Ingesting Internet Data into Quine Streaming Graph

Michael Aglietti
Posted on May 31, 2022

The previous article in this series (Quine Ingest Streams) introduced the ingest stream and the basic structure for for creating them. In this article, I go deeper, exploring the ingest query and its role in the ingest stream.
A quick review of ingest streams:
- An ingest stream connects Quine to data producers.
- Ingest streams use backpressure to avoid becoming overloaded.
- Data is transformed by the ingest query into a streaming graph.
- Using
idFromallows us to act as if all nodes in the graph already exist. - Ingest streams are created either by API calls or Recipes.
For this article, we use the built in wikipedia recipe as a starting point.
Defining an Ingest Stream
The wikipedia page ingest recipe defines an ingest stream that receives updates from the mediawiki.page-create event stream.
Here's a copy of the ingest stream from the recipe.
ingestStreams:
- type: ServerSentEventsIngest
url: https://stream.wikimedia.org/v2/stream/page-create
format:
type: CypherJson
query: |-
MATCH (revNode) WHERE id(revNode) = idFrom("revision", $that.rev_id)
MATCH (dbNode) WHERE id(dbNode) = idFrom("db", $that.database)
MATCH (userNode) WHERE id(userNode) = idFrom("id", $that.performer.user_id)
SET revNode = $that, revNode.type = "rev"
SET dbNode.database = $that.database, dbNode.type = "db"
SET userNode = $that.performer, userNode.type = "user"
WITH *, datetime($that.rev_timestamp) AS d
CALL create.setLabels(revNode, ["rev:" + $that.page_title])
CALL create.setLabels(dbNode, ["db:" + $that.database])
CALL create.setLabels(userNode, ["user:" + $that.performer.user_text])
CALL reify.time(d, ["year", "month", "day", "hour", "minute"]) YIELD node AS timeNode
CALL incrementCounter(timeNode, "count")
CREATE (revNode)-[:at]->(timeNode)
CREATE (revNode)-[:db]->(dbNode)
CREATE (revNode)-[:by]->(userNode)
This ingest stream has three elements, type, url, and format. The type declaration for an ingest stream establishes the structure for the ingest stream object definition. This ingest stream is a ServerSentEventsIngest stream.
Reviewing the ServerSentEventsIngest schema documentation from the API docs provides us with the schema that we need to follow for the ingest stream definition.
The schema definition will default to File Ingest Stream when first opened.
Be sure to click on the down arrow 🔽 next to File Ingest Stream and select Server Sent Events Stream from the drop down to view the correct schema.
Here's the schema for a ServerSentEventsIngest.
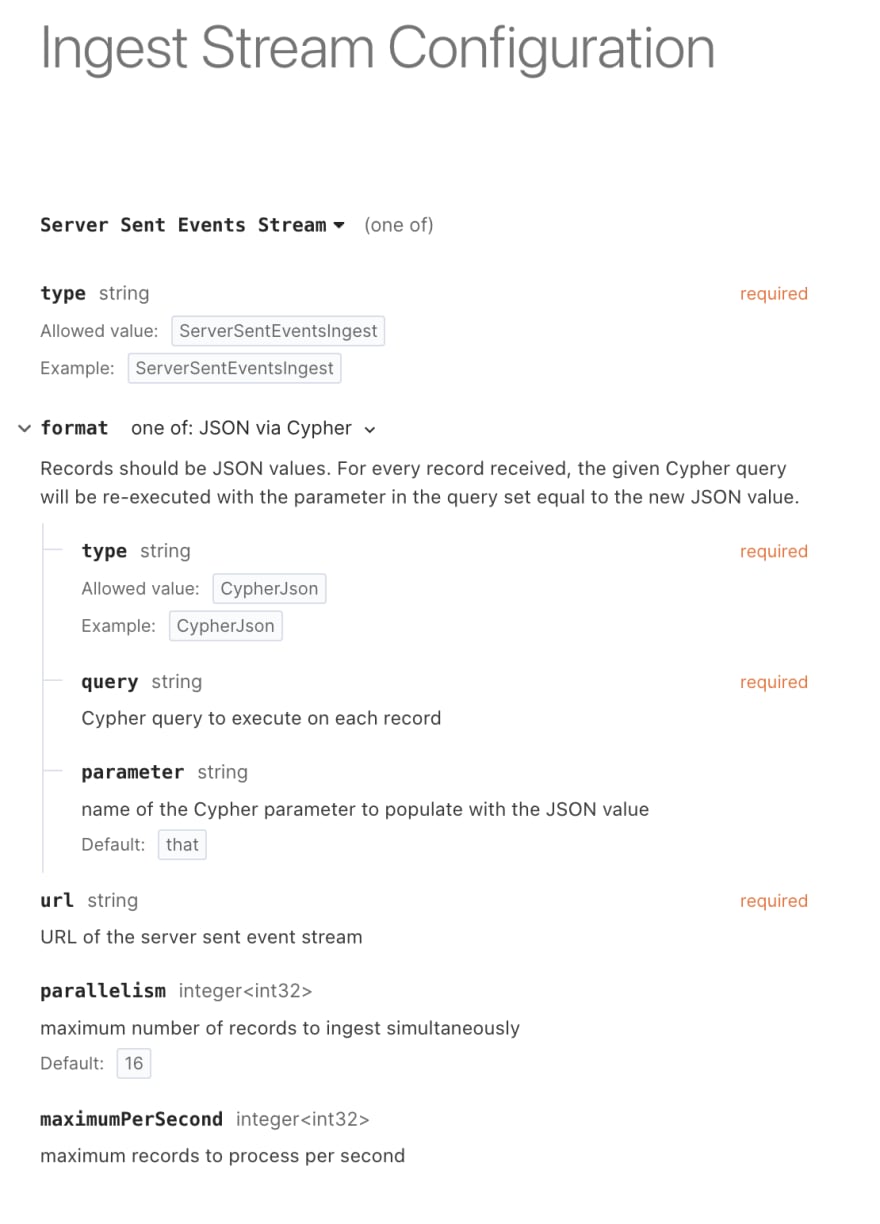
The structure of the ServerSentEventsIngest stream is pretty straight forward.
-
typespecifies the schema type for the ingest stream -
formatdefines what the ingest stream will do with each line it receives-
typeidentifies the line format in the stream -
querydefines the Cypher ingest query -
parametername of the parameter to store the current datum
-
-
urldefines the connection URL for the data producer -
parallelismandmaximumPerSecondtune the bandwidth for the ingest stream and when to apply backpressure
Wikipedia page-create Data
Quick aside, we need to understand the data that we are working on before we start pulling the ingest query apart.
Here's a sample page-create json object to review. View more samples by visiting the Wikipedia event streams page, selecting the mediawiki.page-create stream, then clicking the green "Stream" button.
{
"$schema": "/mediawiki/revision/create/1.1.0",
"meta": {
"uri": "https://en.wikipedia.org/wiki/Established_population",
"request_id": "85b7bd4b-23a5-4c20-84a1-d89430c21f6c",
"id": "8a34f1c0-a276-4a2b-ae2e-305f8822011c",
"dt": "2022-05-20T16:43:34Z",
"domain": "en.wikipedia.org",
"stream": "mediawiki.page-create",
"topic": "eqiad.mediawiki.page-create",
"partition": 0,
"offset": 231788500
},
"database": "enwiki",
"page_id": 70828723,
"page_title": "Established_population",
"page_namespace": 0,
"rev_id": 1088883819,
"rev_timestamp": "2022-05-20T16:43:33Z",
"rev_sha1": "d9uoc7gw3cj3ejhs8ihvsi61hp54icq",
"rev_minor_edit": false,
"rev_len": 82,
"rev_content_model": "wikitext",
"rev_content_format": "text/x-wiki",
"performer": {
"user_text": "Invasive Spices",
"user_groups": [
"extendedconfirmed",
"*",
"user",
"autoconfirmed"
],
"user_is_bot": false,
"user_id": 40272459,
"user_registration_dt": "2020-09-30T23:11:08Z",
"user_edit_count": 9319
},
"page_is_redirect": true,
"comment": "#REDIRECT [[Naturalisation (biology)]] {{R cat shell| {{R from related topic}} }}",
"parsedcomment": "#REDIRECT <a href=\"/wiki/Naturalisation_(biology)\" title=\"Naturalisation (biology)\">Naturalisation (biology)</a> {{R cat shell| {{R from related topic}} }}",
"rev_slots": {
"main": {
"rev_slot_content_model": "wikitext",
"rev_slot_sha1": "d9uoc7gw3cj3ejhs8ihvsi61hp54icq",
"rev_slot_size": 82,
"rev_slot_origin_rev_id": 1088883819
}
}
}
Take a moment to get familiar with the page-create schema from the wikipedia API documentation. The sample object is a bit messy for us to really see what is going on, so let's clean it up a bit. Showing just the keys from the object with jq makes it much easier to plan our ingest query.
❯ jq '. | keys' /tmp/data.json
[
"$schema",
"comment",
"database",
"meta",
"page_id",
"page_is_redirect",
"page_namespace",
"page_title",
"parsedcomment",
"performer",
"rev_content_format",
"rev_content_model",
"rev_id",
"rev_len",
"rev_minor_edit",
"rev_sha1",
"rev_slots",
"rev_timestamp"
]
The mediawiki recipe is an example use case for the reify.time user function. It creates temporal nodes in the graph and relationships with the page-create nodes based on the rev_timestamp.
By demonstrating the reify.time function, our ingest query creates revision nodes, db nodes, and user nodes that are related to each other and their representative time nodes.
To learn more about creating time-series nodes in Quine, read about time reification here.
The Ingest Query
The ingest query is the workhorse of the ingest stream. Each datum, the page-create object in this case, is processed by the ingest query. The query is written in Cypher and is responsible for parsing data, creating nodes, storing data and setting relationships in the streaming graph.
First, the ingest query creates the nodes we want using MATCH and WHERE. The node id is assigned using the idFrom function.
MATCH (revNode) WHERE id(revNode) = idFrom("revision", $that.rev_id)
MATCH (dbNode) WHERE id(dbNode) = idFrom("db", $that.database)
MATCH (userNode) WHERE id(userNode) = idFrom("id", $that.performer.user_id)
Notice that we pass two parameters to the idFrom function. The first parameter, establishes a unique namespace for the id to avoid collisions. The second parameter is the rev_id from the page-create object. The result from idFrom is a deterministic UUID for each node.
Next, we store the rev, db, and user values as properties in the respective nodes and label each node for clarity in the graph explorer. Quine parses the ingested line and stores the results in a variable, $that. You can retrieve values from the ingested datum using dot notation as $that.<attribute>.
SET revNode = $that, revNode.type = "rev"
SET dbNode.database = $that.database, dbNode.type = "db"
SET userNode = $that.performer, userNode.type = "user"
CALL create.setLabels(revNode, ["rev:" + $that.page_title])
CALL create.setLabels(dbNode, ["db:" + $that.database])
CALL create.setLabels(userNode, ["user:" + $that.performer.user_text])
There is quite a bit going on in this simple line. Specifically, the use of WITH *. Let's take a moment to understand why we chose to use this pattern.
By calling WITH *, Cypher changes the scope of data available. If you explicitly list each node in the data and accidentally omit a variable, it's lost for the remainder of the query, and you can get unexpected errors. Using the glob ensures that all nodes and variables are at your disposal in the ingest query.
WITH *, datetime($that.rev_timestamp) AS d
The ingest query make a CALL to the reify.time function to create a new timeNode. The resulting node is based on the year, month, day, hour, and minute of the rev_timestamp. It also increments the count parameter of the timeNode.
CALL reify.time(d, ["year", "month", "day", "hour", "minute"])
YIELD node AS timeNode
CALL incrementCounter(timeNode, "count")
Finally, the ingest query creates the relationships between nodes in the graph.
CREATE (revNode)-[:at]->(timeNode)
CREATE (revNode)-[:db]->(dbNode)
CREATE (revNode)-[:by]->(userNode)
Run the wikipedia recipe
Now, let's run the recipe to see how the ingest query builds out the graph in Quine. With the latest Quine jar file downloaded from Quine.io start the recipe from the command line.
❯ java -jar quine-x.x.x.jar -r wikipedia
The recipe includes a standing query that outputs nodes to the terminal as they arrive. You should see activity quickly after launching the recipe.
Before the graph gets too large, open Quine explorer (http:/0.0.0.0:8080) and run the time nodes stored query. Each of the time nodes were created by the ingest query using the timestamp in the page-create object.
We call these synthetic nodes. Synthetic nodes are useful when looking for abstract patterns between loosely related nodes. In this case, which updates were done during a particular time bucket.
![[Screen Shot 2022-05-20 at 4.09.17 PM.png]]
Using the API, let's inspect the ingest stream using the ingest endpoint.
❯ http GET http://0.0.0.0:8080/api/v1/ingest Content-Type:application/json
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Type: application/json
Date: Fri, 20 May 2022 20:06:01 GMT
Server: akka-http/10.2.9
Transfer-Encoding: chunked
{
"INGEST-1": {
"settings": {
"format": {
"parameter": "that",
"query": "MATCH (revNode) WHERE id(revNode) = idFrom(\"revision\", $that.rev_id)\nMATCH (dbNode) WHERE id(dbNode) = idFrom(\"db\", $that.database)\nMATCH (userNode) WHERE id(userNode) = idFrom(\"id\", $that.performer.user_id)\nSET revNode = $that, revNode.type = \"rev\"\nSET dbNode.database = $that.database, dbNode.type = \"db\"\nSET userNode = $that.performer, userNode.type = \"user\"\nWITH *, datetime($that.rev_timestamp) AS d\nCALL create.setLabels(revNode, [\"rev:\" + $that.page_title])\nCALL create.setLabels(dbNode, [\"db:\" + $that.database])\nCALL create.setLabels(userNode, [\"user:\" + $that.performer.user_text])\nCALL reify.time(d, [\"year\", \"month\", \"day\", \"hour\", \"minute\"]) YIELD node AS timeNode\nCALL incrementCounter(timeNode, \"count\")\nCREATE (revNode)-[:at]->(timeNode)\nCREATE (revNode)-[:db]->(dbNode)\nCREATE (revNode)-[:by]->(userNode)",
"type": "CypherJson"
},
"parallelism": 16,
"type": "ServerSentEventsIngest",
"url": "https://stream.wikimedia.org/v2/stream/page-create"
},
"stats": {
"byteRates": {
"count": 1354157,
"fifteenMinute": 1552.6927122874843,
"fiveMinute": 1398.959143968717,
"oneMinute": 1099.4731678954581,
"overall": 1448.3578957557581
},
"ingestedCount": 914,
"rates": {
"count": 914,
"fifteenMinute": 1.0510781922502073,
"fiveMinute": 0.9474472912218986,
"oneMinute": 0.7431750446830565,
"overall": 0.9775815796950665
},
"startTime": "2022-05-20T19:50:26.494025Z",
"totalRuntime": 934608
},
"status": "Running"
}
}
The ingest query defined via the recipe is named INGEST-1 and is currently running.
Did you know that you can make API calls directly from the embedded API documentation?
Select the page icon (📄) from the left nav inside of Quine Explore then navigate to the API endpoint that you want to exercise.
Adjust the API call as needed, and press the blue "Send API Request" Button.

Pausing the stream via the API is done via the ingest/{name}/pause endpoint.
❯ http PUT http://tow-mater:8080/api/v1/ingest/INGEST-1/pause Content-Type:application/json
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Type: application/json
Date: Fri, 20 May 2022 20:09:27 GMT
Server: akka-http/10.2.9
Transfer-Encoding: chunked
{
"name": "INGEST-1",
"settings": {
"format": {
"parameter": "that",
"query": "MATCH (revNode) WHERE id(revNode) = idFrom(\"revision\", $that.rev_id)\nMATCH (dbNode) WHERE id(dbNode) = idFrom(\"db\", $that.database)\nMATCH (userNode) WHERE id(userNode) = idFrom(\"id\", $that.performer.user_id)\nSET revNode = $that, revNode.type = \"rev\"\nSET dbNode.database = $that.database, dbNode.type = \"db\"\nSET userNode = $that.performer, userNode.type = \"user\"\nWITH *, datetime($that.rev_timestamp) AS d\nCALL create.setLabels(revNode, [\"rev:\" + $that.page_title])\nCALL create.setLabels(dbNode, [\"db:\" + $that.database])\nCALL create.setLabels(userNode, [\"user:\" + $that.performer.user_text])\nCALL reify.time(d, [\"year\", \"month\", \"day\", \"hour\", \"minute\"]) YIELD node AS timeNode\nCALL incrementCounter(timeNode, \"count\")\nCREATE (revNode)-[:at]->(timeNode)\nCREATE (revNode)-[:db]->(dbNode)\nCREATE (revNode)-[:by]->(userNode)",
"type": "CypherJson"
},
"parallelism": 16,
"type": "ServerSentEventsIngest",
"url": "https://stream.wikimedia.org/v2/stream/page-create"
},
"stats": {
"byteRates": {
"count": 1653281,
"fifteenMinute": 1530.565647994232,
"fiveMinute": 1428.2092910910662,
"oneMinute": 1488.2104624440235,
"overall": 1448.444229804896
},
"ingestedCount": 1117,
"rates": {
"count": 1117,
"fifteenMinute": 1.0361739604926652,
"fiveMinute": 0.96669545913622,
"oneMinute": 1.0032209384426753,
"overall": 0.9786067989220232
},
"startTime": "2022-05-20T19:50:26.494025Z",
"totalRuntime": 1141066
},
"status": "Paused"
}
Notice that the updates in your terminal window stopped and the INGEST-1 ingest stream has a status of "Paused".
Restart the stream with a PUT to the /ingest/{name}/start endpoint. Updates will resume in your terminal window and the ingest stream status will return to "Running".
Conclusion
We are just getting warmed up with ingest streams! This post walked through a simple ingest stream and ingest query to read server-sent events (SSE) from the Wikipedia streaming events service.
Next up in the series is Ingesting CSV data where we will go over how Quine streams in data that is stored in a CSV file.
I welcome your feedback! Drop in to Quine Slack and let me know what you think. I'm always happy to discuss Quine or answer questions.
Posted on May 31, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



