Anonymous Web Scraping with Node.js, Tor, Puppeteer and cheerio

George Gkasdrogkas
Posted on January 25, 2020

Web Scraping is the technique of extracting data from websites. The term is used typically for automated data extraction. Today, I am going to show you how to crawl websites anonymously. The reason why you want to hide your identity is due to the fact that many web servers apply rules to websites which ban IPs after a certain amount of continuous requests. We are going to use Puppeteer for accessing web pages, cheerio for HTML parsing, and Tor to run each request from a different IP address.
While the legal aspects of Web Scraping vary, with many grey zones,
remember to always respect the Terms of Service of each web page you
scrape. Ben Bernard has wrote a nice article about those legal issues.
Setting Up Tor
First things first, we have to install our Tor client by using the following command.
sudo apt-get install tor
Configure Tor
Next, we are going to configure our Tor client. The default Tor configuration uses a SOCKS port to provide us with one circuit to a single exit node (i.e. one IP address). This is handy for everyday use, like browsing, but for our specific scenario we need multiple IP addresses, so that we can switch between them while scraping.
To do this, we'll simply open additional ports to listen for SOCKS connections. This is done by adding multiple SocksPort options to main configuration file under /etc/tor.
Open /etc/tor/torrc file with your preferred editor and add the next lines in the end of the file.
There a couple of things to notice here:
- The value of each
SocksPortis a number, the port that Tor will listen for connections from SOCKS-speaking applications, like browsers. - Because
SocksPortvalue is a port to be open, the port must not already be used by another process. - The initial port starts with value
9050. This is the default SOCKS of the Tor client. -
We bypass value
9051. This port is used by Tor to allow external applications who are connected to this port to control Tor process. - As a simple convention, to open more ports, we increment each value after
9051by one.
Restart the tor client to apply the new changes.
sudo /etc/init.d/tor restart
Create a new Node project
Create a new directory for your project, I’ll call it superWebScraping.
mkdir superWebScraping
Navigate to superWebScraping and initialize an empty Node project.
cd superWebScraping && npm init -y
Install the required dependencies.
npm i --save puppeteer cheerio
Browse with Puppeteer
Puppeteer is a headless browser that uses DevTools Protocol to communicate with Chrome or Chromium. The reason why we don’t use a request library, like tor-request, is due to the fact that request libraries cannot process SPA websites that load their content dynamically.
Create an index.js file and add the below script. The statements are documented inline.
Run the script with
node index.js
You should see the Chromium browser navigating to https://api.ipify.org like the following screenshot
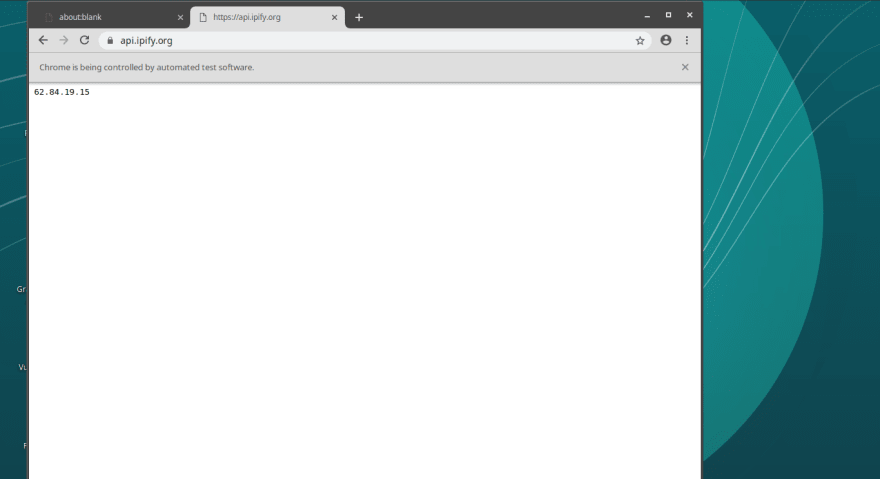
There is a reason why I chose the specific web page in my example. https://api.ipify.org is able to send us our public IP address. This is the IP you are browsing the web, without using Tor.
Change the above code by adding the following key in puppeteer.launch statement:
We provide the --proxy-server argument to our browser. The value of this argument tells the browser to use a socks5 proxy in our local machine on top of port 9050. The value of the port is one of the values we provided earlier in torrc file.
Now run again the script.
node index.js
This time you should see a different IP address. This is the IP that comes with Tor circuit.
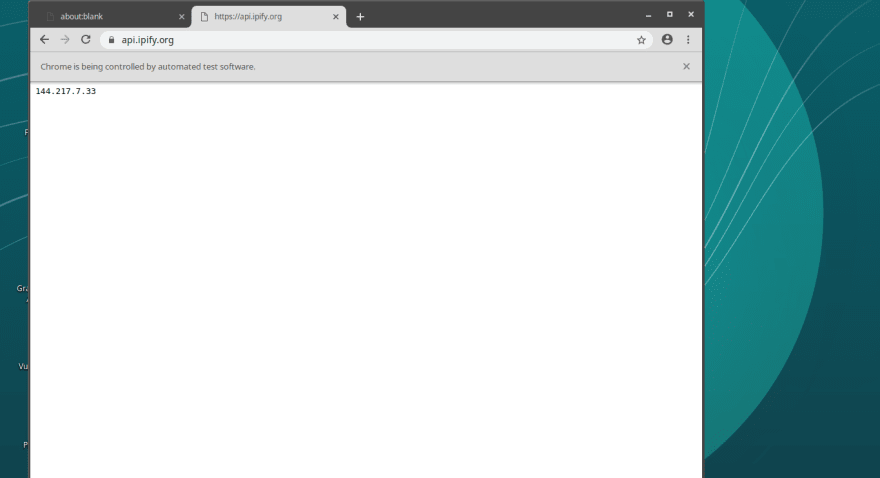
Mine is 144.217.7.33, but you might have a different one. Note that if you run the script again on the same port 9050 you'll get the same IP address as before.
This is the reason why we opened many ports in our Tor configuration. Try to use another port, like 9051. The IP will not be the same.
Scrape content with Cheerio
Now that we have a nice way to get our pages, it's time to scrape them. We are going to use the cheerio library. Cheerio is an HTML parser designed to use the same API as jQuery. Our task is to scrape the last 5 post titles of Hacker News.
Let's navigate to Hacker News.
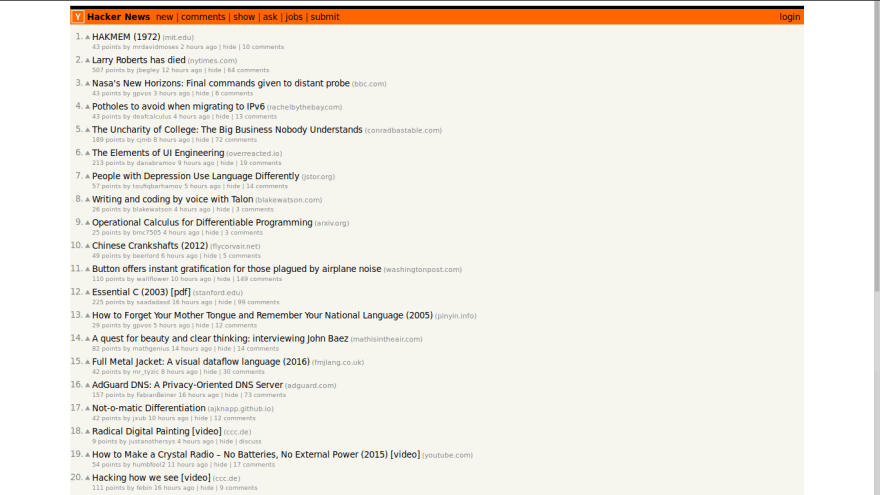
We want to scrape the first 5 titles ("HAKMEM (1972), "Larry Roberts has died", etc). Inspecting the title of an article using my browser's DevTools I can see that each article is being wrapped with an HTML link element which has storylink class.

The procedure we are going to follow can be denoted by the bellow list:
- Launch a browser instance in headless mode with Tor proxy
- Create a new page
- Navigate to https://news.ycombinator.com/
- Get page HTML content
- Load the HTML content in Cheerio
- Create an array to save the article titles.
- Access all the elements that have
storylinkclass - Get only the first 5 such elements, using Cherrio's slice() method.
- Iterate through those 5 elements using Cherrio's each() method.
- Append each article title in the array.
And here is the output of the above code.
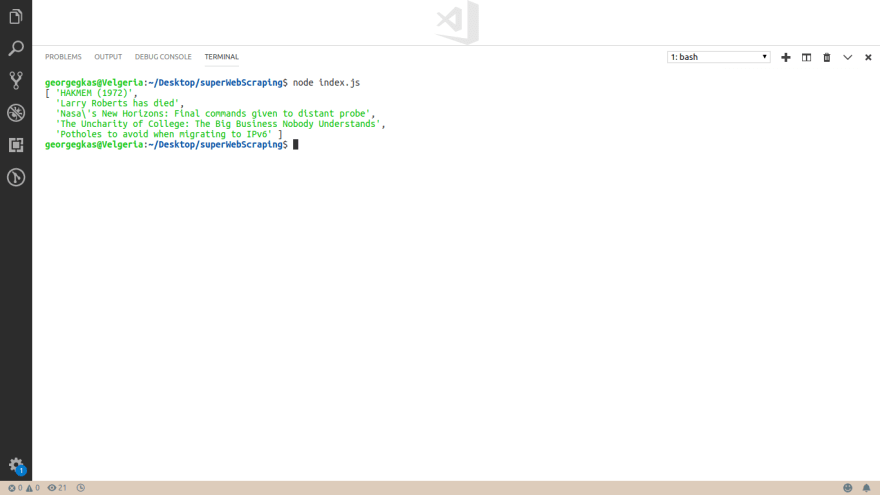
Continuous scraping with different IP
The last thing to consider is to take advantage of all the SOCKS ports we defined in torrc file. This is quite easy. We’ll define an array with each item to be a different port number. Then we’ll rename main() to scrape() and we will define a new main() function that will call scrape() each time with a different port.
Here is the complete code.
Conclusion
This article was intended to provide you with a gentle introduction to Web Scraping. Thank you for taking time to read it. 🙏
Posted on January 25, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related