Consistency between Cache and Database, Part 2

ChunTing Wu
Posted on July 11, 2022
- Part 1: Read Aside Caching
- Part 2: Enhanced Approaches
This is the last article in the series. In the previous article we introduced why caching is needed and also introduced the Read Aside process and potential problems, and of course explained how to improve the consistency of Read Aside. Nevertheless, Read Aside is not enough for high consistency requirements.
One of the reasons why Read Aside can cause problems is because all users have access to the cache and database. When users manipulate data at the same time, inconsistencies occur due to various combinations of operation order.
Then we can effectively avoid inconsistency by limiting the behavior of manipulating data, which is the core concept of the next few methods.
Read Through
Read Path
- Reading data from cache
- If the cache data does not exist
- Read from database by cache
- Cache returns to the application client
Write Path
- Don't care, usually used in combination with Write Through or Write Ahead.
Potential Problems
The biggest problem with this approach is that not all caches are supported, and the Redis example in this article does not support this approach.
Of course, some caches are supported, such as NCache, but NCache also has its problems.
First, it does not support many client-side SDKs. .NET Core is the native support language and there are not many options left.
Besides, it is divided into open source version and enterprise version, but you should know that if the open source version is not used by many people, then it is a tragedy when something goes wrong. Even so, the Enterprise version requires a license fee, not only for the infrastructure, but also for the software license.
How to Improve
Since NCache has its high cost, can we implement Read Through ourselves? The answer is yes.
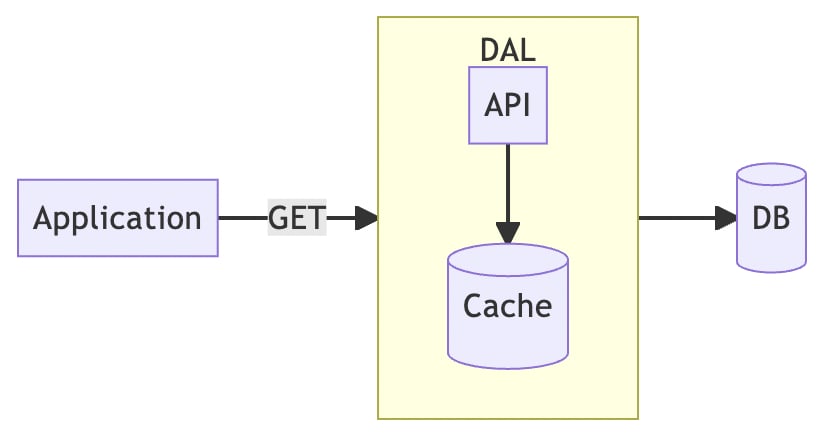
For the application, we don't really care what kind of cache is behind it, as long as it provides us with data fast enough, that's all we need. Therefore, we can package Redis as a standalone service called Data Access Layer (DAL), with an internal API server to coordinate the cache and database.
The application only needs to use the defined API to get data from the DAL, and doesn't need to care about how the cache works or where the database is.
Write Through
Read Path
- Don't care, the actual work is usually done through Read Through.
Write Path
- Data only written for caching
- Updated database by cache
Potential Problems
As with Read Through, not every cache is supported and must be implemented on your own.
In addition, caching is not designed to be used for data manipulation. Many databases have capabilities that caching does not have, especially the ACID guarantee for relational databases.
More importantly, caching is not suitable for data persistence. When an application writes to a cache and considers the update to be finished, the cache may still lose the data for "some reason". Then, the current update will never happen again.
How to Improve
As with Read Through, a DAL had to be implemented, but the ACID and persistence problems were still not overcome. So, Write Ahead was born.
Write Ahead
Read Path
- Don't care, the actual work is usually done through Read Through.
Write Path
- Data only written for caching
- Updated database by cache
Potential Problems
Similarly, Write Ahead is not supported by many caches. Even though the read path and write path look the same as Write Through, the implementation behind it is very different.
Write Ahead was created to solve the problem of Write Through, so let's introduce it first.
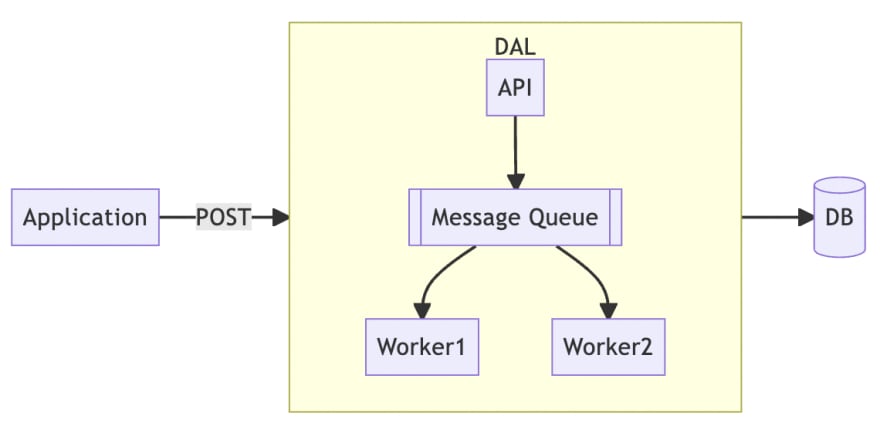
We will also implement a DAL, but unlike Write Through, it is actually an internal message queue rather than a cache. As you can see from the diagram above, the entire DAL architecture becomes more complex. To use the message queue correctly requires more domain knowledge and more human resources to design and implement.
How to Improve
By using message queues, the persistence of changes can be effectively ensured, and message queues also guarantee a certain degree of atomicity and isolation, which is not as complete as a relational database, but still has a basic level of reliability.
Moreover, message queues can merge fragmented updates into batches. For example, when an application wants to update three caches so it sends three messages, the DAL worker can merge the three messages into a single SQL syntax to reduce access to the database.
It is important to note the message queue must be used to ensure the order of messages, because for database updates, inserting and then deleting has a very different meaning than deleting and then inserting. The way to ensure message order is slightly different for each message queue, and in the case of Kafka it can be achieved by using the correct partition keys.
Nevertheless, the complexity of implementing Write Ahead is very high. If you cannot afford such complexity, then Read Aside is a better choice.
Double Delete
We have already talked about two major types of cache patterns, which are
- Read Aside
- Read Through, Write Through, Write Ahead
The most fundamental difference between these two types is the complexity of implementation. In the case of Read Aside, it is very easy to implement, and it is also very simple to do right. However, Read Aside can easily generate various corner cases under many interactions.
On the other hand, corner cases can be avoided by implementing DAL, but it is very difficult to implement DAL correctly, and it requires extensive domain knowledge to implement correctly, which further makes DAL difficult to achieve.
So, is DAL the only way to reduce the number of corner cases? No, not really.
This is what the Double Delete pattern is trying to solve.
Read Path
- Reading data from cache
- If the cache data does not exist
- Read from the database instead
- and write back to the cache
The process is exactly the same as Read Aside.
Write Path
- Clear the cache first
- Then write the data into the database
- Wait for a while, then clear the cache again
Potential Problems
The purpose of Double Delete is to minimize the time spent in disaster due to Read Aside corner cases.
The entire inconsistency depends entirely on the waiting time, which is equal to the maximum time waiting.
But how to wait is also a difficult practical problem. If we let the client originally started to deal with it, then the killed scenario in corner case 2 would still not be solved. If someone else performs it in an asynchronous way, then the communication contract and workflow control in between will be complicated.
How to Improve
The same corner case 2 as Read Aside, but again, it can be reduced by a graceful shutdown.
Conclusion
In this article, we introduce many ways to improve consistency. In general, when consistency is not a critical requirement, Cache Expiry is sufficient and requires a very low implementation effort. In fact, the widely used CDN is just one of the cases where Cache Expiry is used.
As the scenario becomes more and more critical and requires higher and higher consistency, then consider using Read Aside or even Double Delete to achieve it. The correct implementation of these two methods is sufficient for consistency to satisfy most scenarios.
However, as consistency requirements continue to increase, more complex implementations such as Read Through and Write Through or even Write Ahead become necessary. Although this can improve consistency, it is also costly. First, it requires sufficient manpower and domain knowledge to implement. In addition, the time cost of implementation and the maintenance cost afterwards are significantly higher. Furthermore, there are additional expenses to operate such an infrastructure.
To further improve consistency, it is necessary to use more advanced techniques, such as consensus algorithms, to ensure the consistency of cache and database content by majority consensus. This is also the concept behind TAO, but I am not going to introduce such a complex approach, after all, we are not Meta, at least, I am not.
In a general organization, the requirements for consistency are not as strict as, let's say, 10 or more nines, and a general organization cannot operate such a complex and large architecture.
Therefore, in this article, I have chosen practices that we can all achieve, but even if they are simple practices, there is already a high enough level of consistency if they are implemented correctly.
Posted on July 11, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.