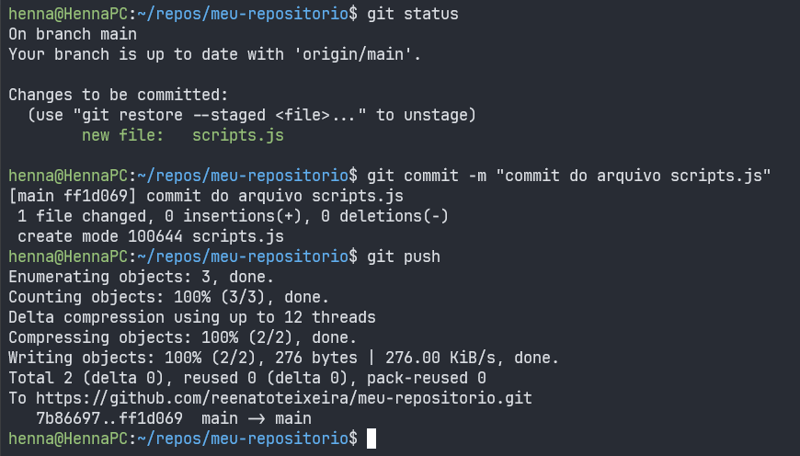
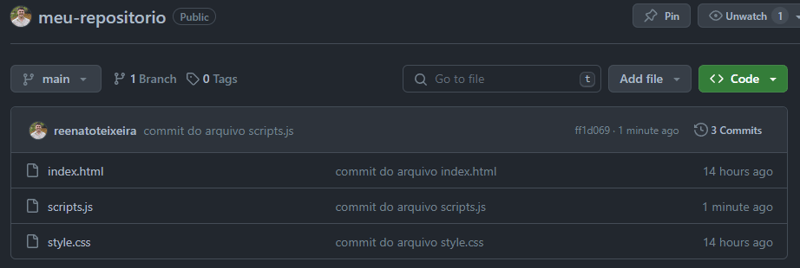
Nesse caso, a autenticação necessária para realizar o
git pushfoi contornada utilizando o CLI do GitHub. Saiba como clicando aqui.
8.3 Atualizando o repositório local (git pull)
Com um repositório remoto distribuído, é possível que alterações sejam feitas remotamente (diretamente no repositório remoto), fazendo com que nosso repositório local fique desatualizado.
Por isso, é muito importante atualizar o repositório local, sincronizando quaisquer mudanças existentes no repositório remoto, garantindo que o código local esteja sempre em sua última versão disponível no repositório remoto. Para isso, podemos utilizar o comando abaixo:
git pull
Imagine que um novo arquivo README.md foi criado diretamente no repositório remoto e, com isso, nosso repositório local está desatualizado.
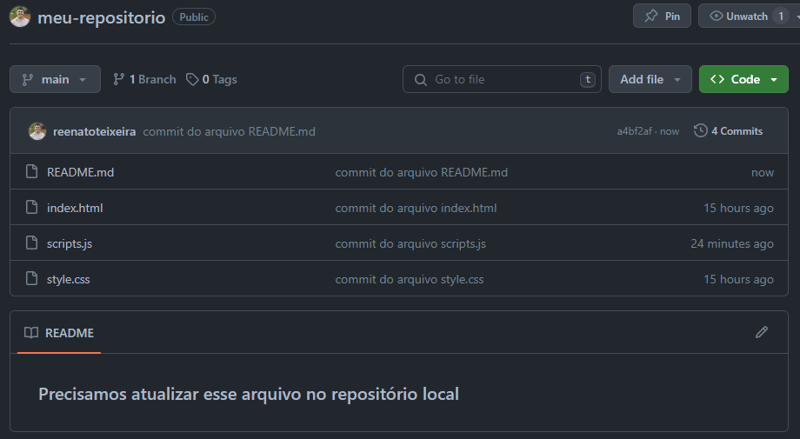
Dentro do repositório local, podemos sincronizar as alterações do repositório remoto com o git pull.
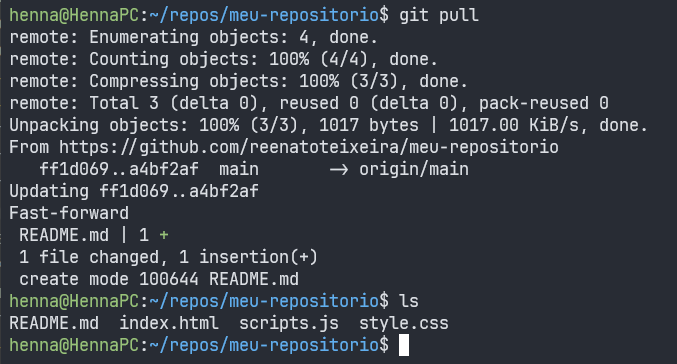
As primeiras 7 linhas retornadas ao executar o comando
git pullsão resultado do comandogit fetch. Ou seja, ao executar o comandogit pullsem executar o comandogit fetchpreviamente, o GIT executa ambos em conjunto para recuperar as atualizações do repositório remoto e sincronizá-las no repositório local.
git fetch-> Recupera as atualizações do repositório remoto, mas não sincroniza o repositório local (necessita dogit pull)
9. Conclusão
Tudo isso nos traz a certeza de que o GIT é um sistema de controle de versão necessário no dia a dia de um programador, e conhecer seus principais comandos e utilidades pode ser o divisor de águas em nossa senioridade técnica.
Por fim, com os repositórios locais e remotos sincronizados e atualizados e com tudo o que aprendemos até agora, estamos prontos para seguir em frente com a praticidade desse incrível sistema de controle de versão.
10. Referências
- Documentação oficial do GIT
- GIT: Mini Curso para Você Sair do Zero! (Aprenda em 45 Minutos) - Codigo Fonte TV
Publicado originalmente em Inglês:
Everything you need to know about GIT
Posted on February 12, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

