
Jan Piotrowski
Posted on May 3, 2022
Prisma ORM recently released support for MongoDB. This represents the first time Prisma has supported a database outside of the SQL world. Prisma has been known for supporting many relational databases, but how did it end up being able to support the quite different MongoDB?
🕴️ I work as the Engineering Manager of Prisma’s Schema team. We are responsible for the schema management parts of Prisma, which most prominently include our migrations and introspection tools, as well as the Prisma schema language and file (and our awesome Prisma VS Code extension!).
The other big team working on Prisma object relational-mapper (ORM) is the Client team that builds Prisma Client and the Query Engine. These let users interact with their database to read and manipulate data.
In this blog post, I summarize how our team got Prisma’s schema introspection feature to work for the new MongoDB connector and the interesting challenges we solved along the way.
Prisma
Prisma is a Node.js database ORM built around the Prisma schema language and the Prisma schema file containing an abstract representation of a user’s database. When you have tables with columns of certain data types in your database, those are represented as models with fields of a type in your Prisma schema.
Prisma uses that information to generate a fully type-safe TypeScript/JavaScript Prisma Client that makes it easy to interact with the data in your database (meaning it will complain if you try to write a String into a Datetime field, and make sure you, for example, include information for all the non-nullable columns without a default and similar).
Prisma Migrate uses your changes to the Prisma schema to automatically generate the SQL required to migrate your database to reflect that new schema. You don’t need to think about the changes necessary. You just write what you want to achieve, and Prisma then intelligently generates the SQL DDL (Data Definition Language) for that.
For users who want to start using Prisma with their existing database, Prisma has a feature called Introspection. You call the CLI command prisma db pull to “pull in” the existing database schema, and Prisma then can create the Prisma schema for you automatically, so your existing database can be used with Prisma in seconds.
This works the same for PostgreSQL, MySQL, MariaDB, SQL Server, CockroachDB, and even SQLite and relies on relational databases being pretty similar, having tables and columns, understanding some dialect of SQL, having foreign keys, and concepts like referential integrity.
Prisma + MongoDB
One of our most requested features was support for Prisma with MongoDB. The feature request issue on GitHub for MongoDB support from January 2020 was for a long time by far the most popular one, having gained more than a total of 800 reactions.

MongoDB is known for its flexible schema and the document model, where you can store JSON-like documents. MongoDB takes a different paradigm from relational databases when modeling data – there are no tables, no columns, schemas, or foreign keys to represent relations between tables. Data is often stored grouped in the same document with related data or “denormalized,” which is different from what you would see in a relational database.
So, how could these very different worlds be brought together?
Prisma and MongoDB: Schema team edition
For our team, this meant figuring out:
- How to represent a MongoDB structure and its documents in a Prisma schema.
- How to migrate said data structures.
- How to let people introspect their existing MongoDB database to easily be able to start using Prisma.
Fortunately solving 1 and 2 was relatively simple:
-
Where relational databases have tables, columns, and foreign keys that are mapped to Prisma’s models, with their fields and relations, MongoDB has equivalent collections, fields, and references that could be mapped the same way. Prisma Client can use that information to provide the same type safety and functionality on the Client side.
Relational database Prisma MongoDB Table → Model ← Collection Column → Field ← Field Foreign Key → Relation ← Reference With no database-side schema to migrate, creating and updating indexes and constraints was all that was needed for evolving a MongoDB database schema. As there is no SQL to modify the database structure (which is not written down or defined anywhere), Prisma also did not have to create migration files with Data Definition Language (DDL) statements and could just scope it down to allowing
prisma db pushto directly bring the database to the desired end state.
A bigger challenge turned out to be the Introspection feature.
Introspecting a schema with MongoDB
With relational databases with a schema, there is always a way to inquire for the schema. In PostgreSQL, for example, you can query multiple views in a information_schema schema to figure out all the details about the structure of the database—to, for example, generate the DDL SQL required to recreate a database, or abstract it into a Prisma schema.
Because MongoDB has a flexible schema (unless schemas are enforced through the schema validation feature), no such information store exists that could be easily queried. That, of course, poses a problem for how to implement introspection for MongoDB in Prisma.
Research
As any good engineering team would, we started by ... Googling a bit. No need to reinvent the wheel, if someone else solved the problem in the past before. Searches for “MongoDB introspection,” “MongoDB schema reverse engineering,” and (as we learned the native term) “MongoDB infer schema” fortunately brought some interesting and worthwhile results.
MongoDB Compass
MongoDB’s own database GUI Compass has a “Schema” tab in a collection that can analyze a collection to “provide an overview of the data type and shape of the fields in a particular collection.”
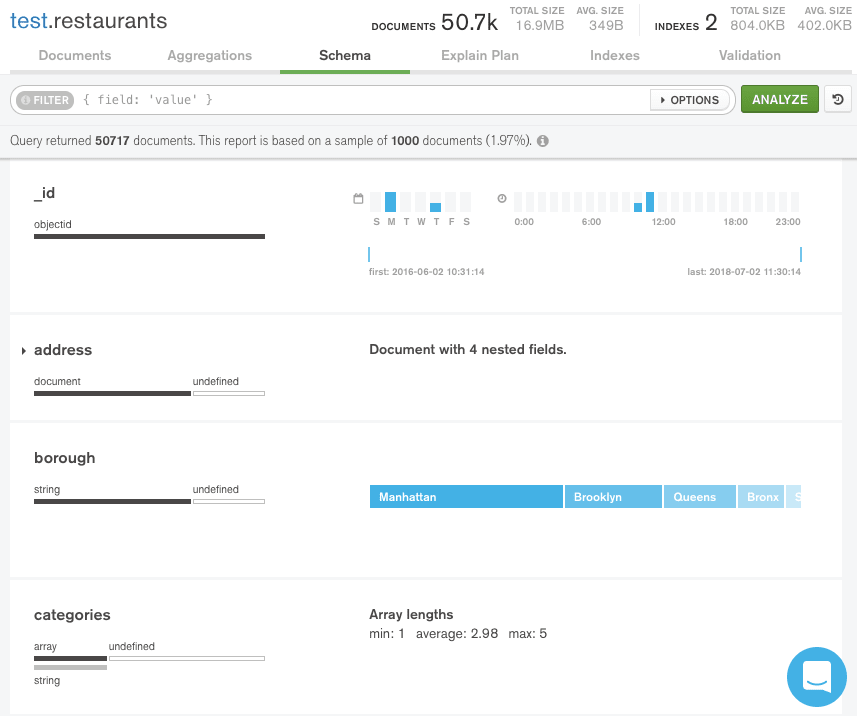
It works by sampling 1000 documents from a collection that has at least 1000 documents in it, analyzing the individual fields and then presenting them to the user.
mongodb-schema
Another resource we found was Lucas Hrabovsky’s mongodb-infer repository from 2014. Later that year, it seemed to have merged/been replaced by mongodb-schema, which is updated to this day.
It’s a CLI and library version of the same idea—and indeed, when checking the source code of MongoDB Compass, you see a dependency for mongodb-schema that is used under the hood.
Implementing introspection for MongoDB in Prisma
Usually, finding an open source library with an Apache 2.0 license means you just saved the engineering team a lot of time, and the team can just become a user of the library. But in this case, we wanted to implement our introspection in the same introspection engine we also use for the SQL databases—and that is written in Rust. As there is no mongodb-schema for Rust yet, we had to implement this ourselves. Knowing how mongodb-schema works, this turned out to be straightforward:
We start by simply getting all collections in a database. The MongoDB Rust driver provides a handy db.list_collection_names() that we can call to get all collections—and each collection is turned into a model for Prisma schema. 🥂
To fill in the fields with their type, we get a sample of up to 1000 random records from each collection and loop through them. For each entry, we note which fields exist, and what data type they have. We map the BSON type to our Prisma scalar types (and native type, if necessary). Optimally, all entries have the same fields with the same data type, which is easily and cleanly mappable—and we are done!
Often, not all entries in a collection are that uniform. Missing fields, for example, are expected and equivalent to NULL values in a relational database.
How to present fields with different types
But different types (for example, String and Datetime) pose a problem: Which type should we put into the Prisma schema?
🎓 Learning 1: Just choosing the most common data type is not a good idea.
In an early iteration of MongoDB introspection, we defaulted to the most common type, and left a comment with the percentage of the occurrences in the Prisma schema. The idea was that this should work most of the time and give the developer the best development experience—the better the types in your Prisma schema, the more Prisma can help you.
But we quickly figured out when testing this that there was a slight (but logical) problem: Any time the Prisma Client encounters a type that does not match what it has been told via the Prisma schema, it has to throw an error and abort the query. Otherwise, it would return data that does not adhere to its own generated types for that data.
While we were aware this would happen, it was not intuitive to us how often that would cause the Prisma Client to fail. We quickly learned about this when using such a Prisma schema with conflicting types in the underlying database with Prisma Studio, the built-in database GUI that comes with Prisma CLI (just run
npx prisma studio). By default, it loads 100 entries of a model you view—and when there were ~5% entries with a different type in a database of 1000 entries, it was very common to hit that on the first page already. Prisma Studio (and also an app using these schemas) was essentially unusable for these data sets this way.
Fortunately, everything in MongoDB is a Document, which maps to a Json type field in Prisma. So, when a field has different data types, we use Json instead, output a warning in Prisma CLI, and put a comment above the field in the Prisma schema that we render, which includes information about the data types we found and how common they were.

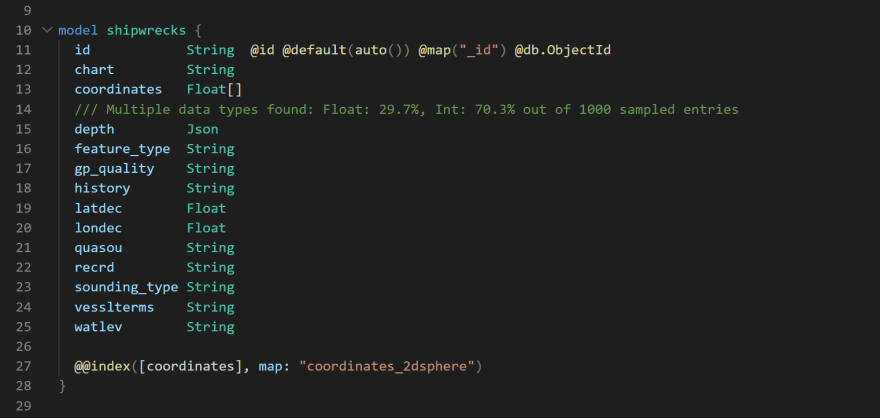
How to iterate on the data to get to a cleaner schema
Using Json instead of a specific data type, of course, substantially lowers the benefit you get from Prisma and effectively enables you to write any JSON into the field (making the data even less uniform and harder to handle over time!). But at least you can read all existing data in Prisma Studio or in your app and interact with it.
The preferred way to fix conflicting data types is to read and update them manually with a script, and then run prisma db pull again. The new Prisma schema should then show only the one type still present in the collection.
🎓 Learning 2: Output Prisma types in Prisma schema, not MongoDB types.
Originally, we outputted the raw type information we got from the MongoDB Rust driver, the BSON types, into our CLI warnings and Prisma schema comments to help our users iterate on their data and fix the type. It turned out that while this was technically correct and told the user what type the data was in, using the BSON type names was confusing in a Prisma context. We switched to output the Prisma type names instead and this now feels much more natural to users.
While Prisma recommends everyone to clean up their data and minimize the amount of conflicting types that fall back to Json, that is, of course, also a valid choice.
How to enrich the introspected Prisma schema with relations
By adding relation information to your introspected Prisma schema, you can tell Prisma to handle a specific column like a foreign key and create a relation with the data in it. user User @relation(fields: [userId], references: [id]) creates a relation to the User model via the local userId field. So, if you are using MongoDB references to model relations, add @relation to them for Prisma to be able to access those in Prisma Client, emulate referential actions, and help with referential integrity to keep data clean.
Right now, Prisma does not offer a way to detect or confirm the potential relations between different collections. We want to learn first how MongoDB users actually use relations, and then help them the optimal way.
Summary
Implementing a good introspection story for MongoDB was a fun challenge for our team. In the beginning, it felt like two very different worlds were clashing together, but in the end, it was straightforward to find the correct tradeoffs and solutions to get the optimal outcome for our users. We are confident we found a great combination that combines the best of MongoDB with what people want from Prisma.
Try out Prisma and MongoDB with an existing MongoDB database, or start from scratch and create one along the way.
Posted on May 3, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.