Serverless App - Extração de Textos com Exibição de Layouts com Textract

Gustavo Mainchein
Posted on October 7, 2024

Entendendo o Textract:
O Amazon Textract é um serviço avançado de Machine Learning (ML) da AWS projetado para extrair automaticamente textos impressos ou manuscritos, além de identificar elementos de layout e dados estruturados a partir de documentos digitalizados. Ele é capaz de processar diversos tipos de documentos, como formulários, relatórios e recibos, facilitando a automação de tarefas que exigem a extração e organização de informações. A tecnologia é particularmente útil em cenários onde grandes volumes de documentos precisam ser analisados, permitindo uma leitura precisa e eficiente dos conteúdos, sejam eles simples ou complexos.
A base desse serviço é a tecnologia de reconhecimento óptico de caracteres (OCR), que utiliza algoritmos sofisticados de correspondência de padrões para analisar imagens de texto. O OCR realiza uma comparação detalhada, caractere por caractere, entre o conteúdo visualizado e um banco de dados interno, decodificando a imagem para gerar um texto digital legível. No entanto, o OCR convencional pode ser limitado quando se trata de interpretar variações complexas de escrita, especialmente manuscrita. Para superar esses desafios, o Amazon Textract adota o reconhecimento inteligente de caracteres (ICR), uma evolução do OCR. O ICR utiliza técnicas avançadas de machine learning que treinam o sistema para reconhecer caracteres da mesma forma que um humano faria, aprimorando a precisão na leitura de diferentes estilos de escrita, mesmo em formatos menos padronizados.
"Antes de prosseguirmos, é fundamental esclarecer o objetivo desta publicação. Vamos apresentar um exemplo prático de como desenvolver tanto o back-end quanto o front-end para integrar o Amazon Textract, com o foco específico em destacar informações importantes (highlights) em documentos PDF. Isso será feito utilizando o recurso de Layout do serviço, que permite identificar e manipular a estrutura visual dos documentos, como tabelas, parágrafos e outras áreas de interesse. Vale ressaltar que, neste conteúdo, não exploraremos outras funcionalidades do Textract, concentrando-se exclusivamente na extração de layout e destaques em PDFs.”
Como funciona a integração com o Textract:
A AWS possui diversos portais que contém documentações completas sobre o processo de integração com cada serviço, de acordo com sua linguagem. No nosso caso, iremos utilizar o Node.js, que é um software de código aberto, multiplataforma, baseado no interpretador V8 do Google e que permite a execução de códigos JavaScript fora de um navegador web.
No caso do Javascript, a AWS possui um hub grande de integrações, onde você pode realizar a integração com os serviços por meio de módulos. Pensando na integração com o Textract, você pode seguir a documentação e executar os seguintes comandos de instalação:

Nesta publicação, iremos utilizar o método "AnalyzeDocumentCommand” da API do Textract, cuja documentação deixo ao lado: https://docs.aws.amazon.com/AWSJavaScriptSDK/v3/latest/client/textract/command/AnalyzeDocumentCommand/
Aplicação Back-End:
Para estruturarmos a aplicação back-end, iremos contar com a utilização do Serverless Framework como biblioteca e framework de projeto, pois essa solução irá nos apoiar nas configurações dos recursos da Infraestrutura e publicação das funções Lambda e API Gateway.
- Começando pelo arquivo serverless.yml, temos:
# Nome da organização da conta to Serverless Framework
org: publicacao
# Nome da aplicação presente na organização
app: documents-analyze
# Nome do serviço pertencente à aplicação
service: back-end
provider:
# Nome do provider de infraestrutura
name: aws
# Linguagem e versão aceita pelo Lambda
runtime: nodejs20.x
# Timeout default das funções Lambda
timeout: 30
# Estrutura da role de IAM para permissionamento das funções Lambda
iamRoleStatements:
- Resource: "*"
Effect: Allow
Action:
- s3:*
- textract:*
plugins:
# Plugin (módulo NPM) para apoiar na execução em ambiente de desenvolvimento
- serverless-offline
# Estruturação das funções Lambda
functions:
# Nome único da função Lambda
extractText:
# Caminho de pastas que a função se encontra
handler: src/extractText.handler
# Eventos que serão o gatilho para triggar a função, no caso aqui é o API Gateway
events:
- httpApi:
path: /{documentName}
method: get
- Seguindo para configuração do arquivo package.json (arquivo padrão para execução de aplicações Node.js):
{
"name": "back-end",
"version": "1.0.0",
"main": "src/extractText.mjs",
"license": "ISC",
"type": "module",
"dependencies": {
"@aws-sdk/client-s3": "^3.658.1",
"@aws-sdk/client-textract": "^3.658.1",
"@aws-sdk/s3-request-presigner": "^3.658.1"
},
"devDependencies": {
"serverless-offline": "^14.3.2"
}
}
- Agora, no arquivo src/extractText.mjs, temos:
```import import {
TextractClient,
AnalyzeDocumentCommand,
} from "@aws-sdk/client-textract";
import { S3Client, GetObjectCommand } from "@aws-sdk/client-s3";
import { getSignedUrl } from "@aws-sdk/s3-request-presigner";
// Infrastructure Layer
const region = "us-east-1";
const textractClient = new TextractClient({ region });
const s3Client = new S3Client({ region });
const BUCKET_NAME = "";
const DOCUMENTS_FOLDER = "";
const SIGNED_URL_EXPIRATION = 3600;
// Service Layer: Handles Textract document analysis
const analyzeDocument = async (bucketName, documentPath) => {
const command = new AnalyzeDocumentCommand({
Document: {
S3Object: {
Bucket: bucketName,
Name: documentPath,
},
},
FeatureTypes: ["LAYOUT"],
});
const response = await textractClient.send(command);
return {
blocks: response.Blocks,
pages: response.DocumentMetadata?.Pages,
};
};
// Service Layer: Generates signed URL for S3 object
const generateSignedUrl = async (bucketName, documentPath) => {
const command = new GetObjectCommand({
Bucket: bucketName,
Key: documentPath,
});
return getSignedUrl(s3Client, command, { expiresIn: SIGNED_URL_EXPIRATION });
};
// Domain Layer: Main handler function
const handler = async (event) => {
try {
const { documentName } = event.pathParameters;
const documentParsedName = decodeURIComponent(documentName) + ".pdf";
const documentPath = ${DOCUMENTS_FOLDER}/${documentParsedName};
const documentData = await analyzeDocument(BUCKET_NAME, documentPath);
const signedUrl = await generateSignedUrl(BUCKET_NAME, documentPath);
return createSuccessResponse({ documentData, signedUrl });
} catch (error) {
console.error("Error processing document:", error);
return createErrorResponse("Failed to process document.");
}
};
// Helper functions: Response formatting
const createSuccessResponse = (data) => ({
statusCode: 200,
body: JSON.stringify(data),
});
const createErrorResponse = (message) => ({
statusCode: 500,
body: JSON.stringify({ error: message }),
});
export { handler };
Com isso, no back-end está devidamente estruturado e para você executá-lo localmente, siga os comandos abaixo:
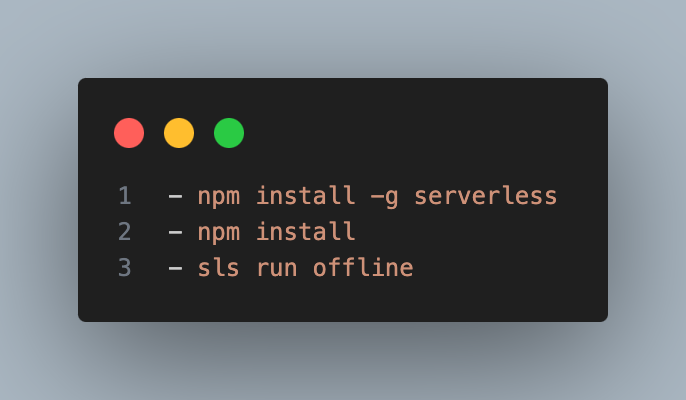
A partir de então, você estará apto a fazer requisições na sua rota local a partir de qualquer navegador ou plataforma de API, como [Postman](https://www.postman.com/) ou [Apidog](https://apidog.com/).
**Aplicação Front-End:**
Para estruturação da aplicação Front-End, utilizamos o Tailwindcss + Vite + React TS, onde você pode encontrar o tutorial de inicialização do projeto na seguinte documentação: https://tailwindcss.com/docs/guides/vite
Após o passo-a-passo acima executado, seu projeto precisará de algumas dependências para exibir os PDFs em tela, assim como os highlights nos textos. Pensando nisso, utilizaremos a biblioteca react-pdf para podermos fazer esse processo no Front-End.
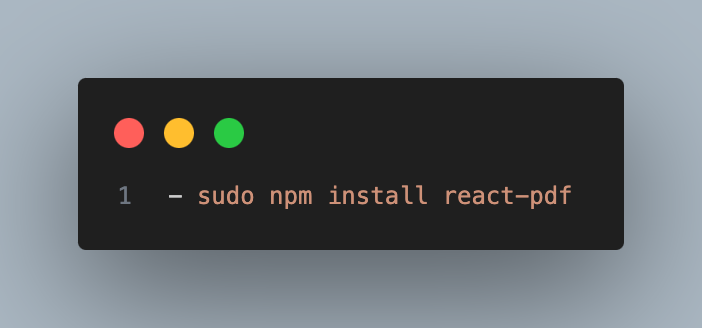
Lembre-se de instalar a biblioteca como super usuário, pois ela utiliza configurações de sistema para realizar a exibição do documento.
Com isso feito, você precisará apenas criar um arquivo de componente e alterar o App.tsx, conforme orientações abaixo:
- Começando pela criação do src/components/TextDetection.tsx, que será o responsável pela exibição do PDF e marcação das caixas de posição das extrações:
```import import React, { useEffect, useRef, useState } from "react";
import { Props } from "../@types/blocks";
import { pdfjs } from "react-pdf";
import "react-pdf/dist/esm/Page/AnnotationLayer.css";
import "react-pdf/dist/esm/Page/TextLayer.css";
// Configuração do worker do PDF.js
pdfjs.GlobalWorkerOptions.workerSrc = new URL(
"pdfjs-dist/build/pdf.worker.min.mjs",
import.meta.url
).toString();
// Função para detectar cliques em caixas delimitadoras
const handleBoxClick = (
e: MouseEvent,
block: any,
width: number,
height: number,
setModalText: (text: string) => void
) => {
const canvas = e.target as HTMLCanvasElement;
const rect = canvas.getBoundingClientRect();
const x = e.clientX - rect.left;
const y = e.clientY - rect.top;
const box = block.Geometry.BoundingBox;
const left = width * box.Left;
const top = height * box.Top;
const boxWidth = width * box.Width;
const boxHeight = height * box.Height;
if (x >= left && x <= left + boxWidth && y >= top && y <= top + boxHeight) {
setModalText(block.Text);
}
};
// Função para desenhar as caixas delimitadoras
const drawBoundingBoxes = (
ctx: CanvasRenderingContext2D,
width: number,
height: number,
canvas: HTMLCanvasElement,
response: Props["response"],
setModalText: (text: string) => void
) => {
response.blocks.forEach((block) => {
if (block.BlockType === "LINE") {
const box = block.Geometry.BoundingBox;
const left = width * box.Left;
const top = height * box.Top;
ctx.strokeStyle = "red";
ctx.lineWidth = 2;
ctx.strokeRect(left, top, width * box.Width, height * box.Height);
canvas.addEventListener("click", (e) =>
handleBoxClick(e, block, width, height, setModalText)
);
}
});
};
// Serviço para carregar o PDF e desenhar caixas delimitadoras
const loadPdfAndDraw = async (
documentUrl: string,
canvasRefs: React.MutableRefObject<HTMLCanvasElement[]>,
response: Props["response"],
setModalText: (text: string) => void
) => {
try {
const pdf = await pdfjs.getDocument(documentUrl).promise;
for (let pageNumber = 1; pageNumber <= pdf.numPages; pageNumber++) {
const page = await pdf.getPage(pageNumber);
const viewport = page.getViewport({ scale: 1 });
const canvas = canvasRefs.current[pageNumber - 1];
if (!canvas) continue;
const ctx = canvas.getContext("2d");
if (!ctx) continue;
canvas.width = viewport.width;
canvas.height = viewport.height;
await page.render({ canvasContext: ctx, viewport }).promise;
drawBoundingBoxes(
ctx,
viewport.width,
viewport.height,
canvas,
response,
setModalText
);
}
} catch (error) {
console.error("Erro ao carregar o PDF:", error);
}
};
// Componente principal
const TextDetectionCanvas: React.FC<Props> = ({
response,
documentUrl,
qtdPages,
}) => {
const canvasRefs = useRef<HTMLCanvasElement[]>([]);
const [modalText, setModalText] = useState<string | null>(null);
const closeModal = () => setModalText(null);
useEffect(() => {
if (documentUrl && response) {
loadPdfAndDraw(documentUrl, canvasRefs, response, setModalText);
}
}, [documentUrl, response]);
return (
<div>
{/* Renderizar os canvas */}
{Array.from({ length: qtdPages }).map((_, index) => (
<canvas key={index} ref={(el) => (canvasRefs.current[index] = el!)} />
))}
{/* Modal de texto */}
{modalText && <TextModal modalText={modalText} closeModal={closeModal} />}
</div>
);
};
// Componente para o modal de texto
const TextModal: React.FC<{ modalText: string; closeModal: () => void }> = ({
modalText,
closeModal,
}) => (
<div
style={{
position: "fixed",
top: 0,
left: 0,
width: "100vw",
height: "100vh",
backgroundColor: "rgba(0, 0, 0, 0.5)",
display: "flex",
alignItems: "center",
justifyContent: "center",
zIndex: 1000,
}}
>
<div
style={{
backgroundColor: "white",
padding: "20px",
borderRadius: "8px",
boxShadow: "0 2px 10px rgba(0, 0, 0, 0.3)",
}}
>
<div className="font-bold text-2xl flex gap-10">
<h1>Veja os Detalhes</h1>
<button onClick={closeModal}>X</button>
</div>
<p className="mt-5">Texto: {modalText}</p>
</div>
</div>
);
export default TextDetectionCanvas;
- Agora finalizando com a alteração do App.tsx, que será o responsável por fazer a integração com o Back-End a partir de uma lista de documentos:
```import import React, { useEffect, useState } from "react";
import TextDetectionCanvas from "./components/TextDetection";
import { Response } from "./@types/blocks";
// Constants
const DOCUMENTS = [
"LISTA DE DOCUMENTOS"
];
// Service Layer: Handles document fetching
const fetchDocumentData = async (
documentName: string,
setDocumentData: (data: Response) => void,
setDocumentUrl: (url: string) => void,
setPageNumber: (page: number) => void
) => {
try {
const response = await fetch(http://localhost:3000/${documentName});
const data = await response.json();
setDocumentData(data.documentData);
setPageNumber(data.documentData.pages);
setDocumentUrl(data.signedUrl);
} catch (error) {
console.error("Failed to fetch document data", error);
}
};
// Domain Layer: Main Application Component
const App: React.FC = () => {
const [documentData, setDocumentData] = useState();
const [documentUrl, setDocumentUrl] = useState("");
const [pageNumber, setPageNumber] = useState(1);
const [selectedDocument, setSelectedDocument] = useState(
DOCUMENTS[0]
);
// Fetch document data whenever the selected document changes
useEffect(() => {
setPageNumber(0);
setDocumentUrl("");
fetchDocumentData(
selectedDocument,
setDocumentData,
setDocumentUrl,
setPageNumber
);
}, [selectedDocument]);
return (
documents={DOCUMENTS}
selectedDocument={selectedDocument}
onDocumentSelect={setSelectedDocument}
/>
{documentUrl === "" ? (
Carregando...
) : (
documentData={documentData}
documentUrl={documentUrl}
pageNumber={pageNumber}
/>
)}
);
};
// UI Layer: Document Selector Component
const DocumentSelector: React.FC<{
documents: string[];
selectedDocument: string;
onDocumentSelect: (doc: string) => void;
}> = ({ documents, selectedDocument, onDocumentSelect }) => (
value={selectedDocument}
onChange={(e) => onDocumentSelect(e.target.value)}
>
{documents.map((document, index) => (
{document}
))}
);
// UI Layer: Document Viewer Component
const DocumentViewer: React.FC<{
documentData: Response | undefined;
documentUrl: string;
pageNumber: number;
}> = ({ documentData, documentUrl, pageNumber }) => (
response={documentData as Response}
documentUrl={documentUrl}
qtdPages={pageNumber}
/>
);
export default App;
Com as configurações realizadas, basta iniciar seu projeto por meio dos comandos abaixo:

**Resultado Final:**
Após a execução de todos os passos acima, você irá ter uma aplicação funcional que estará analisando os documentos, extraindo os textos e informando as posições onde encontram-se cada marcação daquele texto no PDF.
Exemplo do resultado final:


Pensando até mesmo em evoluções futuras, como trata-se de uma solução de OCR e sabemos que erros podem ocorrer, você pode contar com a utilização de um LLM e uma base de conhecimento para poder indexar esses textos, corrigi-los e gerar respostas inteligentes a partir de determinado assunto.
Com isso, notamos que a aplicação *serverless* desenvolvida para extração de textos e exibição de layouts com Amazon Textract demonstrou uma solução eficaz para automatizar a análise de documentos em larga escala. Utilizando OCR avançado e ICR, a ferramenta não apenas extrai informações textuais, mas também identifica e organiza estruturas complexas, como tabelas e parágrafos, diretamente em PDFs. Com a integração entre o *back-end* (Node.js e Serverless Framework) e o *front-end* (React, Vite e TailwindCSS), a aplicação permite uma visualização intuitiva das marcações e dos textos extraídos.
Posted on October 7, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
October 7, 2024