
mychal
Posted on January 12, 2020

What is GraphQL?
GraphQL is a query language initially developed at Facebook before being open sourced in 2015. It was created to solve some of the issues associated with RESTful architecture and provide finer-grain control over what data is being requested and returned.
In addition, GraphQL is agnostic about the sources of data, so it can facilitate the retrieval of data from various APIs or even expose your APIs directly.
We'll discuss the trade-offs of GraphQL and create a simple project so we can familiarize ourselves with the syntax. Let's get started!
Comparison with REST
One of the easiest ways to understand the power of GraphQL is to compare it to REST. If you're also new to REST, you can check out this resource to learn more, but at a high-level just know that REST is an architectural paradigm that provides guidelines of how resources should be accessed and served up to clients. It is immensely popular for building web applications.
REST's popularity is not without merit, it certainly has proved itself to be more than capable of powering some of the largest sites on the internet. However, as the web continues to evolve, spurred by the hockey-stick growth of mobile users, the limitations of REST are beginning to manifest and developers are looking for ways to optimize.
Issue 1: Too many routes
Consider the following...Suppose we want to fetch a user's post and the comments associated with it:

In a RESTful Node.js application, we might set up a route like the one below:
const express = require('express');
const router = express.Router();
// Middleware that will query our database and pass data along to our route handler
const dbController = require('../controllers/db');
// GET postById route
router.get('/post/:id', dbController.getPostById, (req, res) => {
res.json({
confirmation: 'success',
postId: res.locals.postId,
postBody: res.locals.body,
userId: res.locals.userId,
profilePicURL: res.locals.profilePicURL,
timestamp: res.locals.timestamp
});
In order to get the comments, we'll need to hit another endpoint:
// GET commentById route
router.get('/comment/:postId', dbController.getCommentsByPostId, (req, res) => {
res.json({
confirmation: 'success',
comments: res.locals.comments
});
})
Now say we want to add a comment of our own, we'd need to add a POST route. To edit a post, we'll need a separate route to handle PUT requests. Ditto for updating any existing comments...You can see how for every interaction we have with our app, we'd need to set up a corresponding route.
This works, but can become cumbersome as our list of routes continues to grow. In addition, if the front end team wants to change the data they're displaying, they'll have to ask the back end team to change the API.
GraphQL, on the other hand, only has one URL endpoint (conventionally something like '/graphql'). The logic for what happens is built into the resolver functions (more on those later).
One Endpoint to Rule Them All
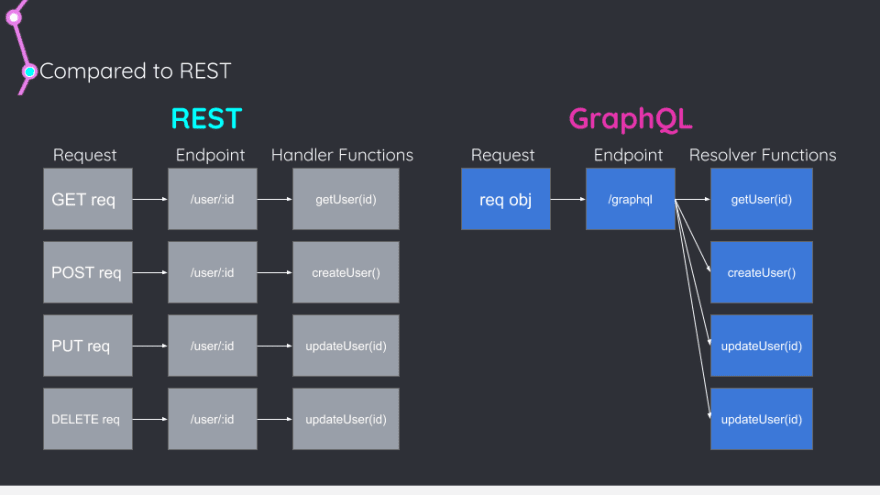
To handle CRUD in REST, we need a separate endpoint and functions to handle what happens when we hit that end point. In GraphQL, all queries and mutations hit one URL and the functions to resolve those requests are handled individually.
Issue 2: API versioning
Another issue a company may face is when they want to make changes to their public facing API, they run the risk of breaking applications that are expecting the data to be returned in a certain way. The workaround for this involves creating multiple versions of an API, hence why you'll see some APIs labeled v1, v2, v3, etc. This adds some complexity and overhead for the team maintaining the API.
With GraphQL, more features can be added without worrying about breaking changes since all existing queries will still be resolved as expected and any new changes can still be accessed by clients wishing to implement them.
Issue 3: Over-fetching/Under-fetching
Additionally, if you only need one piece of data that an existing route provides, there's no way in REST to only fetch the data you want without creating another custom route. You're getting the entire response object and only utilizing pieces of it. This problem is known as over-fetching and means you're paying to send over data you don't need which in turn sacrifices speed.
The flip-side to this is known as under-fetching, which happens when a route doesn't provide all the data that's needed to render by the client so another trip to the server is required. Sort of like in our post example above. Multiple round-trips to the server are problematic because again it introduces unnecessary latency which results in a worse user experience.
GraphQL solves this by letting the client specify exactly what data it needs and the server can then wrangle this data from any source and return it all in one response. Pretty cool, huh?
Disadvantages
Caching
While GraphQL has many benefits, it does also come with some trade-offs. For example, caching is not as straightforward with GraphQL as it is in REST, since its queries lack some type of built-in, globally unique identifier like a URL to delineate which resources are being accessed frequently. It also doesn't play as well with HTTP caching, since many implementations of GraphQL in the wild only rely on one type of request (typically a POST).
Rate Limiting
Another issue to consider is rate limiting. For public-facing APIs, companies will often limit the number of requests clients can make to a particular resource for a given period of time. This is easier in REST since each endpoint can be limited separately. With a GraphQL API, a company may need come up with their own rate limiting calculations. These can quickly grow in complexity as it can be difficult to predict if a GraphQL request will result in a costly operation or not since it's up to the client to specify what data they need.
Performance
While GraphQL's flexibility is one of its main selling points, it can also result in performance issues. Deeply nested queries can take time to resolve, which could add unexpected latency for end users. This is something that needs to be weighed against alternative approaches, such as making multiple round-trips to the server, which adds more network latency but may reduce overall server workload.
A Quick Example
So now we know some of the pros and cons of GraphQL, let's roll up our sleeves and try it out. We'll be building a very simple book library and write some queries to look up some books.
First, let's create a project directory and cd into it. We'll use npm to scaffold a Node.js project (the -y flag means to accept all the defaults). We'll also install three packages, express, graphql, and express-graphql, to set up our GraphQL service.
mkdir graphql-example
cd graphql-example
npm init -y
npm i -S express graphql express-graphql
Let's create an index.js file where will write our server logic. First we'll require in express and bootstrap our app. Note, our service won't work until we define a route handler and import our schema, both of which we'll do shortly.
graphql-example/index.js
const express = require('express');
const app = express();
const { buildSchema } = require('graphql');
const graphqlExpress = require('express-graphql');
// Initialize an array where we'll store our books
const books = [];
// We'll insert our /graphql route handler here in just a second. For now, our server won't do anything interesting.
// Our server will listen on port 4000;
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Listening on port ${PORT}`);
});
I mentioned our app isn't fully functional yet. Let's fix that. Create another file called bookSchema.js. In it we'll export a string listing out our types. But first, we need to discuss how to write GraphQL schemas.
Types
In GraphQL, we define types as any object we can fetch from our service. For our library app, we may define a book type like so:
example book type definition
type Book {
title: String!
author: String!
}
There are three different ways to represent a GraphQL schema, but for our purposes we'll stick to the one that's easiest to read/write: the Schema Definition Language (or SDL). The snippet above is an example of SDL. If you're interested in the other ways, check out this article.
There are two special types in GraphQL: query and mutation. Every GraphQL service will have a query type, because GraphQL needs an entry point for each request it receives. Mutations, like their name suggests, deal with how we change (or mutate) our data.
So in our newly created bookSchema file, let's add the following code:
graphql-example/bookSchema.js
module.exports.types = `
type Query {
greeting: String
books: [Book]
}
type Book {
id: Int!
title: String!
author: String!
}
`
Here we just defined Query, our root object, and also a Book object. Query has two fields, greeting which returns a string, and books which will return a list of Book objects. Each Book will itself contain three fields that are all required (i.e. they can't return null) as denoted by the bang.
Resolvers
So GraphQL types tell us what our data will look like and what kinds of queries our client can send. How we actually return that data is handled by specific functions, known as resolvers, that correspond to each type. Their job is to resolve queries and mutations with the values that they return.
Let's jump back into our index.js file and require in our types and write some resolvers.
- Use destructuring to require in our types string from bookSchema.js
- Next, right below where we declared the empty books array, declare a constant called resolvers which will be an object containing two keys, each with their own function.
- Then create a route handler for our '/graphql' endpoint where our previous comments had specified. Here's where we'll use the graphqlExpress package.
- Finally, create a variable called schema and call the buildSchema method that the graphql library provides, passing in our types string that we just imported.
Our index file should now look like this:
graphql-example/index.js
const express = require('express');
const app = express();
const { buildSchema } = require('graphql');
const graphqlExpress = require('express-graphql');
const { types } = require('./bookSchema');
// Initialize an array where we'll store our books
const books = [];
const resolvers = {
greeting: () => 'Hello world!',
books: () => books
}
const schema = buildSchema(types);
app.use('/graphql',
graphqlExpress({
schema,
rootValue: resolvers,
graphiql: true
})
);
// Our server will listen on port 4000;
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Listening on port ${PORT}`);
});
Now it's finally time to write our first GraphQL query. Fire up the server by executing the node index.js command in the terminal. If there are no bugs, it should log:
Listening on port 4000
Now open up your browser and navigate to localhost:4000/graphql. We should see the GraphiQL IDE immediately load.

Delete all the commented text and write a query to retrieve our greeting (see screenshot below). Hit the play button (or ctrl + enter) and we should get back a response:
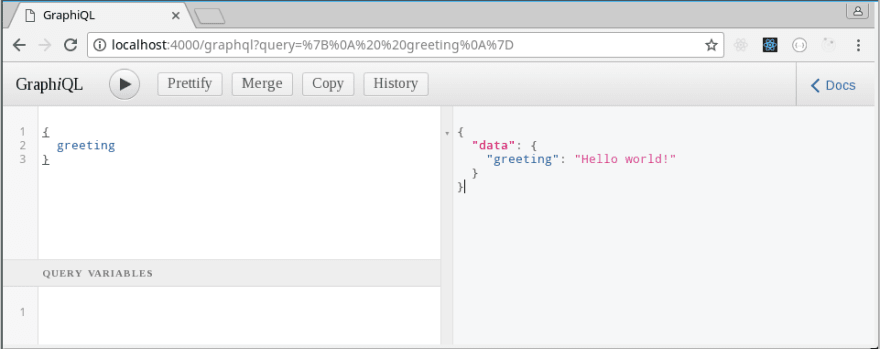
Awesome! We've just written our first GraphQL query! This example still lacks functionality, so let's go ahead and add our a Mutation type in order to interact with our mock library API.
Open up our bookSchema.js file and append the following string just after the type Book block:
graphql-example/bookSchema.js
type Mutation {
addBook ( id: Int!, title: String!, author: String! ): [Book]
}
Here we're defining our root Mutation and giving it an addBook field, which has three required parameters and returns an array of Book objects.
In order to give our addBook mutation some functionality, we'll need to create a corresponding resolver function. Head back to index.js and update our resolvers object as follows:
const resolvers = {
greeting: () => 'Hello world!',
books: () => books,
addBook: args => {
const newBook = {
id: args.id,
title: args.title,
author: args.author
};
books.push(newBook);
return books;
}
}
Ok, so here we have our first resolver that takes in an argument, creatively called args. In reality, all resolver functions actually receive four arguments as inputs. They are typically called:
- parent/root - The result of the previous (or parent) resolvers execution. Since we can nest queries in GraphQL (like nesting objects), the parent argument gives us access to what the previous resolver function returned.
- args - These are the arguments provided to the field in the GraphQL query. In our case, args will be the id, title, and author of the new book we wish to add.
- context - An object that gets passed through the resolver chain that each resolver can write to and read from (basically a means for resolvers to communicate and share information).
- info A value which holds field-specific information relevant to the current query as well as the schema details. Read more about it here.
However, since our two previous resolvers (greeting and books) were fairly trivial and didn't need access to anything the four arguments provide we simply omitted them.
Let's test out our addBook functionality. Spin up the server again and open the browser. Then execute the following mutation: 
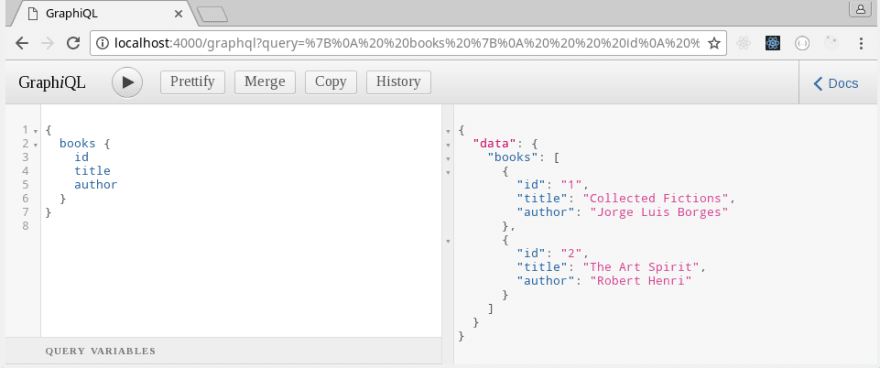
Pretty cool, huh? We just pushed a new book to our previously empty books array. We can verify this with our books query by executing the following in GraphiQL:
{
books {
id
title
author
}
}
If run another addBook mutation, this time with a different id, title, and author, and execute the books query again, we should see our books array grow to two objects.
Let's add one more piece of functionality before wrapping things up. Head back to the bookSchema.js file and add a field called deleteBook within the Mutation block. Our file should now look like this:
graphql-example/bookSchema.js
module.exports.types = `
type Query {
greeting: String
books: [Book]
}
type Book {
id: Int!
title: String!
author: String!
}
type Mutation {
addBook ( id: Int!, title: String!, author: String! ): [Book]
deleteBook ( id: Int, title: String ): [Book]
}
`
And append the following function definition to the resolvers object:
graphql-example/index.js
deleteBook: args => {
if (args.id) {
books.forEach( (book, index) => {
if (book.id === args.id) {
books.splice(index, 1);
}
});
}
if (args.title) {
books.forEach( (book, index) => {
if (book.title === args.title) {
books.splice(index, 1);
}
});
}
return books;
}
When we call the deleteBook mutation, we'll pass it either the id or title of the book we want to remove. Our deleteBook resolver will loop through our entire array and find the object whose property matches the argument and splice it out of the array, subsequently returning the modified books array.
Here is what both files should ultimately look like:
graphql-example/index.js
const express = require('express');
const app = express();
const { buildSchema } = require('graphql');
const graphqlExpress = require('express-graphql');
const { types } = require('./bookSchema');
// Initialize an array where we'll store our books
const books = [];
const resolvers = {
greeting: () => 'Hello world!',
books: () => books,
addBook: args => {
const newBook = {
id: args.id,
title: args.title,
author: args.author
};
books.push(newBook);
return books;
},
deleteBook: args => {
if (args.id) {
books.forEach( (book, index) => {
if (book.id === args.id) {
books.splice(index,1);
}
});
}
if (args.title) {
books.forEach( (book, index) => {
if (book.title === args.title) {
books.splice(index, 1);
}
});
}
return books;
}
}
const schema = buildSchema(types);
app.use('/graphql',
graphqlExpress({
schema,
rootValue: resolvers,
graphiql: true
})
);
// Our server will listen on port 4000;
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Listening on port ${PORT}`);
});
graphql-example/bookSchema.js
module.exports.types = `
type Query {
greeting: String
books: [Book]
}
type Book {
id: Int!
title: String!
author: String!
}
type Mutation {
addBook ( id: Int!, title: String!, author: String! ): [Book]
deleteBook ( id: Int, title: String ): [Book]
}
`
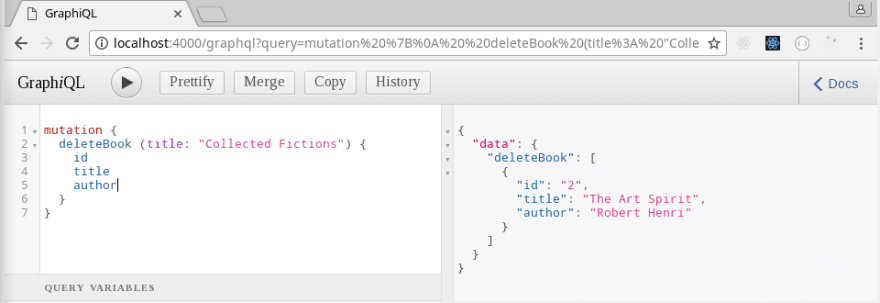
Finally, we'll test drive it in GraphiQL. Restart the server and run the addBook mutation twice, changing the values each time. Verify there are two different books in our array with the books query.
Now we can call deleteBook and pass in either the title or id of one the books. With any luck, the matching book should be removed from our array, leaving the other book as the lone object.
If it works, congrats! We're now starting to see how GraphQL can be implemented where we typically might build out a RESTful API.
As I previously mentioned, one of the benefits of using GraphQL is you can specify exactly what data you want to receive back. So for example, if we only needed the title to be returned and didn't care about the id or author, all we'd need to do is adjust our query/mutation from the client and 🔥BOOM🔥 we get back our data in exactly the shape we want.

GraphQL gives us fine-grain control over the shape of our data without having to change the back end API
Compare that to REST, where we'd have to also adjust our back end API for every change (and run the risk of breaking some downstream apps in the process). Pretty powerful stuff!
Recap
With our add and delete functions working, we're halfway to a basic CRUD app. For additional practice, try adding functionality to getBookById and updateBook on your own. I should also note that our books are only being saved in-memory so they'll be erased each time we restart the server. In order to make changes persistent, we'd need to hook up our app to a database, which is beyond the scope of this introduction, but something I recommend trying to implement as well.
So there you have it, a brief tour of GraphQL. Ostensibly, there is much more to GraphQL than we're able to touch on here, but hopefully this demo was enough to spark your interest.
If you want to continue learning about GraphQL, you're in luck. The community has created some phenomenal resources. Here are just a few that I recommend:
Leave a comment below if you have any questions or thoughts. Happy hacking!
Posted on January 12, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.