Most Exhaustive XPath Locators Cheat Sheet

Vinayak Sharma
Posted on September 19, 2022

The Selenium framework lets you interact with the WebElements in the DOM. For realizing the interaction(s), it is important to choose the appropriate locator from the available Selenium web locators. As per my opinion, Selenium web locators can be considered as the backbone of any web automation script.
There are many options for web locators in Selenium — ID, Name, XPath, LinkText, Partial LinkText, Tag Name, and more. XPath is one of the widely preferred web locators, as it easily traverses through the DOM elements and attributes to identify an object.
If you plan to use an XPath web locator to shape your test automation scripts, you might not have to look further than this comprehensive XPath cheat sheet. In addition, you can keep this XPath cheat sheet handy in scenarios where you want to have a quick look at the XPath syntax or other aspects related to this web locator.
In this Selenium locators cheat sheet, we have demonstrated the XPath locator in the Java language. So, let’s get started with this exhaustive XPath cheat sheet that will come in super handy in Selenium automation testing.
What is XPath Web Locator in Selenium
XPath, which stands for XML Path Language, uses ‘path-like’ syntax to identify and navigate nodes in an XML or HTML document. It follows the XSLT(eXtensible Stylesheet Language Transformations) standard, which is predominantly used to navigate WebElements and attributes.

In order to navigate through the HTML document, the DOM (HTML tags, JavaScript, etc.) is used as a map where all the WebElements exist along with the WebElement that we intend to locate using the appropriate web locator.
You can check out our blog on locators in Selenium WebDriver to check other web locators that we have not covered in this XPath cheat sheet.
This article explains the emulator vs simulator vs real device differences, the learning of which can help you select the right mobile testing solution for your business.
Different types of XPath in Selenium
You can locate the desired WebElement in the DOM, either using the absolute path or using a relative path with respect to another element. In this part of the XPath cheat sheet, we look at the different ways in which you can use an XPath locator for locating a WebElement.
Here are the two main types of XPath in Selenium:
Absolute XPath
As the name indicates, an absolute XPath contains the complete path from the root element to the desired element. The downside of using absolute XPath is that any changes made in the path of the element, HTML path, etc., results in the failure of the XPath.
Absolute Xpath begins with the single forward-slash(/), which means selecting the element from the document’s root node.
Syntax — Absolute Xpath
/html/body/div[x]/div[y]/
Relative XPath
In contrast to absolute XPath, a relative XPath starts by referencing the element we want to locate relative to a particular location. This means that the element is positioned relative to its normal position.
Since the path of XPath is relative, it starts with a double forward-slash (//). As mentioned earlier in this Selenium locators cheat sheet, relative XPath is usually preferred for Selenium automation testing since it is not a complete path from the root element.
Hence, any changes in the page design or the DOM hierarchy will have a minimal (to no) impact on the existing XPath selector.
Syntax — Relative Xpath
//tagname[[@attribute](http://twitter.com/attribute)='value']
The XPath syntax
XPath uses path expressions to select nodes (or node-sets) in an HTML document. As shown below, the element or tag is selected by following a path or series of steps:

Here are some of the useful path expressions that you can keep in handy as a part of the XPath cheat sheet:

Perform cross browser compatibility testing across all Safari browsers for Windows, and many more real browsers and operating systems.
XPath Expressions in Selenium
XPath expression is a pattern that is used for selecting a set of nodes. These patterns are used by XSLT for performing transformations. XPointer also uses these patterns for addressing purposes.
XPath uses a path expression to select the node or a list of nodes from an XML or HTML document.
Syntax — XPath Expression
//tagname[[@attribute](http://twitter.com/attribute)='value']

- Prefixes
Prefixes in XPath are used at the beginning of the XPath expression.

Here are the examples of different kinds of Steps in XPath:

- Selecting Nodes
In this part of the XPath cheat sheet, we look at the different ways to select a node (or WebElement) in the document using XPath.
- Predicates
Predicates in XPath are used to find a specific node that contains a designated value. It uses syntax enclosed in square brackets.
The table shown below in this Selenium locators cheat sheet shows some examples of predicates, along with different ways of selecting WebElements using those predicates.

- Chaining order
Chaining order in XPath indicates the importance of order in an Xpath expression. The meaning of XPath changes with the change in order. For example a[1][@href=’/’] and a[@href=’/’][1] are different.
- Indexing
Indexing in XPath can be done using [ ] with a number that specifies the node we intend to select. It can also be done using functions like last() or position() that specify the index of the elements.

- Nesting predicates
XPath can also be nested to find the targeted node (or WebElement).
Example — Nested Predicates
//section[.//a[[@id](http://twitter.com/id)='btn']]
This example will return
if it has an anchor tag descendant with an ID value of ‘btn.’
- Selecting Unknown Nodes
Wildcards can also be used with an XPath locator to find unknown HTML document elements.

- Selecting Several Paths
Using the ‘|’ operator in the XPath expression, you can select several paths.
Below in this Selenium locators cheat sheet are examples that demonstrate the usage of the ‘|’ operator.

Browser test & app testing cloud to perform both exploratory and automated testing across 3000+ different browsers, real devices and operating systems.
XPath Selectors in Selenium
Selectors are used to ‘select’ certain parts of the HTML document specified by the element’s XPath. It’s the same as Axes in XPath.
- Descendant selectors
The descendant selectors indicate all the children of the current node, all children of children, etc. Attribute and namespace nodes are not included in descendant selectors. The parent of an attribute node is its element node, and on the other hand, attribute nodes are not the offspring of their parents.

- Attribute Selectors
The XPath attribute selector matches elements based on the presence or value of a given attribute.

- Siblings
Sibling in Selenium WebDriver is used for fetching a WebElement that is a sibling to a parent element. In this part of the XPath cheat sheet, we look at how to fetch elements using siblings in Selenium WebDriver.

- Using different Operators
You can use different operators like NOT, text matches (i.e., string, substring, etc.), union, and more to locate elements using operators and XPath in Selenium.

Axes in XPath
Axes in XPath represent a relationship from the current element to its relative element on the tree using either the absolute XPath or relative XPath. Its relationship to elements is identified as a parent, child, sibling, etc.
They are named Axes because they refer to the axis on which elements lie relative to a particular WebElement. Shown below is the syntax of Axes in XPath:
axisname::element[attribute]
This part of the Selenium locators cheat sheet shows the axis names and their relationship with the elements.
| Element | XPath |
|---|---|
| self | For referring current elements |
| parent | For referring parent of the current node |
| preceding | Selects all elements that appear before the current element in the document |
| preceding-sibling | Selects all siblings before the current elements |
| namespace | Selects all namespace elements of the current element |
| ancestor | Selects all ancestors with a relationship like a parent, grandparent, etc. relative to the current element |
| ancestor-or-self | Selects the current element as well as all the ancestors of that element |
| attribute | Selects all attributes of the current node |
| child | Selects all children of the current element |
| descendant | Selects all children, grandchildren, etc. of the current element |
| descendant-or-self | Selects all descendants of the current elements and the current element itself |
| following | Selecting everything in the document after the closing tag |
| following-sibling | Selecting all siblings after the current element |
Here are some of the ways in which siblings in XPath can be used to find WebElements for Selenium automation testing.

Operators in XPath
An XPath expression can return either a node-set(div,a,li), a string, a Boolean (true or false), or a number. As a result, XPath provides many operators to manipulate their return values so that you get the desired value.
In this part of XPath cheat sheet, we look at the list of operators that can be used with XPath expressions:

Functions in XPath
XPath provides a number of core libraries that bring in functionalities to deal with node sets, strings, booleans, and numbers.
Syntax Demonstration
button[text()="Submit"]
//button/text()
//ol/li[position()=2]
Node functions
There are seven kinds of nodes in XPath — element, attributes, namespaces, comments, document nodes, text, and processing instructions. First, let’s look at the permitted operations on nodes in further detail in this section of the XPath cheat sheet.
- name()
This function provides the name of the element
Example:
//[starts-with(name(), 'h')]
- text()
This function Selects a text node.
Example:
//button[text()="Submit"]
//button/text()
- position()
This function provides the position of the element.
/div/a[position()<3]
- last()
This function selects the last node relative to the current element.
Example:
/div/a[last()]
- comment()
This function selects the elements, which are comments.
Example:
/div/comment()
String functions
XPath string functions let you access elements using string type functions (e.g., contains, starts-with, etc.)
- contains()
This function is used to see if a certain element contains a particular string
Example:
font[contains([@class](http://twitter.com/class),"nav")]
- starts-with()
This function is used to check if our element starts with a certain text.
Example:
font[starts-with([@class](http://twitter.com/class),"nav")]
- ends-with()
Same as starts-with(), look (or check) at the end of the string.
Example:
font[ends-with([@class](http://twitter.com/class),"nav")]
- substring-before()
This function returns a string that is part of the input string before a given substring.
Example:
substring-before("01/02", "/")
Output: 01
- substring-after()
Same as substring-before(), returns a string that is part of the input string after a given substring.
Example:
substring-after("01/02", "/")
Math functions
You can use mathematics-type functions like floor, ceil, sum, etc., to find elements using the XPath selector.
Here are the math functions that we have covered in our XPath cheat sheet:
- ceiling(number)
This function returns the smallest integer value greater than or equal to the decimal number.
- floor(number)
This function returns the largest integer value less than or equal to the decimal number.
- round(decimal)
This function returns a number that is the nearest integer to the given number.
- sum(elements)
This function returns a number that is the sum of the numeric values of each element in a given element-set.
Boolean functions
Boolean operators can also be used to find elements using the XPath selector.
- not()
This function is used to check whether certain conditions are met or not.
Example:
button[not(starts-with(text(),"Submit"))]
Browser console to locate XPath
Most modern web browsers (e.g., Chrome, Firefox, etc.) have a built-in debugging tool, which includes a feature that allows us to evaluate or validate XPath/CSS selectors. These tokens execute in the console panel, thereby providing you an option to validate the XPath selector.
Here is a screenshot of the Debug Console in Chrome:

In this example, we have used $x(“//div”). With this, it selects all div elements from the DOM. An exception is thrown in case there is no matching node or elements in the DOM.
Obtain XPath using JQuery
JQuery supports all basic kinds of XPath expressions; major ones are listed below in this part of the XPath cheat sheet:
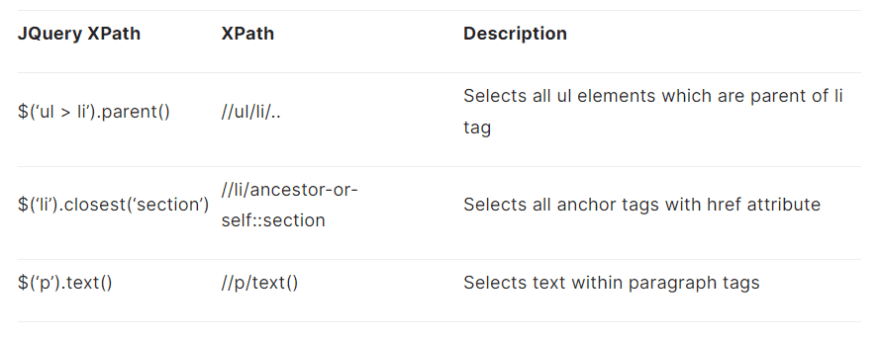
Bonus Examples

Conclusion
XPath is one of the widely used web locators in Selenium. However, coming up with an efficient XPath is an art that largely depends on the document’s structure and the current position of the WebElement.
One of the most important things is finding the nearest unique WebElement relative to the target element and using the best technique to locate the WebElement. We covered the major aspects of the XPath locator in this exhaustive XPath cheat sheet.
This Selenium locators cheat sheet can be used as a handy resource when you are performing Selenium automation testing.
When it comes to Selenium automation testing, you can leverage the capabilities offered by cloud-based Selenium Grid like LambdaTest which lets you run tests on different browsers, platforms, and device combinations.
Do share your views on how you would use this XPath cheat sheet for Selenium automation testing. Leave your feedback in the comments section…
Happy Testing!
Posted on September 19, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related