Correlation - The Hard Way in JMeter

NaveenKumar Namachivayam ⚡
Posted on August 29, 2022

I have already posted many video tutorials about correlation in JMeter, LoadRunner, and other tools on my YouTube channel. But all the methods which I explained are abstracted and traditional. In this blog post, let us see how it can be done in a hard way.
What is Correlation?
There is no official term as correlation in JMeter ecosystem. It is a generic term used by performance engineers/testers. Also, entitling this blog post with a correlation word helps in SEO :)
Correlation is a process of extracting a string from the response body, response header or basically anything from the response. After extracting the response, it can be stored in a variable for subsequent use.
Typical example would be a login session. Session IDs are unique and gibberish. Hard-coding it in the script is not an effective way of handling it. Because it may expire based on the web server-side properties.
Correlation - Hard way in JMeter
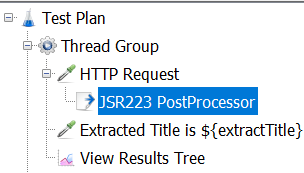
Let us start with extracting a title tag from the response using Groovy scripting by adding a JSR223 Post processor in JMeter. Below is the test plan tree.
Here is the Groovy script.
response = prev.getResponseDataAsString() //Extract the previous response
def extractTitle = /<title>(.+?)<\/title>/
def matcher = response =~ extractTitle
if (matcher.size() >=1) {
println matcher.findAll()[0][1]
vars.put("extractTitle",matcher.findAll()[0][1])
}Here is the URL https://jpetstore-qainsights.cloud.okteto.net/jpetstore/actions/Catalog.action
The first step is to read the HTTP response as a string using prev.getResponseDataAsString()
prev is an API call which extracts the previous SampleResult. Using the method getResponseDataAsString() we can extract the whole response as a string and store it in a variable.
The next two lines define our regular expression pattern and the matching conditions. Groovy comes with powerful regular expression pattern matching.
def extractTitle = /<title>(.+?)<\/title>/
def matcher = response =~ extractTitleThe next block checks for any matches of >=1, then it will print the extracted string from the array list. Then, it will store the value to the variable extractTitle using the vars.put method.
if (matcher.size() >=1) {
println matcher.findAll()[0][1]
vars.put("extractTitle",matcher.findAll()[0][1])
}Here is the output:
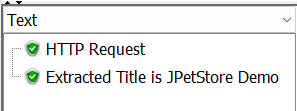
The above method is not effective for a couple of reasons. One, the array index to capture the desired string might be cumbersome for the complex response. Second, typically the pattern we use here is apt for the text response, not for the HTML response. For the complex HTML response, using the regular expression might not yield better performance.
Using JSoup
To handle the HTML response effectively, it is better to use HTML parsers such as JSoup.
JSoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors.
Let us use Grab, so that JMeter will download the dependencies on its own, else you need to download the JSoup jar and keep it in the lib or ext folder.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
Document doc = Jsoup.parse(response)
println doc.title()doc object will parse the response and print the title to the command prompt in JMeter.
To print all the links and its text, the below code snippet will be useful.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
Document doc = Jsoup.parse(response)
println doc.title()
// To print all the links and its text
Elements links = doc.body().getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
println linkHref + linkText
}To print all the list box elements and random list box values for the url (http://computer-database.gatling.io/computers/new), use the below code snippet.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
companyList = []
Random random = new Random()
Document doc = Jsoup.parse(response)
// To print all the list box elements
Elements lists = doc.body().select("select option")
for (Element list : lists) {
println "Company is " + list.text()
companyList.add(list.text())
}
// To print random list box element
println("The total companies are " + companyList.size())
println(companyList[random.nextInt(companyList.size())])Final Words
As you learned, by leveraging the prev API we can extract the response and then parse it using JSoup library or by writing desired regular expressions in a hard way without using the built-in elements such as Regular Expression Extractor or JSON Extractor and more. This approach might not save time, but it is worth learning this approach which comes handy in situations like interviews.
Posted on August 29, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related