
Rui Trigo
Posted on April 21, 2020

Prologue
Picture your database server. Now imagine it somehow breaks. Despair comes up and disturbs the reaction.
Maybe you lost data. Maybe you had too much downtime. Maybe you lost work hours. Maybe you lost precious time and money. High Availability is easily a nice-to-have but in times like these, you value it more.
MongoDB comes with clustering features that provide more storage capacity (sharding) and more reliability (replication). This article will focus on MongoDB replication on Docker containers.
Motivation
We felt the need to improve our production database and data backup strategy as we identified it was giving the servers a hard time performance-wise and the disaster recovery process was very hard in most procedures.
So, we started to design a migration plan to solve this. We also took the chance to update the Mongo version in use to benefit from new features and security improvements.
Before

Old Production Environment
Production servers
- server_1: application services containers + 2 mongo containers
- server_2: application services containers + 1 mongo containers
- server_3: application services containers + 1 mongo containers
Mirror servers
- mirror_server_1: application services containers + 2 mongo containers (updated once a day)
- mirror_server_2: application services containers + 1 mongo containers (updated once a day)
- (services and data on server3 were not in mirror environment)
The Mongo service was kept using a mongodump/mongorestore strategy.
mongodump/mongorestore Strategy
The first part of the mongodump/mongorestore strategy is composed of Cron jobs that dump the data in the Mongo database to a different Mongo instance with the mongodump utility.
mongodump is a utility for creating a binary export of the contents of a database. mongodump can export data from either mongod or mongos instances; i.e. can export data from standalone, replica set, and sharded cluster deployments.
mongodump --host=mongodb1.example.net --port=3017 --username=user --password="pass" --out=/opt/backup/mongodump-2013-10-24
The command above outputs a Mongo data dump file named mongodump-2013-10-24 on /opt/backup directory, from the connection to mongodb1.example.com.
The second part of this strategy is restoring the second database by the data in the mongodump with mongorestore utility.
The mongorestore program loads data from either a binary database dump created by mongodump or the standard input (starting in version 3.0.0) into a mongod or mongos instance.
mongorestore --host=mongodb1.example.net --port=3017 --username=user --authenticationDatabase=admin /opt/backup/mongodump-2013-10-24
The command above writes the data from /opt/backup/mongodump-2013-10-24 file to the Mongo instance on the mongodb1.example.com connection.
WARNING: The process of mongorestore utility is NOT incremental. Restoring a database will delete all data prior to writing the mongodump data.

Problems and Limitations
- Late backup data: Since mongodump ran daily at a specified time, the data from that time until the moment of the database switch would be lost.
- Unavailability: The mongodump and mongorestore utilities took several hours to complete in the biggest databases. During the DB restore, nothing could be done as the Mongo data can't be used until mongorestore is finished. The DB will only be available when this is completed. Also, switching from a production environment to a mirror environment was a manual process which took some time.
- High disk usage: Restoring a whole database (or several DBs simultaneously) would take up disks inodes, as well as a toll of usage in your disks.
- Scalability limitations: Using a Mongo Docker instance for each database, even distributed by different servers, brought the need of setting up an instance, different network addresses and ports, and new backup containers (mongo-tools). A Mongo cluster would fit the needs for our applications and make database administration way simpler.
- Reserved memory: By default, each Mongo container will try to cache all available memory until 60%. Since we previously had 1 Mongo container on two application servers and 2 containers in the same application server, all of them had at least 60% busy (in use + cached). Whenever there is more than one Mongo container, they will dispute all available memory to reach 60% each. (2 -> 120%, 3 -> 180%, 4 -> 240%, etc.). For these reasons, it is very important to set adequate container memory limits.
- Amount of Docker volumes: MongoDB data, dumps, and metadata were scattered through several Docker volumes, mapped to different filesystem folders. Merging these databases would allow centralizing this data.
- Security and features: Upgrading to Mongo 4 would solve security issues and bring more features to improve DB performance and replication, like non-blocking secondary reads, transactions and flow control.
Objectives
To improve our production database and solve the identified limitations, our most clear objectives at this point were:
- Upgrading Mongo v3.4 and v3.6 instances to v4.2 (all community edition);
- Changing Mongo data backup strategy from mongodump/mongorestore to Mongo Replication;
- Merging Mongo containers into a single container and Mongo Docker volumes into a single volume.
And to get to these objectives, we defined the following plan:
Plan topics
- Prepare applications for Mongo connection string change;
- Assemble a cluster composed of 3 servers in different datacenters and regions;
- Generate and deploy keyfiles on the filesystems;
- Redeploy existing Mongo Docker containers with replSet argument;
- Define network ports;
- Deploy new 4 Mongo containers scaling to 3 (4 x 3 = 12) on a Mongo cluster;
- Add new Mongo instances to the replica set to sync from old Mongo containers;
- Stop Mongo containers from application servers and remove them from the replica set;
- Migrate backups and change which server they read the data;
- Merge data from 4 Mongo containers into one database;
- Unify backups.
We will publish a second part of this tutorial soon, where we will go through each of these topics.
Results
Some of the achieved results were:
- Fault-tolerance: Automatic and instant primary database switch.
- Data redundancy: Instantaneously synced redundant data.
- Inter-regional availability: Location disaster safeguarding.
- Cluster hierarchy: Mongo replication allows nodes priority configuration, which allows the user to order nodes by hardware power, location, or other useful criteria.
- Read operations balance: Read operations can be balanced through secondary nodes, like dashboards queries and mongodumps. Applications can also be configured (through Mongo connection URI) to perform read operations from secondary nodes, which increases database read capacity.
- Performance: Now that memory used and cached is right for the system needs, Mongo databases are hosted in dedicated servers, its version got bumped and the cluster can balance read operations, performance improvements exceeded the expectations.
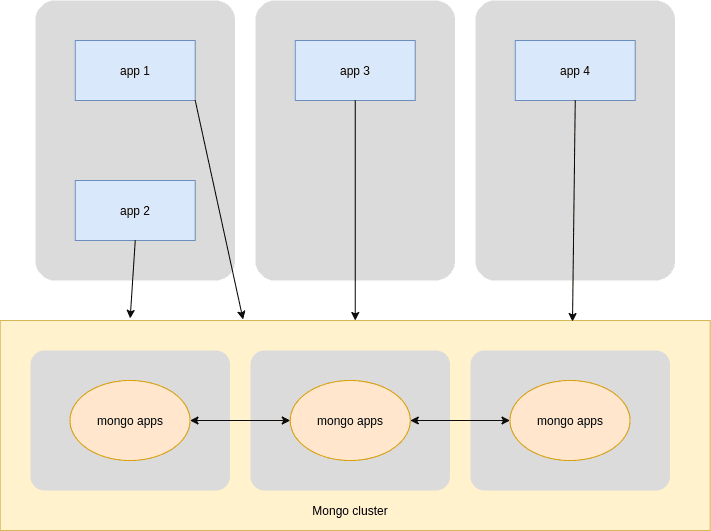
New Production Environment
- Production application servers should connect to the Mongo Production Cluster using replica set;
- The Mirror application server should connect to the Mongo Production Cluster and keep storing the most recent mongodumps;
- The Mongo Cluster secondary node should mongodump the cluster data to the Mirror environment, asking for it to another secondary node.
Conclusion
This post is more than about MongoDB replication on Docker. It is about a victory in stopping the infrastructure growth going in the wrong direction and having things done the way we thought they should be.
Much like a tree growing on a vase, we should plant it in a garden, where it can grow freely. Now, we will watch that tree scale without adding a new vase every time it needs to grow and not be afraid of breaking them. That's what high availability clusters are all about — building an abstract module for the application layer which can scale and keep being used the same way.
The whole process was done with intervals between major steps, to allow checking if the new strategy was working for us. We are very glad to have all the problems in the before section solved.
Achieving this means that we are now prepared to scale easily and sleep well knowing that MongoDB has (at least) database fault-tolerance and recovers by itself instantaneously — which lowers the odds of disaster scenarios.
Stay tuned for part 2, where we’ll explore the whole technical setup.
Meanwhile, you may like our post about Row vs. Columnar Databases or our full-stack tutorial on Creating a Public File Sharing Service with Vue.js and Node.js.
Another resource that you may find useful is our free data sheet on JavaScript Security Threats, which provides an overview of the most relevant attacks to JavaScript apps and how to prevent them.
Posted on April 21, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
