
Karan Pratap Singh
Posted on November 3, 2021

In this article, we'll look at how we can setup our own infrastructure for auditing passwords using haveibeenpwned list of compromised passwords.
Why do we need this?
While password auditing is not the most important thing, it can be still be quite helpful in improving our user's security as follows:
- Users will have to create stronger passwords that aren't leaked in public data breach when they signup for our services.
- We can create a cron job to asynchronously audit passwords of early users and suggest them to update their password.
Download and Extract
You can download it either as a torrent or directly from here
$ mkdir hibp
$ cd hibp
$ wget https://downloads.pwnedpasswords.com/passwords/pwned-passwords-sha1-ordered-by-count-v7.7z
$ 7za x pwned-passwords-sha1-ordered-by-count-v7.7z
Let's see how many passwords pwned-passwords-sha1-ordered-by-count-v7.txt file contains.
$ wc -l chunks/pwned-passwords-sha1-ordered-by-hash-v7.txt
613584246
That's over 600M compromised passwords!
Note: I will recommend to do this on EC2, something like t3.2xlarge which has 8 vCPUs and 5 Gbps network bandwidth for us to play with.
Pre-process data
While, the password list is about ~26 GB in size which is not huge, but it has over 600M records!
So, we need to pre-process it by splitting in to smaller chunks of 1M records each, which are much easier to process.
$ mkdir chunks
$ cd chunks
$ split -l 1000000 ../pwned-passwords-sha1-ordered-by-hash-v7.txt chunk-
This should create 600 chunks of the original file like this:
$ ls chunks
chunk-aa
chunk-ab
chunk-ac
Storage
For storage, we have various different options:
I'll be using DynamoDB for storage, as I think it's perfect for this usecase. Let's provision our DynamoDB table with terraform and create an attribute hash for indexing:
resource "aws_dynamodb_table" "hibp_table" {
name = "Hibp"
billing_mode = "PROVISIONED"
read_capacity = 5
write_capacity = 1
hash_key = "hash"
attribute {
name = "hash"
type = "S"
}
}
Note: If you're not familiar with Terraform, feel free to checkout my earlier post on it.
Processing
Before we start playing with the data, Let's look at different options we have to write the data to our DynamoDB table:
As this was a one off thing for me, I simply created a script to utilize BatchWriteItem API to get the data to the DynamoDB table. If you already using data pipeline or EMR, feel free to do that as it might be better in the long run? That's a question better left to our friends doing data engineering!
How?
But wait...this was more tricky than I thought. My initial plan was to make a script with JavaScript to batch write 1M records at a time. Unfortunately, BatchWriteItem API only allows 25 items per batch request, maybe for a good reason?.
We have hope!
We need multi-threading or something similar! For this I choose Golang, I love how lightweight and powerful goroutines are! So, here's our new approach:
- Transform
Chunks we created earlier for pwned-passwords-sha1-ordered-by-count-v7.txt are in a format like:
<SHA-1>:<no of times compromised>
Note: The SHA-1 is already in uppercase to reduce query time as per the author of the file.
So basically, bigger the number on the right, worse the password. This is the rough schema we'll be using for our DynamoDB table:
Column | Type
-----------------------------
hash (index) | S
times | N
type | S
Note: We included the type field to store which type of algorithm the hash is using, right now we'll store SHA-1 but in the future we can extend and filter our table with other password lists.
We can now simply iterate over the all the contents and transform them into 1M million batch write requests like we originally intended to.
- Chunking
Since we know that we cannot exceed 25 items per batch write request, let's break our 1M requests in to 40K chunks to not exceed limits from AWS.
- Batching
Now, let's further break our 40K chunks into 4 batches of 10K each. Finally, we can iterate over these 4 batches and launch 10K goroutines each time. Hence, every iteration we "theoritically" write 250k records to our table.
Let's Code
Here's our ideas in Golang. Let's init our module and add aws-sdk.
Note: All the code is also available in this repository
$ go mod init ingest
$ touch main.go
$ github.com/aws/aws-sdk-go-v2
$ github.com/aws/aws-sdk-go-v2/config
$ github.com/aws/aws-sdk-go-v2/feature/dynamodb/attributevalue
$ github.com/aws/aws-sdk-go-v2/service/dynamodb
Create our job.log file
$ mkdir logs
$ touch logs/job.log
This should give us a structure like this:
├── chunks
│ └── ...
├── logs
│ └── job.log
├── go.mod
├── go.sum
└── main.go
Let's add content to our main.go file.
package main
import (
"bufio"
"context"
"io"
"io/fs"
"io/ioutil"
"log"
"os"
"strconv"
"strings"
"sync"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/aws/retry"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/feature/dynamodb/attributevalue"
"github.com/aws/aws-sdk-go-v2/service/dynamodb"
dynamodbTypes "github.com/aws/aws-sdk-go-v2/service/dynamodb/types"
)
type Schema struct {
Hash string `dynamodbav:"hash"`
Times int `dynamodbav:"times"`
Type string `dynamodbav:"type"`
}
var table string = "Hibp"
var dir string = "chunks"
func main() {
logFile, writer := getLogFile()
log.SetOutput(writer)
defer logFile.Close()
log.Println("Using table", table, "with directory", dir)
files := getFiles(dir)
for num, file := range files {
filename := file.Name()
path := "chunks/" + filename
log.Println("====", num+1, "====")
log.Println("Starting:", filename)
file, err := os.Open(path)
if err != nil {
log.Fatal(err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
items := []dynamodbTypes.WriteRequest{}
for scanner.Scan() {
line := scanner.Text()
schema := parseLine(line)
attribute := getAttributes(schema)
item := dynamodbTypes.WriteRequest{
PutRequest: &dynamodbTypes.PutRequest{
Item: attribute,
},
}
items = append(items, item)
}
chunks := createChunks(items)
batches := createBatches(chunks)
log.Println("Created", len(batches), "batches for", len(chunks), "chunks with", len(items), "items")
var wg sync.WaitGroup
for index, batch := range batches {
failed := 0
log.Println("Processing batch", index+1)
batchWriteToDB(&wg, batch, &failed)
log.Println("Completed with", failed, "failures")
wg.Wait()
}
log.Println("Processed", filename)
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
}
log.Println("Done")
}
func getLogFile() (*os.File, io.Writer) {
file, err := os.OpenFile("logs/job.log", os.O_RDWR|os.O_CREATE|os.O_APPEND, 0666)
if err != nil {
log.Fatalf("error opening file: %v", err)
}
mw := io.MultiWriter(os.Stdout, file)
return file, mw
}
func getDynamoDBClient() dynamodb.Client {
cfg, err := config.LoadDefaultConfig(context.TODO(), config.WithRetryer(func() aws.Retryer {
return retry.AddWithMaxAttempts(retry.NewStandard(), 5000)
}))
cfg.Region = "us-west-2"
if err != nil {
log.Fatal(err)
}
return *dynamodb.NewFromConfig(cfg)
}
func getFiles(dir string) []fs.FileInfo {
files, dirReadErr := ioutil.ReadDir("chunks")
if dirReadErr != nil {
panic(dirReadErr)
}
return files
}
func parseLine(line string) Schema {
split := strings.Split(line, ":")
Hash := split[0]
Times, _ := strconv.Atoi(split[1])
Type := "SHA-1"
return Schema{Hash, Times, Type}
}
func getAttributes(schema Schema) map[string]dynamodbTypes.AttributeValue {
attribute, err := attributevalue.MarshalMap(schema)
if err != nil {
log.Println("Error processing:", schema)
log.Fatal(err.Error())
}
return attribute
}
func batchWriteToDB(wg *sync.WaitGroup, data [][]dynamodbTypes.WriteRequest, failed *int) {
for _, chunk := range data {
wg.Add(1)
go func(chunk []dynamodbTypes.WriteRequest, failed *int) {
defer wg.Done()
client := getDynamoDBClient()
_, err := client.BatchWriteItem(context.TODO(), &dynamodb.BatchWriteItemInput{
RequestItems: map[string][]dynamodbTypes.WriteRequest{
table: chunk,
},
})
if err != nil {
*failed += 1
log.Println(err.Error())
}
}(chunk, failed)
}
}
func createChunks(arr []dynamodbTypes.WriteRequest) [][]dynamodbTypes.WriteRequest {
var chunks [][]dynamodbTypes.WriteRequest
var size int = 25
for i := 0; i < len(arr); i += size {
end := i + size
if end > len(arr) {
end = len(arr)
}
chunks = append(chunks, arr[i:end])
}
return chunks
}
func createBatches(arr [][]dynamodbTypes.WriteRequest) [][][]dynamodbTypes.WriteRequest {
var batches [][][]dynamodbTypes.WriteRequest
var size int = 10000
for i := 0; i < len(arr); i += size {
end := i + size
if end > len(arr) {
end = len(arr)
}
batches = append(batches, arr[i:end])
}
return batches
}
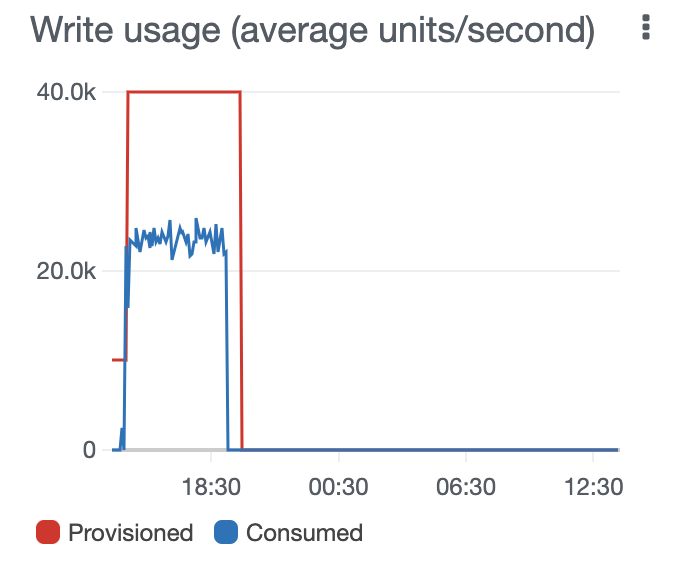
Now, we need to go update our write capacity to 30k so the table can handle the load from our script.
We're provisioning 30k write capacity which is almost $15k a month! Although we will only use this capacity for just few hrs, it is easy to forget to scale it down afterwards. Make sure to create a billing alert for $100, so you don't forget. Please don't blame me if you get a huge bill from AWS next month.
Output:
$ go build main.go
$ ./main
==== 1 ====
2021/10/22 16:18:25 Starting: chunk-ix
2021/10/22 16:18:28 Created 4 batches for 40000 chunks with 1000000 items
2021/10/22 16:18:28 Processing batch 1
2021/10/22 16:18:28 Completed with 0 failures
2021/10/22 16:18:33 Processing batch 2
2021/10/22 16:18:33 Completed with 0 failures
2021/10/22 16:18:39 Processing batch 3
2021/10/22 16:18:39 Completed with 0 failures
2021/10/22 16:18:44 Processing batch 4
2021/10/22 16:18:45 Completed with 0 failures
Benchmarks
Benchmarks are for 1M records with t3.2xlarge. Here, Golang performs way faster when compared to JavaScript due to goroutines utilizing all the thread, plus it's faster in general.
JavaScript (Node.js 16)
~1083s (~18 minutes)
Go (1.17)
~28s
So, to conclude we can finish the whole thing in 3-4 hrs with Go!
Usage
Now since we have our table setup, we can simply query like below:
import { DynamoDB } from 'aws-sdk';
import crypto from 'crypto';
const client = new AWS.DynamoDB();
const TableName = 'Hibp';
type UnsafeCheckResult = {
unsafe: boolean;
times?: number;
};
export async function unsafePasswordCheck(password: string): Promise<UnsafeCheckResult> {
const shasum = crypto.createHash('sha1').update(password);
const hash = shasum.digest('hex').toUpperCase();
const params: DynamoDB.QueryInput = {
TableName,
KeyConditionExpression: '#hash = :hash',
ExpressionAttributeNames: {
'#hash': 'hash',
},
ExpressionAttributeValues: {
':hash': { S: hash },
},
};
const result: DynamoDB.QueryOutput = await dynamoDbClient
.query(params)
.promise();
if (result?.Count && result?.Items?.[0]) {
const [document] = result.Items;
const foundItem = DynamoDB.Converter.unmarshall(document);
return { unsafe: true, times: foundItem?.times };
}
return { unsafe: false };
}
Cost estimation
DynamoDB: 30k write capacity ($14251.08/month or $19.50/hr)
EC2: t3.2xlarge ($0.3328/hr)
Duration: ~4hrs
Total: $19.8328 * 4hrs = ~$79.3312
The main component in price is the DynamoDB's 30k write capacity, if we can use a better EC2 machine (let's say c6g.16xlarge) and launch more goroutines to utilise additional write capacity (let's say 40k). It will be more expensive but it might reduce total time we took. This will reduce the DynamoDB usage, reducing the overall price under $60!
Perfomance improvements?
Are your queries too slow? Do you have millions of users? To improve query performance, we can setup bloom filters with redis to reduce load the DB.
Conclusion
I hope this was helpful, feel free to reach out to me on twitter if you face any issues. Thanks for reading!
Posted on November 3, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related