DataOps - A Made-Up Term or Actual Practice

JoLo
Posted on March 3, 2020
Data is the new oil - you probably have heard that and many businesses realized that proper data management is needed to get valuable insights. Nowadays, the data is coming from Various sources, arrives in high Velocity, and causes a high amount of Volume (see Doug Laney's Paper). A data warehouse is not sufficient anymore, and a data lake alone might also work neither when the process is missing. DataOps is a set of principles that adapts DevOps-methodologies and allows collaborative data management across the organization.
DevOps
DataOps is derived from the DevOps and adapts many processes and principles of it. To define the term DataOps, let's clarify DevOps first. After that, we discuss the processes of it and outline where does it fit in the DevOps- culture and what roles can be applied by working in a DataOps environment.
According to Wikipedia
DevOps is a set of practices intended to reduce the time between committing a change to a system and the change being placed into normal production, while ensuring high quality
In easy terms, it focuses on Continuous Integration and Continuous Delivery (CI/CD) as well as uses automation for the build lifecycle/pipeline. The key is to leverage on-demand IT resources and apply automated integration, testing, and deployment of code (see Fig. 1). A merge of software development and IT operations reduces time to deployment, decrease time to market, minimizes defects, and shortens the time required to resolve issues. All the big companies, such as Google or Amazon, release code multiple times per day.
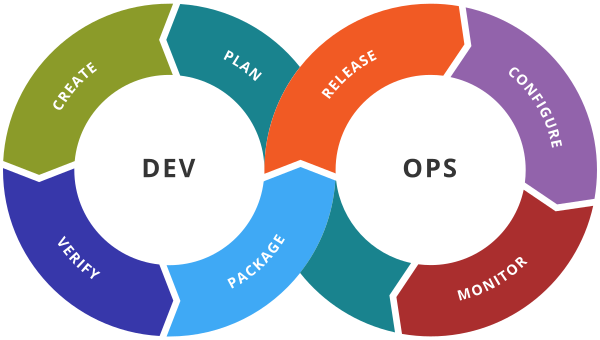
Fig. 1: The infinite lifecycle of DevOps methodologies
DataOps
Most of the time, you find the term DataOps. However, Zalando and companies also might name it as DataDevOps. However, we will use the term DataOps in this blog.
Gartner's Hype Cycle
Below, you see a simplified version of Gartner's Hype Cycle Data Management in 2019. As you can see, the term DataOps is at its beginning and an Innovation Trigger. It means that the publicity had triggered an early proof of concept (POC), and it will eventually reach the Peak of Inflated Expectations.
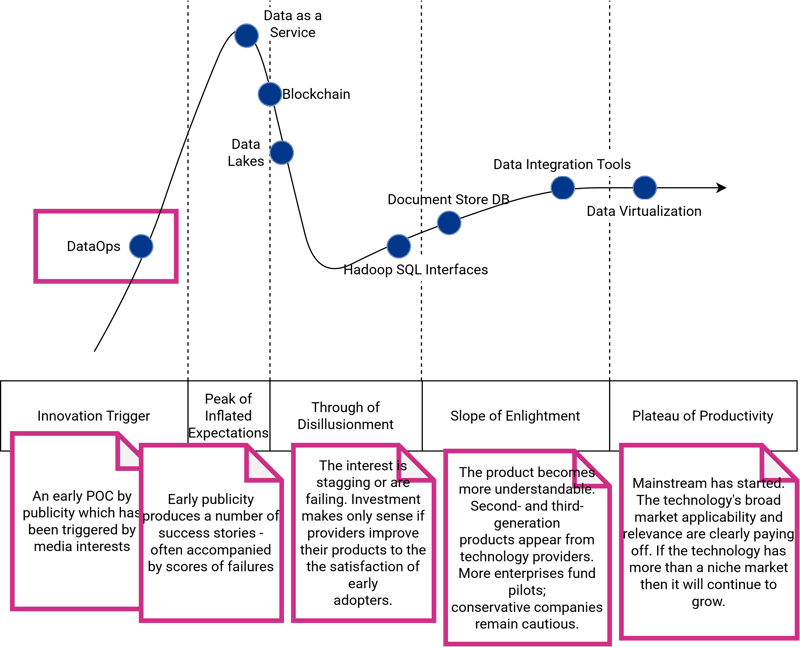
Fig. 2: Gartner's Hype Cycle of Data Management in 2019
Definition
Due to the early stage, we'll find different definitions online. According to Wikipedia:
DataOps is an automated, process-oriented methodology, used by analytic and data teams, to improve the quality and reduce the cycle time of data analytics.
However, it is a common misconception that it just applied for DevOps to data analytics. It communicates that data analytics can achieve what software development attained with DevOps.
Gartner defines it as follows:
DataOps is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization.
DataOps ensures an end-to-end cycle process beginning from the origin of ideas to the creation of charts, graphs, and models in a way which the end-user could make use. That means there is a cross-functional team effort needed and let the data team and users work together more efficiently and effectively.
The term DataOps already implies that it most heavily rely on all methodologies of DevOps:
- Optimizing Code
- Building
- Quality Assurance
- Delivery/Deployment
Principles and Processes
Let's create a better picture of where to classify DataOps in the DevOps culture. All the Ops are taking the same principles as DevOps, but other than GitOps, SecOps, or SysOps, DataOps is not working for the application at first glance but rather pull information from the app. That still does not mean that it does not work for the application but works for the business in general and provide insights (see Fig. 3).
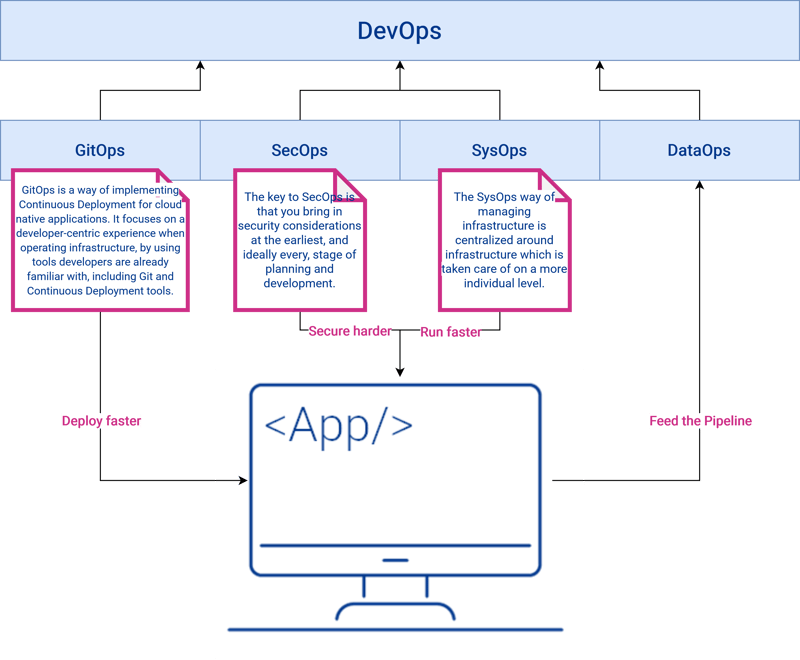
Fig. 3: DevOps Culture - Where to classify DataOps
Both DataOps and DevOps are agile or lean when the Software Development is as well. However, there is one more essential component to be added: Orchestration. Agile development and highly automated DevOps processes add significant value to data analytics. Still, it also requires to manage and orchestrate the data pipeline (see Fig. 4).
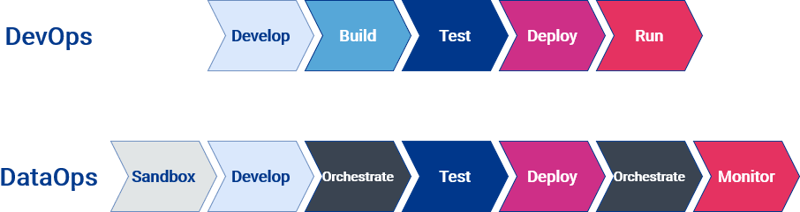
Fig.4: Processes of DevOps and DataOps
(Original: https://miro.medium.com/max/1289/1*0tDYzkNzHgW_T_7e5626og.png)
{kind=link}
Notice in the DataOps- Process, there is an orchestration before testing and orchestration after the deployment. The first orchestration takes raw data sources as input and produces analytical insights that create value for the business. It called "Value Pipeline" (see Fig. 5). According to the sources (see References), we often speak about data pipeline rather than lifecycle like in DevOps. That is due to the fact, that
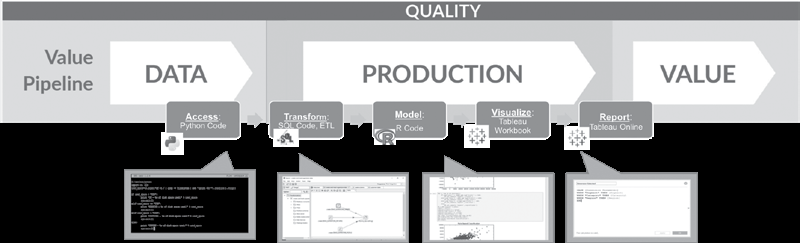
Fig.5 Value Pipeline (Source: The DataOps Cookbook; Christopher Bergh, Gil Benghiat, and Eran Strod)
The second orchestration is caused by the "Innovation Pipeline" (see Fig. 6). The Innovation Pipeline seeks to improve analytics by implementing new ideas that yield analytic insights. It is a feedback loop and spurs new questions and ideas for enhancing the current analytics value.
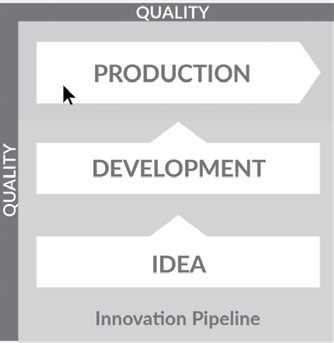
Fig. 6: Innovation Pipeline (Source: The DataOps Cookbook; Christopher Bergh, Gil Benghiat, and Eran Strod)
DevOps is seen as an infinite loop, whereas DataOps is drawn as pipeline intersecting the Value and Innovation Pipeline (see Fig. 7).
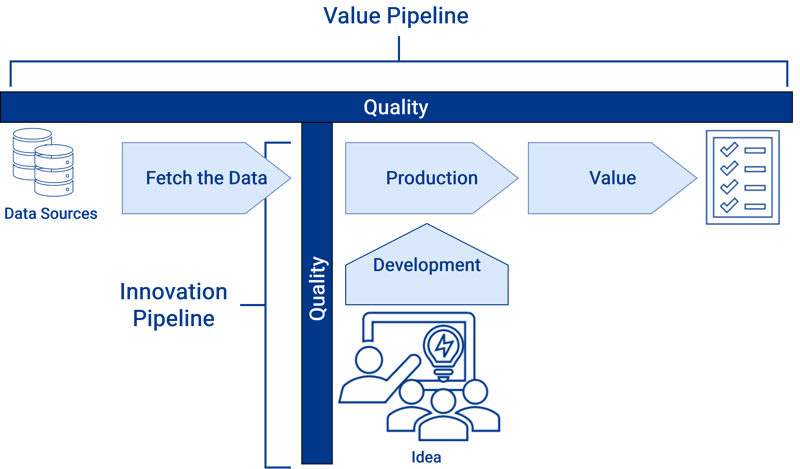
Fig. 7: The DataOps pipeline - Combined Value and Innovation Pipeline
DataOps Roles
DevOps was created to serve the needs of software developers. We know that Developers tend to learn new languages or try new frameworks or patterns. And that leads to more complexity for the DevOps-engineer, especially during the time of microservices and cloud services.
DataOps serves the needs of the business user (including the Developers) and relies on the incoming or resting data of the application and its environment. However, it can be seen as an own culture, including stakeholders (externals, or cross-functional team member), Data Scientist, Data Engineers, and Data Analyst. There are four key roles which can be practiced in more substantial companies by multiple people whereas in smaller companies multiple roles could be assigned to one person
Data Engineer
The Data Engineer is a software or computer engineer that lays the groundwork for other members of the team to perform analytics. The Data Engineer moves data from operational systems (ERP, CRM, MRP, …) into a data lake and writes the transforms that populate schemas in data warehouses and data marts. The data engineer also implements data tests for quality.
Data Analyst
The data analyst takes the data warehouses created by the data engineer and performs analytics of a massive amount of data to stakeholders. The data analyst creates visual representations of data to communicate information in a way that leads to insights either on an ongoing basis or by responding to ad-hoc questions. This role summarizes past data (descriptive analytics), while future predictions are the domain of the data scientist.
Data Science
Data scientists perform research and tackle open-ended questions. A data scientist has domain expertise, which helps him or her create new algorithms and models that address questions or solve problems.
DataOps Engineer
The DataOps Engineer applies Agile Development, DevOps, and statistical process controls to data analytics. He or she orchestrates and automates the data analytics pipeline to make it more flexible while maintaining a high level of quality. The DataOps Engineer uses tools to break down the barriers between operations and data analytics, unlocking a high level of productivity from the entire team.
Tooling
The toolset of DevOps can also be applied for the DataOps- stack. In the end, there is no difference. We orchestrate databases like applications as we do with Kubernetes and deploy the analytics platform in a Docker container. We test the quality of data in a staging environment and let the stakeholders review it before we monitor it.
Additionally, a Data Engineer creates an ETL- pipeline in Apache Airflow to automate the integration of incoming data. Nevertheless, the Data Scientist uses Jupyter Notebooks to add unseen insights into the Innovation Pipeline. In contrast, the Data Analyst creates a dashboard using Tableau or PowerBI.
Conclusion
DataOps is a specialization of the DevOps-methodology for Data&Analytics. It is not yet actual practice but still noticeable in the media and seen as Innovation Trigger. The principles are the same: highly automated, cross-functional, distributed skillset of people, and shared responsibilities. The focus is different as it is for SysOps, GitOps, or SecOps. DataOps focuses more on automating the Data & Analytics processes and work closely with the business users like Product Management.
However, it is not just DevOps for Data but rather a set of principles that embrace the value working with analytics and streamline processes to continuously monitor, test, and orchestrate the data with user priorities. It is open for innovations and agile because it needs to adapt to the changes in the environment. A DataOps team comes with different roles, and they come with a different toolset to harmonize the back-and-forth between development (analysts, scientists, engineers) and operations (production team, monitoring, stakeholders).
The goal of DataOps is to create analytics in the individual development environment, advance into production, receive feedback from users, and then continuously improve through further iterations. If we are honest, data is what is driving us, and it comes in various formats and too fast. DataOps simplifies the complexity of data analytics creation and operations by streamlining and automating the analytics development lifecycle #DataIsKey.
References
- DataOps is NOT Just DevOps for Data
- Big Data and DevOps: The Case for Bringing Them Together
- Data DevOps - What and Why - DZone Big Data
- DataOps
- Building a DataOps Team
- Build Trust Through Test Automation and Monitoring
- DataOps: Applying DevOps to Data - Continuous Dataflows Built With a DataOps Platform - DZone Big Data
- DataDevOps: A Manifesto for a DevOps-like Culture Shift in Data & Analytics
Posted on March 3, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.