
Francisco
Posted on February 19, 2023

 |
|---|
| Arquitectura del Taller de Python + Kinesis Firehose + S3 |
En este taller, aprenderemos cómo procesar archivos CSV con AWS utilizando Kinesis Data Firehose y S3. Además, utilizaremos Python como fuente de datos desde una maquina externa para enviar los datos al flujo de Firehose.
Requisitos previos:
- Una cuenta de AWS con acceso a Kinesis Data Firehose y S3.
- Python 3.x instalado en local.
- Tener instalada la liberias boto3 y pandas
Paso 1: Configurar el bucket de S3
Lo primero que debemos hacer es crear un bucket de S3 donde almacenaremos nuestros datos. Para hacer esto, vamos a la consola de AWS y seleccionamos S3. Luego, hacemos clic en el botón "Crear bucket" y seguimos las instrucciones para nombrar el bucket y establecer las opciones de configuración.
Paso 2: Configurar el flujo de Kinesis Data Firehose
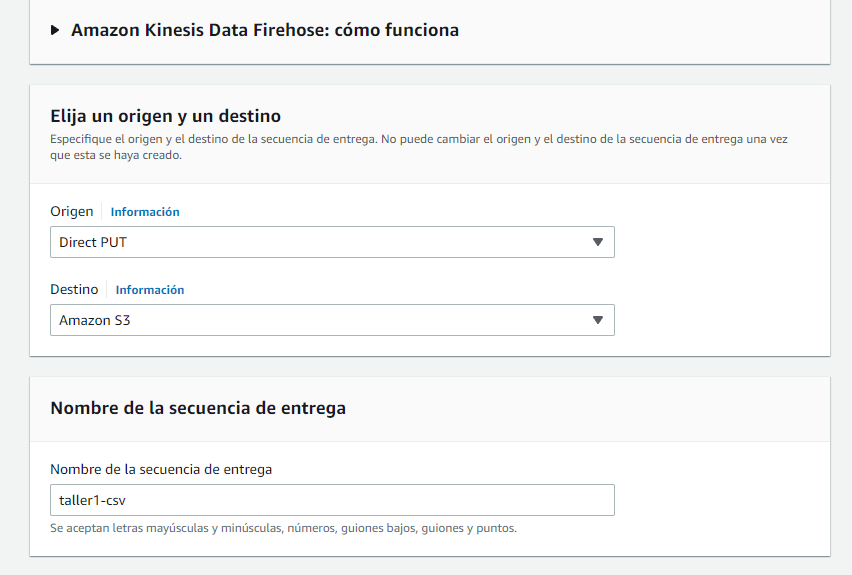
A continuación, creamos un flujo de Kinesis Data Firehose que recibirá los datos de nuestra fuente de datos y los almacenará en nuestro bucket de S3. Para hacer esto, vamos a la consola de AWS y seleccionamos Kinesis Data Firehose. Luego, hacemos clic en "Crear flujo de Firehose" y seguimos las instrucciones para nombrar nuestro flujo y establecer las opciones de configuración.
Para la opciones de configuración:
Seleccionaremos en origen como Direct PUT
Destino S3
Nombre de la secuencia de entrada cualquier nombre para el ejemplo colocare taller1-csv. El nombre que se coloque se convertira en el identificacion del servicio el cual recibira la trama que enviemos mas adelante.
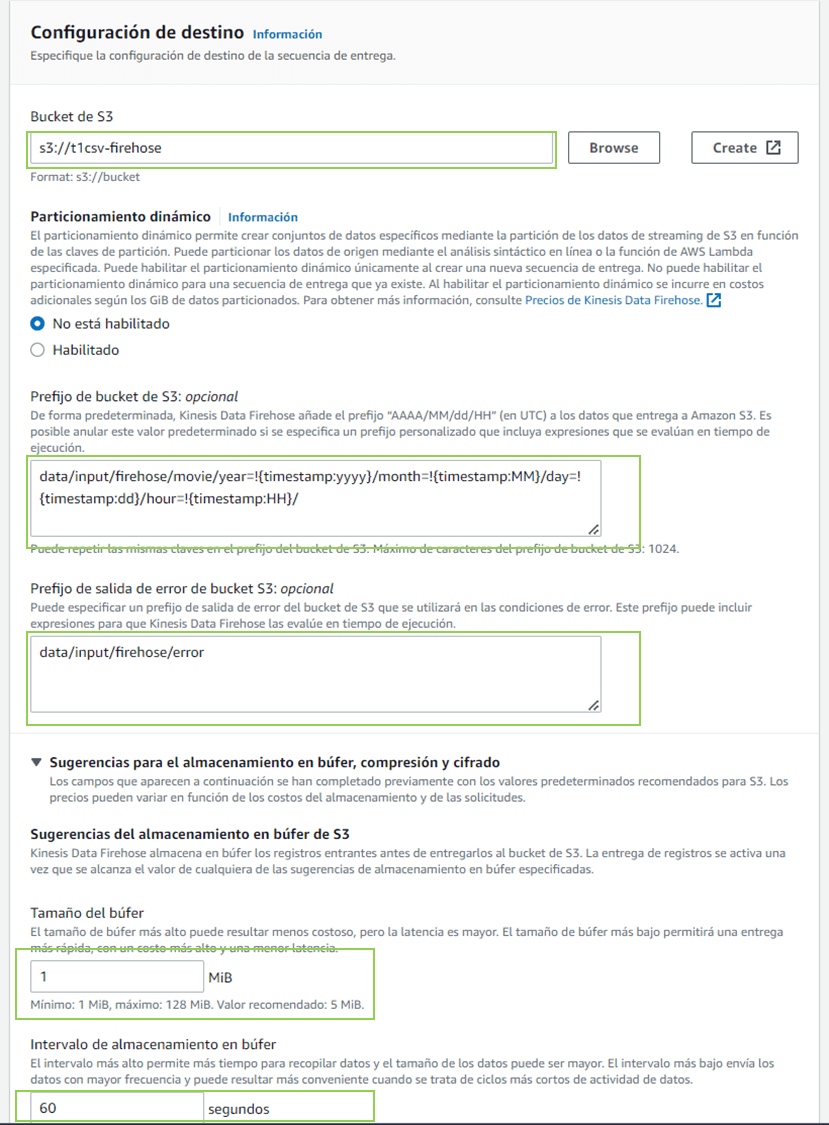
Prefijo de bucket de S3
data/input/firehose/movie/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/Prefijo de salida de error de bucket S3
data/input/firehose/error
Los prefijos crear las carpetas necesarias de no existir al momento de recibir la trama o caer en error.
Tamaño del búfer 1 MiB (datos)
Intervalo de almacenamiento en el búfer 60 segundos
Para las configuraciones del búfer para que la trama sea procesada debe cumplir cualquiera de las dos opciones el tamaño o el intervalo
Paso 3: Configurar la fuente de datos
Antes de configurar la fuente de datos requerimosPara poder conectarnos a servicio de AWS desde una maquina externa necesitaremos crear una clave de acceso para esto se debe realizar los siguientes pasos:
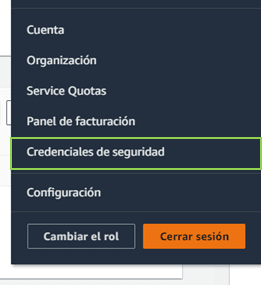
Haz clic en tu nombre de usuario en la esquina superior derecha de la página y selecciona "My Security Credentials" (Mis credenciales de seguridad).
Si se te solicita, ingresa tu nombre de usuario y contraseña de AWS nuevamente.En la pestaña "Access keys" (Claves de acceso), haz clic en "Create New Access Key" (Crear nueva clave de acceso).
Haz clic en el botón "Download Key File" (Descargar archivo de clave) para descargar la clave de acceso en un archivo .csv. También puedes copiar y pegar la clave de acceso y la clave secreta en un lugar seguro.Asegúrate de guardar el archivo de la clave de acceso de manera segura, ya que no se mostrará nuevamente. Si pierdes la clave de acceso, deberás crear una nueva.
Una vez que hemos creada la clave de acceso y nuestro flujo de Kinesis Data Firehose, debemos configurar la fuente de datos para que sepa de dónde tomar los datos. En este caso, utilizaremos Python como fuente de datos. Para hacer esto, escribiremos un script Python que lea los datos del archivo CSV y los envíe al flujo de Kinesis Data Firehose utilizando la biblioteca Boto3 de AWS para interactuar con los servicios de AWS desde nuestro código Python.
import boto3
import time
import json
import pandas as pd
AWS_ACCESS_KEY = #credenciales
AWS_SECRET_KEY = #credenciales
REGION_NAME = #Region
DeliveryStreamName = 'taller1-csv' #paso 2
firehose = boto3.client('firehose',aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=REGION_NAME
)
record = {}
bad_lines = []
column_names = ["MovieID", "YearOfRelease", "Title" ]
df = pd.read_csv("movie_titles.csv", encoding = "ISO-8859-1" , names=column_names , error_bad_lines=False)
for index, row in df.iterrows():
record = {'MovieID':row[0],
'YearOfRelease':row[1],
'Title':row[2]
}
response = firehose.put_record(
DeliveryStreamName = DeliveryStreamName,
Record = {
'Data': json.dumps(record)
}
)
print('Dato de movie enviado a Kinesis Data Firehose : \n' + str(record))
time.sleep(.5)
Paso 4: Enviar los datos al flujo de Kinesis Data Firehose
Ahora, podemos ejecutar nuestro script Python y enviar los datos al flujo de Kinesis Data Firehose. Los datos serán transformados y almacenados en nuestro bucket de S3 según las configuraciones establecidas en los pasos anteriores.
Paso 5: Verificar los datos almacenados en S3
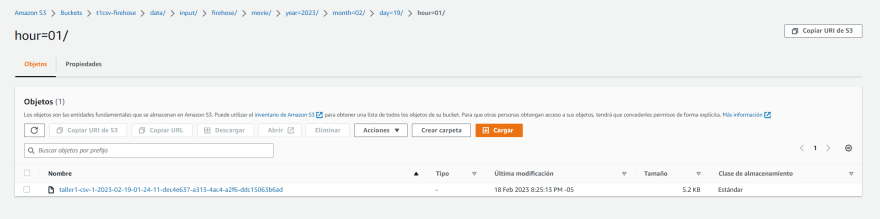
Finalmente, podemos verificar que nuestros datos se han almacenado correctamente en nuestro bucket de S3. Podemos acceder a nuestro bucket desde la consola de AWS y verificar que el archivo CSV se ha transformado en el formato deseado.
Conclusión
En este taller, hemos aprendido cómo procesar archivos CSV utilizando AWS con Kinesis Data Firehose y S3. Además, hemos utilizado Python como fuente de datos para enviar los datos al flujo de Firehose. AWS ofrece una amplia gama de servicios y herramientas para procesar y analizar datos, lo que hace que sea fácil y escalable trabajar con grandes volúmenes de datos en la nube.
** Despligue con Cloudformation**
Description: Stack Lab Firehose
Parameters:
NombreBucket:
Description: bucketS3
Type: String
Default: aws-firehose
Resources:
deliverystream:
DependsOn:
- deliveryPolicy
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: taller1-csv
ExtendedS3DestinationConfiguration:
BucketARN: !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
BufferingHints:
IntervalInSeconds: '60'
SizeInMBs: '1'
CompressionFormat: UNCOMPRESSED
Prefix: data/input/firehose/movie/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
ErrorOutputPrefix: data/input/firehose/error
RoleARN: !GetAtt deliveryRole.Arn
s3bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Join [ -, [ !Ref NombreBucket, !Ref AWS::AccountId , 'movie' ] ]
deliveryRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Sid: ''
Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: 'sts:AssumeRole'
Condition:
StringEquals:
'sts:ExternalId': !Ref 'AWS::AccountId'
deliveryPolicy:
Type: AWS::IAM::Policy
Properties:
PolicyName: firehose_delivery_policy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 's3:AbortMultipartUpload'
- 's3:GetBucketLocation'
- 's3:GetObject'
- 's3:ListBucket'
- 's3:ListBucketMultipartUploads'
- 's3:PutObject'
Resource:
- !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
- !Join
- ''
- - 'arn:aws:s3:::'
- !Ref s3bucket
- '*'
Roles:
- !Ref deliveryRole
Posted on February 19, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related