Lambda Architecture: Revolutionizing Data Processing for Big Data

Pragya Sapkota
Posted on September 26, 2023

We are living in a digital era where organizations deal with massive amounts of data generated from various sources. These data hold a huge potential for meaningful insights if processed correctly. It needs scalable and efficient data processing systems to harness this power and Lambda Architecture is one such approach with high prominence to handle large data volumes. It ensures fault tolerance and real-time processing capabilities that have benefited many organizations over the last few years.
What is Lambda Architecture?
Lambda Architecture is a data processing architecture that can handle large amounts of data in a fault-tolerant and scalable way. The architecture gets its name from the Greek letter lambda (λ), which signifies a function that transforms input data into output data.
Traditional databases and processing systems often struggle with the sheer volume, velocity, and variety of data generated in today’s digital landscape. They were originally designed for batch processing which makes them ill-equipped to provide real-time or near-real-time insights.
The concept of Lambda Architecture was first introduced in the book “Big Data: Principles and Best Practices of Scalable Realtime Data Systems” by Nathan Marz. It addressed the above challenges and provided a robust framework that can process large-scale data, making it suitable for applications ranging from social media analytics and e-commerce recommendation systems to fraud detection and IoT sensor data processing. It combines both batch processing and stream processing methods to make the data processing reliable and fast.
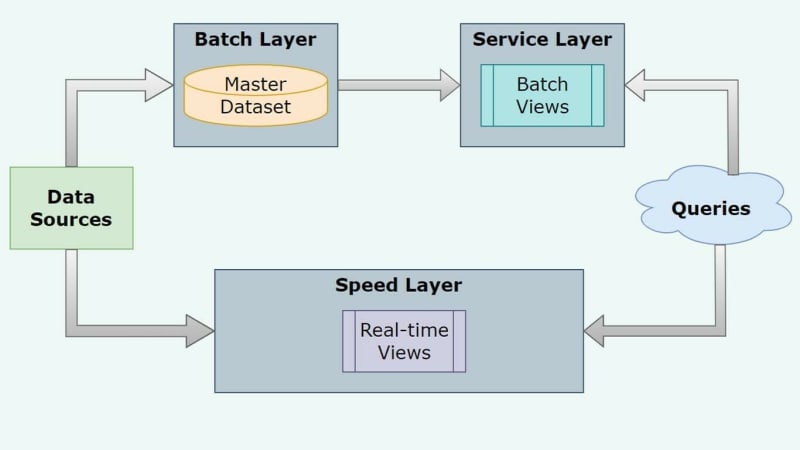
There are three main layers in Lambda Architecture:
Batch Layer
Serving Layer
Speed Layer
Let’s discuss these layers briefly:
1. Batch Layer
The first layer batch handles the process of storing and processing historical data in a batch-oriented fashion. With technologies like Hadoop MapReduce and Apache Stark, the batch layer performs large-scale batch processing jobs to generate batch views. Next, the batch views are precomputed and stored in a distributed file system or a NoSQL database.
Batch Layer can handle massive amounts of historical data efficiently without disturbing data consistency and fault tolerance. However, it is not suitable for real-time data processing.
2. Serving Layer
The serving layer is responsible for serving query results to users and applications in real-time. It uses the previously generated batch views from batch layers and uses databases like Apache HBase and Cassandra for quick data retrieval. The layer also provides low-latency access to query results.
3. Speed Layer
Lastly, we have the speed layer to address the need for real-time processing and incoming data. With technologies like Apache Kafka or Apache Flink, it ingests and processes streamlining data in near-real-time. The result is usually combined with those from the serving layer to provide up-to-date query results.
Why choose Lambda Architecture?
There are some reasons why you should choose lambda architecture for big data processing:
1. Scalability
Lambda Architecture is highly scalable and lets organizations handle growing volumes of data with additional computational resources.
2. Fault Tolerance
The architecture also brings redundancy and fault tolerance mechanisms that maintain data integrity and system reliability even when there are hardware failures or other issues.
3. Real-Time Processing
With the combination of batch and real-time processing, organizations can derive insights from historical and real-time data simultaneously.
4. Flexibility
Being a technology-agnostic architecture, it lets you choose the best-suited tools and technologies for specific use cases within each layer of the architecture.
5. Consistency
Batch views give a consistent and reliable source of truth for queries.
Challenges in Lambda Architecture
Though there are numerous benefits, lambda architecture also brings some challenges and considerations:
1. Complexity
Lambda Architecture can be complex to implement since it requires expertise in multiple tools and technologies.
2. Maintenance Overhead
With multiple layers, it might be hard to manage them and ensure synchronization. This can be resource-intensive which is a challenge for many.
3. Latency
Though the speed layer provides near-real-time processing, you can still experience some latency while delivering results compared to fully stream-based systems.
4. Data Consistency
It might be challenging to maintain data consistency between batch and real-time views.
Conclusion
Lambda Architecture is one of the powerful approaches to big data processing with the ability to handle large volumes of data while offering real-time processing capabilities and fault tolerance. If the architecture is implemented correctly, it has the potential to empower organizations to unlock valuable insights from their data and make data-driven decisions. However, it needs some careful consideration according to the needs of your organization. This helps later when you implement and maintain the architecture before adopting it for big data processing tasks.
I hope this article was helpful to you.
Please don’t forget to follow me!!!
Any kind of feedback or comment is welcome!!!
Thank you for your time and support!!!!
Keep Reading!! Keep Learning!!!
Posted on September 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related