Decision trees uncovered

Pol Monroig Company
Posted on August 6, 2020

If you are a computer scientist I am sure you agree with me when I say that trees are everywhere. And I mean everywhere! It is extremely common to use trees as a basic data structure to improve and define new algorithms in all sorts of domains. Machine learning is no different; decision trees are one of the most used nonparametric methods, it can be used for both classification and regression.
Decision trees are hierarchical models that work by splitting the input space into smaller regions. A tree is composed of internal decision nodes and terminal leaves. Internal decision nodes implement a test function, this function works by given a set of variables (the most used approach is to use univariate trees, that is trees that test only 1 variable at a given node) we get a discrete output corresponding to which child node we should go next. Terminal nodes correspond to predictions; a classification output might be the corresponding class, and a regression a specific numerical value. A great advantage of decision trees is that they can work using categorical values directly.
For example, in the following tree, we might want to classify patients that required treatment versus patients that do not require it. Each node makes a decision based on a simple rule, and in each terminal nodes, we have the final prediction. The gini index is a measure of how impure the node is. If the impurity is equal to 0.0, that means we cannot split any further because we have reached a maximum purity.
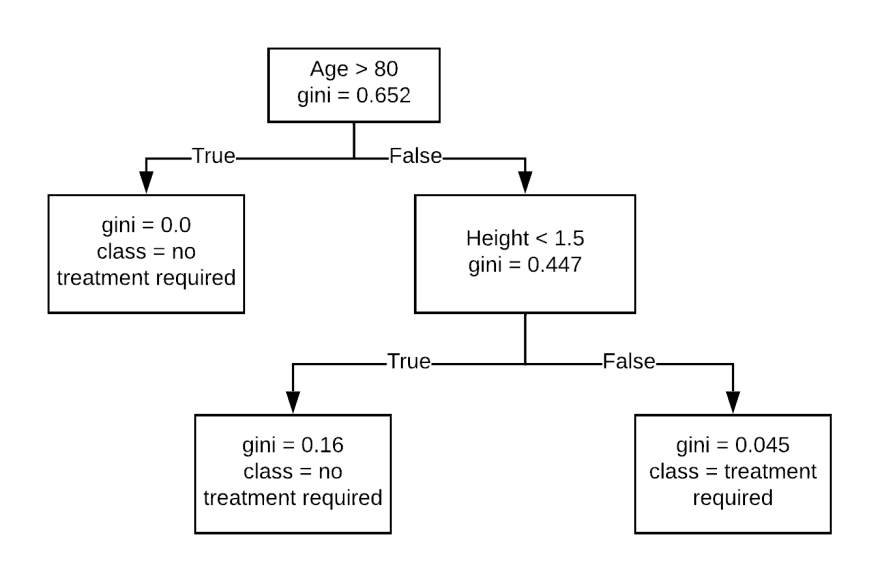
One of the perks of decision trees, compared to other machine learning algorithms, is that they are extremely easy to understand and have a high degree of interpretability. Just by reading the tree, you can make decisions yourself. On the other hand, decision trees are very sensitive to small variations in the training data, so it usually recommended to apply a boosting method.
Note: In fact, a decision tree can be transformed into a series of rules that can then be used in a rule-based language such as Prolog.
Dimensionality reduction
The job of classification and regression trees (CART) is to predict an output based on the possible variables that the input might have; higher leaves tend to divide more important features and lower leaves tend to correspond to less important ones. That is why decision trees are commonly used as a dimensionality reduction technique. By running the CART algorithm you get the importance of each feature for free!
Error measures
As any machine learning model, we must ensure to have a correct error function. It has been shown that any of the following error functions tend to perform well:
- MSE (regression): it is one of the most common error function on machine learning
- Entropy (classification): entropy works by measuring the number of bits needed to encode a class code, based on its probability of occurrence.
- Gini index (classification): Slightly faster impurity measure than entropy, it tends to isolate the most frequent class in its own branch of the tree, while entropy produces more balanced branches.
Note: Error functions on classification trees are also called impurity measures.
Boosting trees
Decision trees are very good estimators, but sometimes they can perform poorly. Fortunately, there are many ensemble methods to boost their performance.
- Random forests: bagging/pasting method that works by training multiple decision trees, each with a subset of the dataset. Finally, each tree makes a prediction and they are all aggregated into a single final prediction.
- AdaBoost: a first base classifier is trained and used to make predictions. Then, a second classifier is trained on the errors that the first one had. This continues on and on until there are no more classifiers to train.
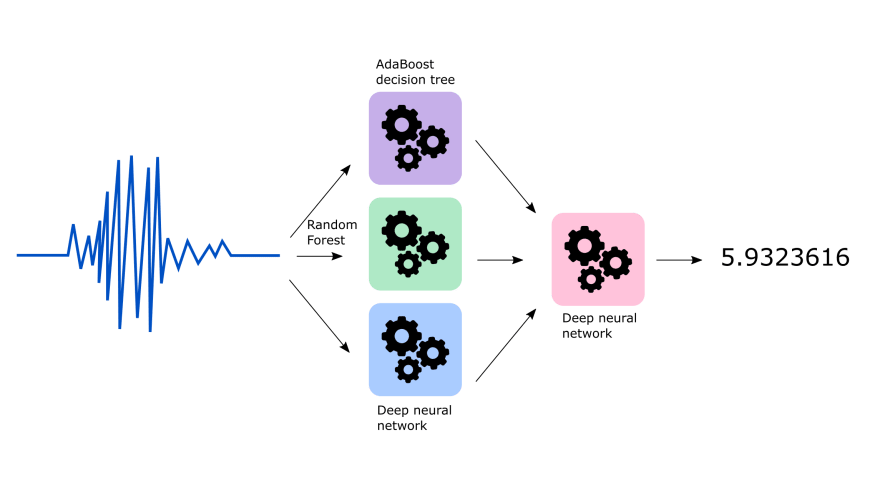
- Stacking: this idea works by creating a voting mechanism between different classifiers and create a blending classifier that is trained on the predictions of the other classifiers, instead of the data directly.
The following image represents a stacking ensemble:
Posted on August 6, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related