Writing self-documented code with low cognitive complexity

Anton Yarkov
Posted on July 11, 2021
In this article, I will share practical and straightforward advice on how to stop (holy wars) arguing about code quality and find measurable arguments about the necessity of refactoring, simplification, adding comments or documentation for the code. While I’m going to refer to exact commercial tools in the second half of the article, I should say that I’m not affiliated anyhow with the tool's authors. The tools are available via free community licenses as well as commercial licenses.
The goal of this article is not the tool itself but to tell you about useful metrics that will allow your team to write self-documented code, produce better software and improve the programmers life.
Self-documented code
I frequently get the answer "Go read the code" when I ask developers to provide documentation or explain their code. I'm sure I'm not alone. Many developers feel their code self-documented by default. Not many people understand that creating self-documented code is a complicated design task.
Why is that? Let's take a look into the way we read code:
- First, we are trying to figure out the aim of this code: WHAT was the task and the goal (and real experts also try to dig into WHY).
- Next, knowing WHAT, we are reading the code to understand HOW the author achieves this.
While it's possible to do vice versa, it's tough to do in any production solution. Production code tends to be complex due to additional requirements to integrate with other system components like monitoring, logging, or security; to be resilient, scalable, configurable; to support multiple platforms, versions, etc.
Some people claim that SQL and HTML answer both HOW and WHAT at the same time. I will let myself disregard this comment here and concentrate on general-purpose languages.
Doing vice-versa-analysis, software engineers should figure out what the purpose of this code is, WHAT it mainly does, and (finally) WHAT it missing. That is usually called Mental Model. Whenever how simple or complex it is, there is always some Mental Model underlying the code (even the bad one). It might be a domain model or any other way to express the thinking process. There are many concrete rules to follow to make your code more clean, readable, and understandable. As we know, there are many books has been written on this topic. But if to sum up all of this, there is only one way to write self-documented code: the developer should write the code to uncover the Mental Model and express important model parts while hiding unnecessary implementation details. Very frequently, developers focus on implementation details like frameworks, databases, protocols, and languages, and it makes the task of understanding the model very hard.
Questions HOW and WHAT are orthogonal because there are several ways to achieve the same goal. Imagine climbers analyze the better way to reach the mountain peak by different paths. They consider many various aspects, summing their own experience and common knowledge about the mountain relief, weather and air conditions, time of the year, the level of readiness of the group, etc. Finally, they select the optimal path to climb. Optimal path doesn't explain all of these aspects but allows the group to put the flag on the peak.

As I see it, the Mental model shows the explicit dependency of the self-documented code from the author's design skills that allow him to make code more readable.
Mental model answers to a question the WHAT, while code is telling the HOW.
As I see it, the Mental model shows the explicit dependency of the self-documented code from the author's design skills that allow him to make code more readable.
Measuring readability of the code
Frederick Brooks, in his famous paper No Silver Bullet – Essence and Accident in Software Engineering specified two types of Complexity:
- Essential complexity – is caused by the problem to be solved, and nothing can remove it
- Accidental complexity – relates to the problems which engineers create and can fix.
Many years have passed, but we still cannot measure it precisely. The well-known metric Cyclomatic Complexity (invented in 1976) tightly relates to the lines of code. While it's an excellent way to measure code coverage, it is not a way to measure ComplexityComplexity. Here is the problem showcase:

As you can see, Cyclomatic Complexity shows the same digits for the code from left and right. However, from the developer's viewpoint, left and right pieces of code are not identically complex. The left one is harder to read and to understand. We may believe the code is finding Sum of Prime Numbers which is a famously known problem. But an experienced developer will never think it solves the task until he verifies that it's true:
- Is the name of a method clearly states what the code is doing?
- Is code achieving the mission?
- Is code missing some use cases, and what are they? (i.e., what are the limitations of the code?)
- Etc.
Now, imagine how hard it is to understand something more specific to the domains not very famous to others. Sonar Source released the Cognitive Complexity metric in 2017, and not many people know about it. However, I believe this is groundbreaking work that has to be widely adopted. As we can see, it works perfectly for the described example:

You can find all the details in their paper, and on youtube. But telling short, the metric is based on three rules:
- Ignore structures that allow multiple statements to be readably shorthanded into one.
- Increment (add one) for each break in the linear flow of the code
- Loop structures: for, while, do while, ...
- Conditionals, ternary operations, if, #if, #ifdef
- Increment when flow-breaking structures are nested
You can find this metric using the static code analysis tools produced by Sonar Source (SonarQube, SonarCloud, and its freely available SonarLint IDE extension). SonarQube is available in free community edition.
In Sonar Cloud look into Project -> Issues -> Rules -> Cognitive Complexity

It is easy to find the full report with the line-by-line explanation of the penalty assignment:
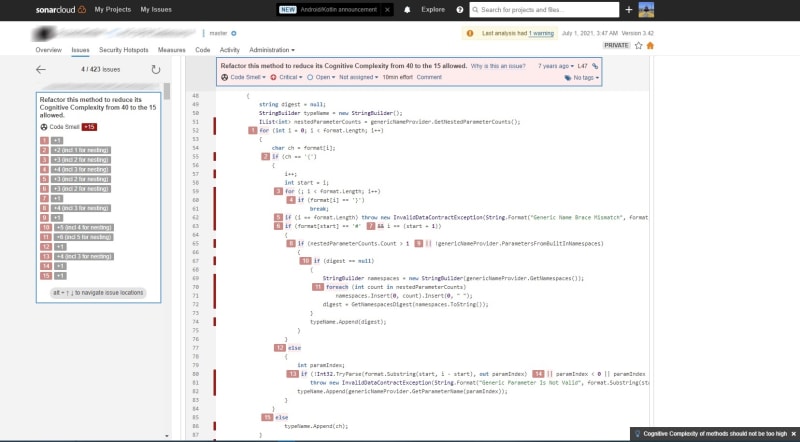
The default thresholds for code quality are:
- Cognitive Complexity
- 15 (most of the languages)
- 25 (C-family languages)
- Cyclomatic Complexity = 10 (all languages)
It's essential to know both Cyclomatic and Cognitive Complexity thresholds since one metric might be larger than the other and vice versa. Let’s take a look into a simple production example (here is how to find it: Sonar Cloud -> Measures -> select Complexity filter):
You can find the total complexity measurement for the group of files (folder) on the left side, and here we can see twice times difference: 134 against 64. You can see file-by-file differences as well. LoggerHelper file isn't so bad in Cyclomatic Complexity, but there are ways to improve its Cognitive Complexity. And for other files, we may see a controversial picture: Cyclomatic Complexity is bigger than Cognitive one.
Outcomes
It looks like we have a way to measure code complexity, and I wish more tools to implement this, but we already can start using this quickly and straightforwardly. The Cognitive Complexity metric still doesn't tell us how good code is expressing the mental model, but it is already excellent data for you to start moving towards good software. Using these metrics, you can start building a transparent dialogue between development and business on necessary resources and roadmaps for better code and product quality:
- Measure cognitive Complexity Complexity in all parts of your codebase to assess how hard it is to introduce new developers, implement and deliver new changes, etc.
- Use measurable goals for planning your development cycles and any activities for improving your code, like refactorings.
- Prioritize improvements for the most critical parts of your codebase.
- See the places that should cover with additional documentation.
- Stop arguing and holy waring, conflicting, and stressing with colleagues on code quality.
- Make the life of your colleagues more fruitful (everyone wants to achieve results on their task as quickly as possible and then meet with friends and family).
I hope I shared some exciting food for you to start digging into this and use Cognitive Complexity in everyday programmer's life.
Posted on July 11, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.