Techniques for building predictable and reliable API: Part 2

Aleksei Popov
Posted on March 26, 2024
Introduction
In the first part, I talked about how to apply the idempotency technique to achieve exactly once guarantee for API invocation.
In this one, I plan on talking about asynchronous processing and API techniques to build scalable and reliable.
Asynchronous processing
There are operations that are better processed asynchronously, meaning that instead of doing the job right now, we push it into the task queue and then notify the originators about the result once it is ready.
It could be useful if interaction is required with external systems that may be slow, operate asynchronously, having strict rate limits, or even have problems with availability.
Okay, what's the problem?
Let us imagine that we have the following system where the main components are:
(Originator) Revenue calculation service - This service is part of an analytics product that periodically requests data for the purpose of calculating revenue. It might analyze sales transactions, payments, or other financial data to provide insights into revenue trends, performance against forecasts, and areas for financial improvement.
(Originator) Risk assessment service - This service evaluates the risk associated with various operations or transactions. It could be assessing credit risk, fraud risk, operational risks, or other types of financial or non-financial risks. Its purpose is to mitigate potential losses by identifying high-risk scenarios and suggesting preventive measures.
Transaction Categorisation service - This service schedules transactions classifications into categories such as groceries, utilities, entertainment, revenue, etc.
Categorization Processor service - This service is purely a backend service responsible for the actual processing and categorization logic of transactions.
Webhooks delivery service - This service manages the sending of webhooks, which are automated messages sent from one app to another when something happens.
Bank transactions provider service - This service acts as an interface to bank systems for retrieving transaction data. It may authenticate, fetch, and format bank transaction data for use by other components in the financial technology ecosystem.
Queue (Kafka / Azure Service Bus / RabbitMq / etc)
In the following diagram, you can see a blueprint of use cases. Both use cases consist of seven steps, starting with 10 Pull transactions for the last period (month or year) and ending with retrieving processing results by ID.
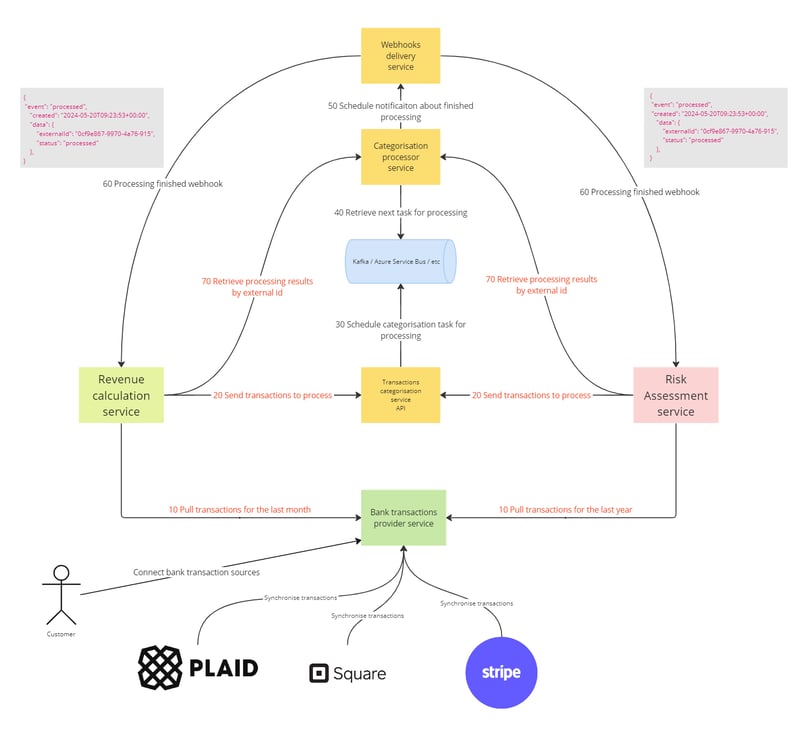
The Transaction Categorization service API requires the provision of an external ID. Under this external ID, all the transactions will be held and categorized. Since the architecture of the transaction categorization implies that it learns over time from data associated with a specific external ID, sending transactions for the same entity (for example, a B2C company) to different external IDs will lead to categorization issues and poor quality. Therefore, the main recommendation is to accumulate all transactions for the same entity together. Consequently, both the Revenue Calculation and Risk Assessment services provide a shared CustomerId throughout the entire system.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
},
}
This is the webhook payload example received by both originators (Revenue Calculation and Risk Assessment services). However, since they use the same external ID, how can we distinguish between the two originators? Relying on the date? Unlikely, as it is not a reliable approach.
Okay, what if we prohibited having multiple processings in progress for a specific external ID?
This approach might slightly improve the situation if the originators somehow track that they have started processing. However, a problem arises if the first originator begins processing and finishes, but the webhook doesn't reach the originator for any reason. Meanwhile, another originator starts and successfully completes another processing, and the webhook is delivered to both. In this case, we will face an issue because the first originator might mistakenly pick up the second webhook.
Technique 1: Metadata
In order to distinguish webhooks somehow, we may utilize attaching custom metadata to the send transaction to process the request.
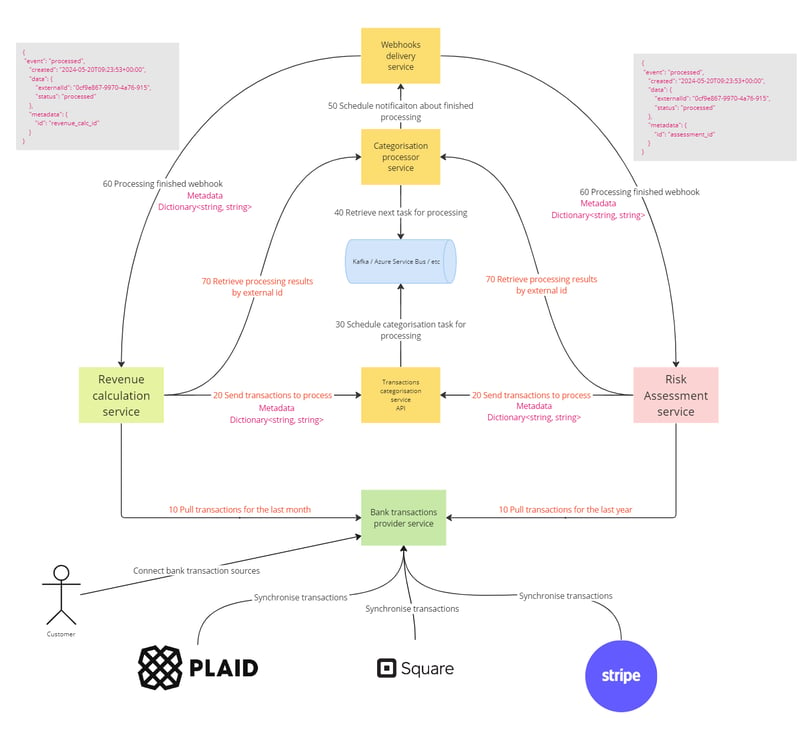
As you can see here, in this example, the Revenue Calculation service attached specific metadata in order to identify its processing result and skip others.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
},
"metadata": {
"id": "revenue_calc_id"
}
}
However, since the categorisation processing service does not support searching by metadata due to potential complexity, we still face a situation with a race condition when webhooks are delayed, sent out of processing order, or when originators are pulling stale data.
Okay, then we need something much simpler!
Technique 2: Two-Steps processing
To completely avoid race conditions due to the distributed nature of the system and network failures, we can improve the architecture by introducing the following features.
- Sending transactions to the Process API will return a task ID related to this processing.
- The Send Transactions to Process API will accept an idempotency key to avoid starting duplicate tasks. It won't affect consumers but will save resources and reduce operational complexity.
- Task IDs will be added to the webhook payload.
- The Retrieve Processing Results API will be improved to allow searching by task ID.
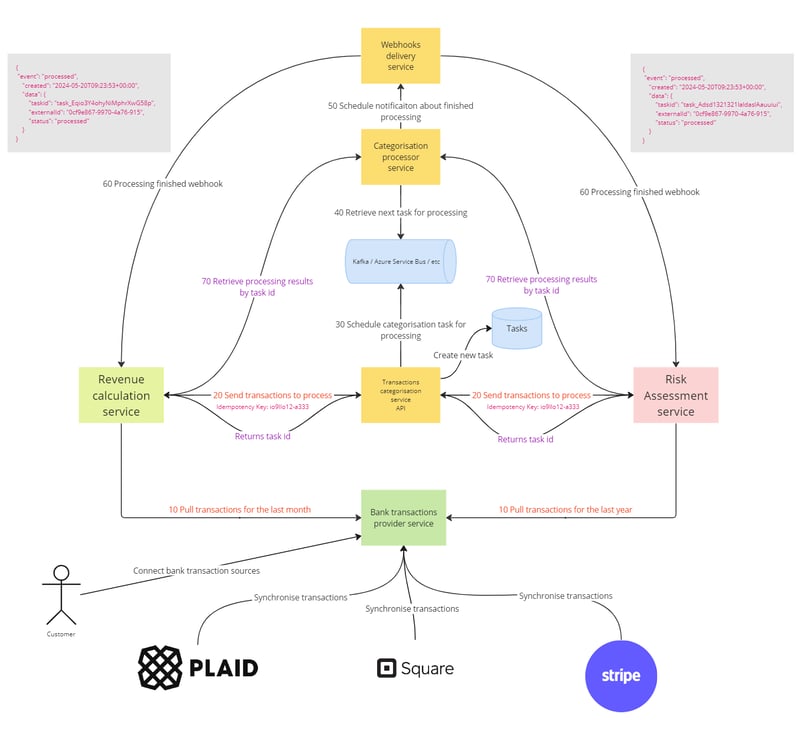
This is the payload example contains taskid value. Thus, originators can distinguish between webhooks and identify only those that are related to them.
{
"event": "processed",
"created": "2024-05-20T09:23:53+00:00",
"data": {
"taskid": "task_Eqio3Y4ohyNiMphrXwG58p",
"externalId": "0cf9e867-9970-4a76-915",
"status": "processed"
}
}
Asynchronous processing and timeouts
The last thing I would like to talk about in this article is related to timeouts.
In nature, there are two main types of communication between two services or components: Fire and forget and Request and Reply.
Fire and forget
This is a communication pattern where a client sends a message (or request) to a server and immediately continues its execution without waiting for a response. The server might process the message at some point in the future, but the client does not know when or indeed if the message has been successfully received or processed. Technically, it even doesn't care wherther it was processed or not.
Usually, this pattern refers to asynchronous nature and is used when the client does not require an immediate response or confirmation. It's often used for logging, sending notifications, or other tasks where receiving a response is not critical to the continuation of the client's processing.
Request and Reply
This is a communication pattern where a client sends a request to a server and waits for a response. The server processes the request and then sends back a reply to the client.
Usaully, this pattern refers to synchronous nature, meaning the client blocks and waits until the response is received before continuing its execution.
However, the interesting thing is that even when I use asynchronous (non-blocking for current execution) communication for account charging or order delivery, I am still interested in a reply. If there is no reply after some time, what should the system do? Cancel? Retry? Send an alert to the on-call team?
The main idea is that despite the communication approach you use (synchronous or asynchronous), you should be concerned about possible network failures and plan for them before they happen.
The simplest approach would be to incorporate a timeout on the caller side, similar to what we have in a blocking request. To implement this, we need to understand where to store the expiration date. The answer lies in the domain objects. Timeout behavior is usually part of their lifecycle. For instance, if a document request for a loan application isn't completed within 14 days, we should close this document request and probably try again.
Conclusion
In this article, I have covered several problems related to the nature of distributed systems and the complexity of asynchronous operations, unavoidable network failures, and possible techniques to mitigate them, thereby improving the quality attributes of the system and experience for both customers and internal users.
See you next time!
Posted on March 26, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.