KAFKA - PRODUCER API WITH THIRD PARTY TOOLS

RaghuNandan Neerukonda
Posted on June 23, 2020
This is a continuation write-up to the previous post - Kafka - Playing with Consumer API, where I covered some peculiar use-cases of Consumer API.
Here, I would like to play with Producer API to create a message using third-party tools like MessagePack for serialization and KafDrop for monitoring
MessagePack
MessagePack is one of the best available schemaless serialization libraries to interchange data between heterogeneous applications. It is a binary for simple data structures and designed for efficient transmission over the wire.
Code Snippets
Following examples shows how to pack and unpack the common data types, to work with custom data types like datetime.datetime, check DateTime example
- Simple Example
from msgpack import packb, unpackb
data = {'a': 5}
msg_packet = packb(data)
recreated_data = unpackb(msg_packet)
- Using Datetime
from datetime import datetime as dtm
from dateutil import parser
def dtm_encode(obj):
if isinstance(obj, dtm):
return {
'__dtm__': True,
'obj_as_str': obj.isoformat()
}
return obj
def dtm_decode(obj):
if '__dtm__' in obj:
return parser.isoparse(obj['obj_as_str'])
return obj
dat = {'a':5, 'dates': {'created_at': dtm.now()}}
serialized_dat = packb(dat, default=dtm_encode)
deserialzed_dat = unpackb(serialized_dat, object_hook=dtm_decode)
Why serialize the messages?
Serialization is the process of transforming an object into a format that it can be stored, at the destination the data can be deserialized to recreate the original object. Since Kafka uses the filesystem to store the messages, we need to serialize and deserialize the data. There are two protocols to serialize a message either by using Schema-based IDL(Interface Definition Language) or using Schemaless. While you can find numerous articles touching these protocols on the web, I have constituted a one-liner differentiating them.
Schemaless and Schema-based IDL
In Schema-based IDL, the primitives of the message are pre-defined where publishers and consumers can validate the message before working on it. On the other hand, schemaless can have custom primitives for every message.
If you're having a standard and rigid database schema, you might want to use Apache Avro which is the best fit and popularly used in combination with Apache Kafka. In contrast, if you're working with schemaless or bigdata oriented systems where primitives are highly unpredictable, there is an overhead of maintaining the Avro schemas, and the need for schemaless IDL arises.
These are some of the standard protocols most commonly chosen.
| Protocol | Type |
|---|---|
| Thrift | Schema Based |
| Avro | Schema Based |
| JSON | Schemaless |
| MessagePack | Schemaless |
| BSON | Schemaless |
I chose MessagePack among the list because it has an incredible performance, super simple to setup and start working with, and also much smaller and faster than JSON.
KafDrop
Kafdrop is an opensource web UI for viewing Kafka topics and browsing consumer groups. The tool displays information such as brokers, topics, partitions, consumers, and lets you view messages.
Example screen how a KafDrop looks like
- Home Screen Home Screen not only covers the overview, but it also has information about the Brokers and topics available in the cluster

- Topic Page Reveals all partitions info of the topic and renders the list of consumer groups subscribed to the topic

Features
- List all topics of the cluster
- Option to browse through a partition data of a topic
- Tracks message offsets of all consumer groups subscribed to a topic
- Create & Delete topics
- Search and filter messages in a partition
Produce a Message and see in Kafdrop
from datetime import datetime as dtm
from msgpack import packb, unpackb
from confluent_kafka import Producer
'''
Note: Import or recreate "dtm_encode" function from the Code Snippet section
'''
def delivery_report(err, m):
if err is not None:
print(f'Message -{m}, delivery failed: {err}')
else:
print(f'Message delivered to {m.topic()} [{m.partition()}]')
producer_config = {
'bootstrap.servers': '172.16.6.9'
}
producer_topic = 'raghu-producer-test'
P = Producer(producer_config)
data = {
'a':5,
'created_at': dtm.now()
}
data_packet = packb(data, default=dtm_encode, use_bin_type=True)
P.produce(
producer_topic,
value=data_packet,
callback=delivery_report,
)
P.poll(0.01)
Note: Refer code samples in my GitHub repo
Snapshot of Kafdrop
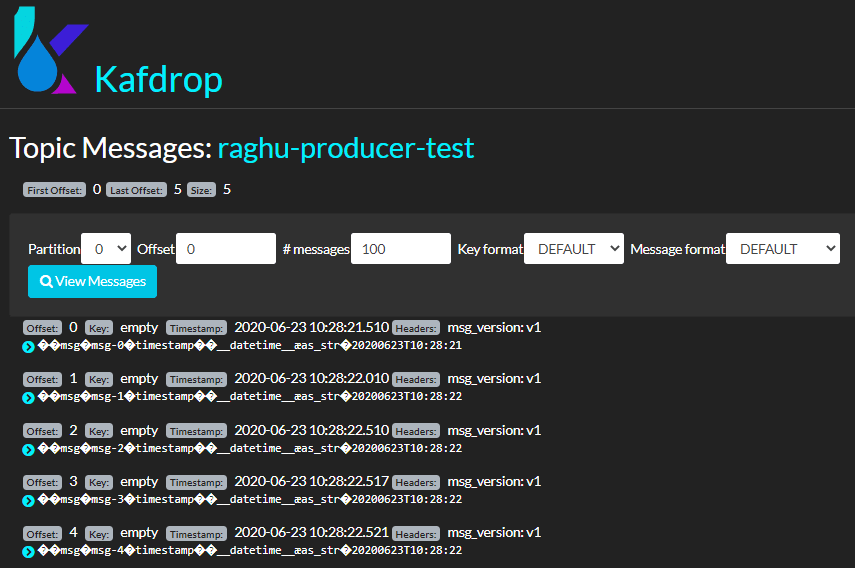
Best Practices
Before we close, I would like to mention some of the best practices
Compression reduces the packet size and helps to transmit much faster over the network, however, MessagePack shrinks the packet size by 30% which acts as compression and made me stay away from conventional compression libraries. Most standard workflows are designed using a compression mechanism, snappy & zlib are most widely accepted libraries for compression.
Encryption, which I more prefer than compression, is a good practice to ensure the data is secured over the network. It is not a tedious task to encrypt messages before pushing to Producer and decrypt at the Consumer end. There are lots of key-based encryption system which helps us to encrypt and decrypt the packets.
For my requirement, we have developed a thin wrapper on cryptography library to encrypt and decrypt messages using hybrid mechanism(Symmetric + Asymmetric), this functions like any other microservice to encrypt and decrypt the messages.Message Headers, it is not an uncommon practice to incorporate headers in the message for several technical or architectural purposes. My team use headers to identify the version of the message, however, expect a new use-case with headers, refer the case to learn more.
Posted on June 23, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.