Chat with your Github Repo using llama_index and chainlit

Karan Janthe
Posted on April 16, 2024

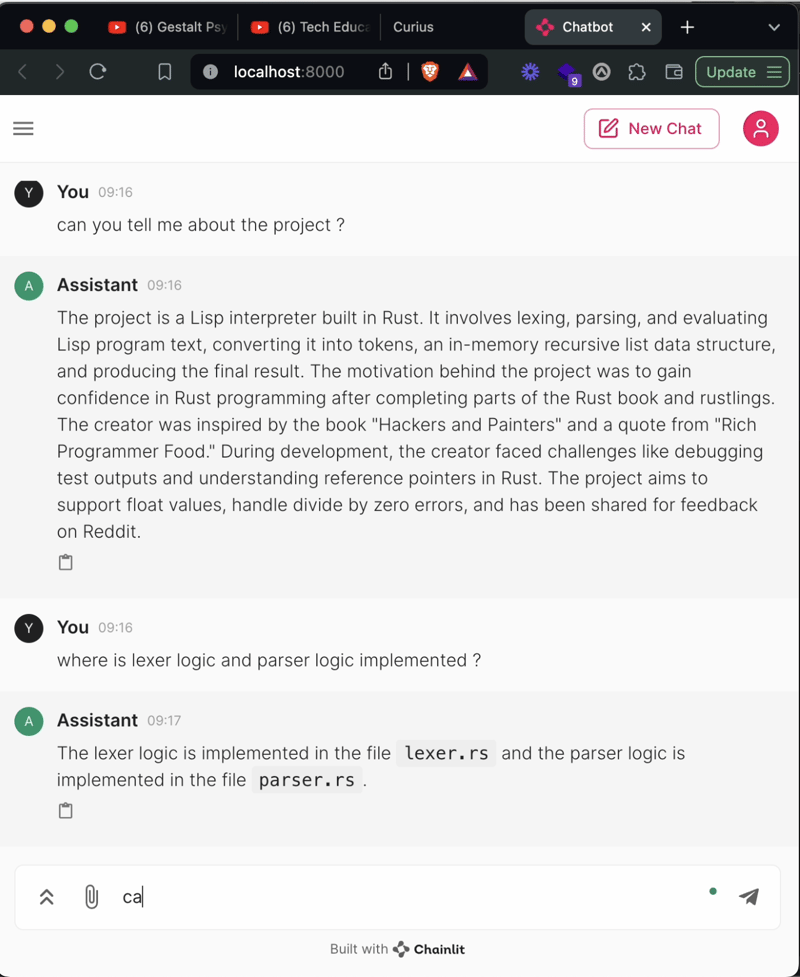
By the end of this blog, you will be able to chat and ask question to your codebase, with just 100 lines of code!
Before we begin, let's first address two big elephants in the room!
llama_index
in simpler terms, LlamaIndex is tool that makes our life easy by working as a bridge between our custom data and large language models(LLM), processing manually different types of data which can be structured, unstructured, extracting them, processing them, all headache is gone with LlamaIndex, there are so many already community plugins ready on llamaHub, no need to reinvent the wheel again, thanks to huge open source community!
chainlit
chainlit is open source project that makes it very easy to build frontend interfaces like chatgpt and other features that are required for conversational ai app, so we can focus on the core part and don't need to worry about basic things, and it is dead simple to work with
let's begin!!
basic setup:
openai_key = os.getenv("OPENAI_API_KEY")
GITHUB_TOKEN = os.getenv("GITHUB_TOKEN")
If you don’t have a Github Token, go here
we need to create github client which will fetch the repo's content and download them for us:
import os
from llama_index.readers.github import GithubRepositoryReader
from llama_index.core import (
VectorStoreIndex,
StorageContext,
load_index_from_storage,
PromptHelper,
ServiceContext,
)
from langchain_community.embeddings import HuggingFaceEmbeddings
import chainlit as cl
from llama_index.readers.github import GithubRepositoryReader, GithubClient
from langchain_openai import ChatOpenAI
openai_key = os.getenv("OPENAI_API_KEY")
GITHUB_TOKEN = os.getenv("GITHUB_TOKEN")
github_client = GithubClient(GITHUB_TOKEN)
owner = "KMJ-007"
repo = "RustyScheme"
branch = "main"
# We currently don't support images or videos, so we filter them out to reduce the load time.
IGNORE_MEDIA_EXTENSIONS = [
".png",
".jpg",
".jpeg",
".gif",
".mp4",
".mov",
".avi",
".PNG",
".JPG",
".JPEG",
".GIF",
".MP4",
".MOV",
".AVI",
]
ignore_directories = []
don't worry about other imports, they will make sense in a minute
here comes our first function which's purpose is to load index for our github repo, and store them in dir, so we don't need to do it every time we run the project, we can use vector database or other methods to store vectors also
@cl.cache
def load_index():
try:
# rebuild the storage context
storage_context = StorageContext.from_defaults(
persist_dir="./rusty_scheme_vectors"
)
# load the index
index = load_index_from_storage(
storage_context=storage_context
)
except Exception as e:
print(f"Error loading index: {str(e)}")
# storage not found; create a new index
print("Storage not found, creating a new index")
documents = GithubRepositoryReader(
github_client=github_client,
owner=owner,
repo=repo,
filter_directories=(
ignore_directories,
GithubRepositoryReader.FilterType.EXCLUDE,
)
if ignore_directories
else None,
filter_file_extensions=(
IGNORE_MEDIA_EXTENSIONS,
GithubRepositoryReader.FilterType.EXCLUDE,
),
verbose=True,
concurrent_requests=768,
).load_data(
branch=branch,
)
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo",
streaming=True,
openai_api_key=openai_key,
)
prompt_helper = PromptHelper(
context_window=4095,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
embed_model = HuggingFaceEmbeddings()
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
prompt_helper=prompt_helper,
)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
index.storage_context.persist("./rusty_scheme_vectors")
return index
let's understand what above code does,
@cl.cache
just tells chainlit to cache this function,
try:
# rebuild the storage context
storage_context = StorageContext.from_defaults(
persist_dir="./rusty_scheme_vectors"
)
# load the index
index = load_index_from_storage(
storage_context=storage_context
)
code is two blocks, try and except, try blocks first tries to find the vectors from the dir, and if it finds then it loads them
if try block fails to load the index from the dir, except code block gets called
documents = GithubRepositoryReader(
github_client=github_client,
owner=owner,
repo=repo,
filter_directories=(
ignore_directories,
GithubRepositoryReader.FilterType.EXCLUDE,
)
if ignore_directories
else None,
filter_file_extensions=(
IGNORE_MEDIA_EXTENSIONS,
GithubRepositoryReader.FilterType.EXCLUDE,
),
verbose=True,
concurrent_requests=768,
).load_data(
branch=branch,
)
above code fetchs the repo we mentioned and loads them as documents to process
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo",
streaming=True,
openai_api_key=openai_key,
)
prompt_helper = PromptHelper(
context_window=4095,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
after loading documents, we tell about the llm which we want to use in ChatOpenAi, prompt_helper makes it easy to provide context window and putting constraint.
embed_model = HuggingFaceEmbeddings()
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
# node_parser=node_parser,
prompt_helper=prompt_helper,
)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
index.storage_context.persist("./rusty_scheme_vectors")
HuggingFaceEmbeddings is a function that we use for converting our documents to vector which is called embedding, you can use any embedding model from huggingface, it will load the model on your local computer and create embeddings(you can use external api/service to create embeddings), then we just pass this to context and create index and store them into folder so we can reuse them and don't need to recalculate it.
chat_start
we need to load index on the chat start, this is exactly what the following function does:
@cl.on_chat_start
async def on_chat_start():
index = load_index()
query_engine = index.as_query_engine(
streaming=True,
similarity_top_k=2,
)
cl.user_session.set("query_engine", query_engine)
await cl.Message(author="Assistant", content="Hello! How may I help you?").send()
we load the index, make a query engine and in that we pass similarity top k to 2, it basically tells how top similar answers get from, then we set the query engine in user session and send the assistant message
on_message
when user sends a message, following function gets called:
@cl.on_message
async def main(message: cl.Message):
query_engine = cl.user_session.get("query_engine")
msg = cl.Message(content="", author="Assistant")
print(message.content)
res = query_engine.query(message.content)
for text in res.response_gen:
token = text
await msg.stream_token(token)
await msg.send()
so the above code gets the query_engine, we pass the user asked a question to query engine, which under the hood calls the query engine which uses index to get similar embeddings and give it to LLM to get structured normal language output which normal user can understand.
whole code(app.py):
import os
from llama_index.readers.github import GithubRepositoryReader
from llama_index.core import (
VectorStoreIndex,
StorageContext,
load_index_from_storage,
PromptHelper,
ServiceContext,
)
from langchain_community.embeddings import HuggingFaceEmbeddings
import chainlit as cl
from llama_index.readers.github import GithubRepositoryReader, GithubClient
from langchain_openai import ChatOpenAI
openai_key = os.getenv("OPENAI_API_KEY")
GITHUB_TOKEN = os.getenv("GITHUB_TOKEN")
github_client = GithubClient(GITHUB_TOKEN)
owner = "KMJ-007"
repo = "RustyScheme"
branch = "main"
# We currently don't support images or videos, so we filter them out to reduce the load time.
IGNORE_MEDIA_EXTENSIONS = [
".png",
".jpg",
".jpeg",
".gif",
".mp4",
".mov",
".avi",
".PNG",
".JPG",
".JPEG",
".GIF",
".MP4",
".MOV",
".AVI",
]
ignore_directories = []
# function to load the index from storage or create a new one
# todo: add the support for vector database
@cl.cache
def load_index():
try:
# rebuild the storage context
storage_context = StorageContext.from_defaults(
persist_dir="./rusty_scheme_vectors"
)
# load the index
index = load_index_from_storage(
storage_context=storage_context
)
except Exception as e:
print(f"Error loading index: {str(e)}")
# storage not found; create a new index
print("Storage not found, creating a new index")
documents = GithubRepositoryReader(
github_client=github_client,
owner=owner,
repo=repo,
filter_directories=(
ignore_directories,
GithubRepositoryReader.FilterType.EXCLUDE,
)
if ignore_directories
else None,
filter_file_extensions=(
IGNORE_MEDIA_EXTENSIONS,
GithubRepositoryReader.FilterType.EXCLUDE,
),
verbose=True,
concurrent_requests=768,
).load_data(
branch=branch,
)
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo",
streaming=True,
openai_api_key=openai_key,
)
prompt_helper = PromptHelper(
context_window=4095,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
embed_model = HuggingFaceEmbeddings()
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
# node_parser=node_parser,
prompt_helper=prompt_helper,
)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
index.storage_context.persist("./rusty_scheme_vectors")
return index
@cl.on_chat_start
async def on_chat_start():
index = load_index()
query_engine = index.as_query_engine(
streaming=True,
similarity_top_k=2,
)
cl.user_session.set("query_engine", query_engine)
await cl.Message(author="Assistant", content="Hello! How may I help you?").send()
@cl.on_message
async def main(message: cl.Message):
query_engine = cl.user_session.get("query_engine")
msg = cl.Message(content="", author="Assistant")
print(message.content)
res = query_engine.query(message.content)
for text in res.response_gen:
token = text
await msg.stream_token(token)
await msg.send()
Run the app by:
chainlit run app.py -w
it will open the frontend, wait for index to load and ask the question

that's it, hope i explained things clearly, we can integrate vector database, and external embeddings via api and many more things, i wanted to go in more depth, we are still playing on top of lot of abstractions, maybe in future posts i will go in more depth, but for this post i wanted to keep things in scope to explain for beginners and show how easy it is.
Posted on April 16, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related