No more HTML coding, please. Let's make layout to HTML real

Pavel
Posted on July 11, 2020

Do you ever think that handwrote HTML code is expensive, long, redundant and outdated?
I think about it every day, when I create another GUI component or system element. This article is my attempt to overview the current state of the industry, its problems and share the results of my research.
Before we start
Wanna try it right now? Here is the proof of concept.
It shows the concept, it's missing implementation however I think the concept is proven. Details below.
This is my first English publication, please be lenient. Any fix suggestions are welcome.
Glossary
I use "HTML code" and what I mean by this is:
- As a HTML development process.
- As artifacts obtained after HTML development - HTML, CSS, JS, etc.
Intro
About 8 years ago, I expressed the idea that manual HTML coding is outdated and automation will replace it. From that moment, I have been intently searching for solutions to resolve this issue. We already have such tools as Workflow, Bootstrap Studio, inVision, Framer, Supernova, React Studio and many other direct or indirect solutions.
And we also have amazing research on this topic using neural networks, via pix2code or sketch2code.
Unfortunately, I can't find a tool that can be fully integrated into my development process.
So what I do I want? I want to get a layout from the layout designer, break it into components, correct the HTML code, where necessary, add logic, get a library of components and return it all to the designer for future interactions. I understand that it surpasses even the most advanced capabilities of the industry, but this is my dream…
Like Confucius said, the long journey begins with the first step, so I decided to figure out where to start. This is what this article will be about.
The Problem
Before all we should to determine the difference between HTML code and interface:
HTML code - is a semi-finished product, roughly speaking, the result of converting a graphic format to HTML, CSS and other files, intended for further conversion to a graphic interface.
Interface - a product ready artifact of the system with which users will interact.
At the 2020, manual HTML coding is still the main way to create web interfaces, which is quite interesting in itself. This goes against the trends of parallel stacks, such as native and desktop applications, where visual interface design tools are the standard for its creation.
We may argue for a long time why this is so, but as I think, the main conclusions are:
- high requirements for the final code and
- the need for low-level control
I propose to leave the "HTML coders lobby" outside the brackets :).
HTML coding is complex, requires the use of special techniques and tools to manage, minimize errors and support up to date.
Animations are other big question. Creating of complex animation can be impossible task for many companies because it's very laborious.
HTML coding is expensive, on average it's from 25% of the cost of the entire system for SPA and up to 75% for landing pages.
There is no generally accepted HTML coding theory as such.
The W3C standard is very wide and each developer / team is guided by their own rules and standards.
My solution
First We must to formalize the HTML coding process, define the entities, algorithm and rules. Of course, the topic itself is quite extensive, and its full disclosure is not the goal of this article. Based on this, we consider only the part that is currently interest.
Template
Let's try to define process of template creation.
Step 1
Visually divide into a high-level block tree.
Find the rows and columns of the layout.
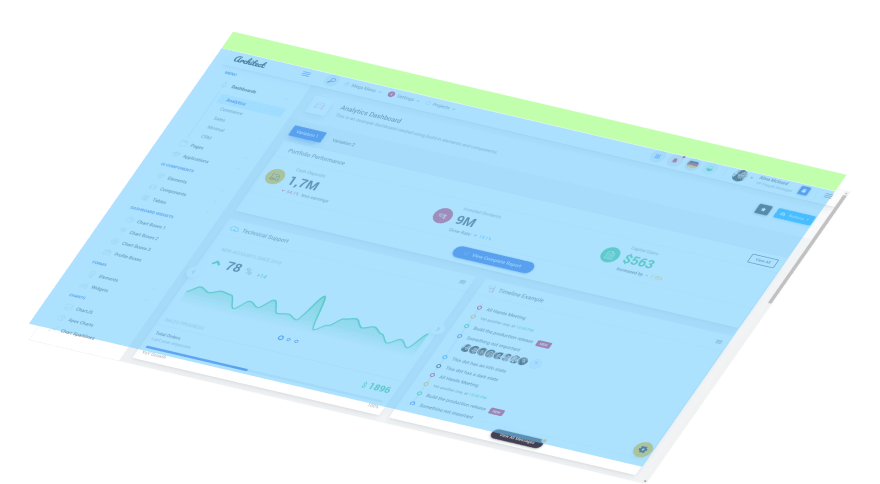
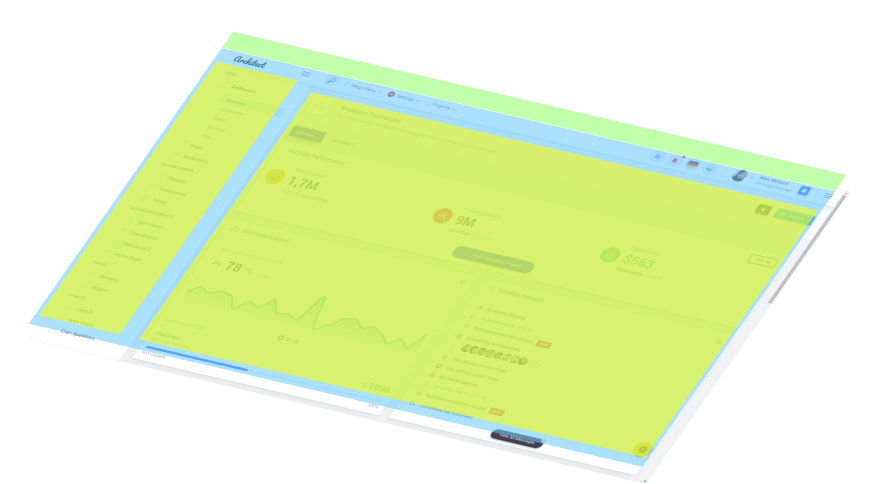
Step 2
Semantic analysis, we define the main blocks:
- Header
- Body
- Side bar
- Footer
- Etc…
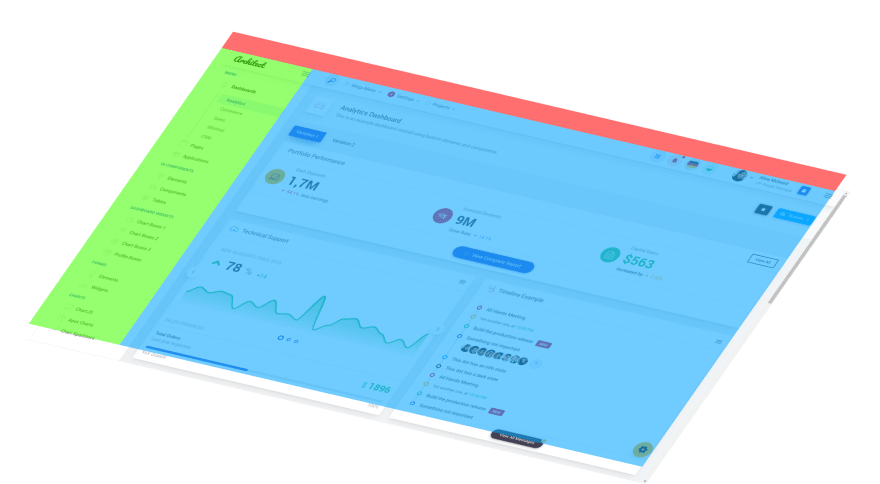
Here we immediately encounter an interesting phenomenon, a layout is not always enough to build a full-fledged structure, so the interface designer should clarify the behavior of the blocks. Which suggests the idea that semantic analysis is also not always enough.
And for now, this is enough for us. Here we can divide our task into two large groups:
- Technical and
- Semantic.
Let's set aside the semantic group for future research and focus on the technical one.
Despite the fact that the HTML code of a picture by a neural network is a very interesting task, in my opinion, it's redundant.
It is hard to imagine a situation when, in a normal workflow, an interface designer will send a layout in the format of a bitmap image.
Most often we have formats created in tools such as Figma, Sketch or Adobe Photoshop, which already contain almost exhaustive information about the layout, the most important thing:
- Elements position;
- Elements type;
- Elements styles;
Obtaining an HTML document based on this information is already a solved problem, as engineers from Figma have already shared their conversion implementation and research results, and services such as Anima are directly built on the synchronization of layouts and interface.
But why didn't such decisions lead to the effect of an exploding bomb and after 2 years there is nothing better than the good old hand-made HTML code?
Here I repeat my opinion the reason for this is two factors:
- High quality requirements
- Need for control
Control is undoubtedly a necessary thing, but without satisfying the first requirement, it does not really make sense. It will be easier to immediately implement and manage a high-quality HTML code than to try to fix a poor-quality one.
Thus, the first requirement is paramount. But what makes a code to be quality?
If we remove official quality indicators such as LTR, Accessibility and the like so, we will remain with important quality indicators for developers:
- Correct tree;
- Semantics;
- Non-redundancy;
- Readability and edibility;
- Using of blocks taken out of the stream only where it is needed.
Thus, the main task for automation will be compliance with these criteria.
Let's try to prove that this is possible by building a tree of blocks. Again, to do this, we need to formalize the process and introduce the necessary concepts. Leave a number of extreme cases for future research.
Rows and Columns
Rows
If the position of one element falls into the height segment of another, then they form one row.

Columns
Similarly, if the position of one element falls into a segment of the width of another, then they form one column.

Element Relations
Relative layout
Elements are positioned relative to each other, relying on the flow.
The tree is completed if necessary.

Overlapping layout
Overlapping elements break out of the flow, are positioned absolutely, do not affect the positioning of other elements.

The process of building a blocks tree
Step 1
Define all rows.

Step 2
Find margins of each rows.

Step 3
Select a row for work and determine the type of layout:
- Single-column;
- Multi-column;

Step 4
For multi-column, determine the type of columns:
- Floating;
- Grid;
Depending on the type, find indent between the columns.

Step 5
Determine the type of column by the number of elements in it:
- Single;
- Multiple.
If the type is single, position the element relative to the column, go to the next.

Step 6
For the column type "multiple" we find all the rows.
Rows types are similar to column types:
- Floating;
- Grid;
Find the margins.
We repeat the entire algorithm while there is at least one raw block.

And now we implement the obtained statements into the code.
Simplification:
- Fast implementation covering only ~ 20% of cases;
- Positioning errors are expected;
- One-level structure of source blocks;
- Styles are written to the style attribute;
You can see and play with the proof of the concept here.
Conclusion
Automation of high-quality HTML code is possible without involving weakly controlled machine learning algorithms. This will significantly reduce the cost of creating products and increase their quality. It is also important that this will simplify the work of developers and make its more intuitive and enjoyable.
But further research is needed, and the problem itself requires closer attention of the community to implement a fully functional model and tools based on it.
What's next?
I think the next important step is the confirmation of the concept of controllability. The main factor here will be converting the code to the layout. When the code is changed, the layout will also be updated - creating a two-way binding between the design tool and the HTML code.
It will be great to see any constructive criticism and the discussion. Peace!
Posted on July 11, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related