Different ways of making REST Endpoint inference with Sagemaker SDK

Ayush Rastogi
Posted on May 2, 2022
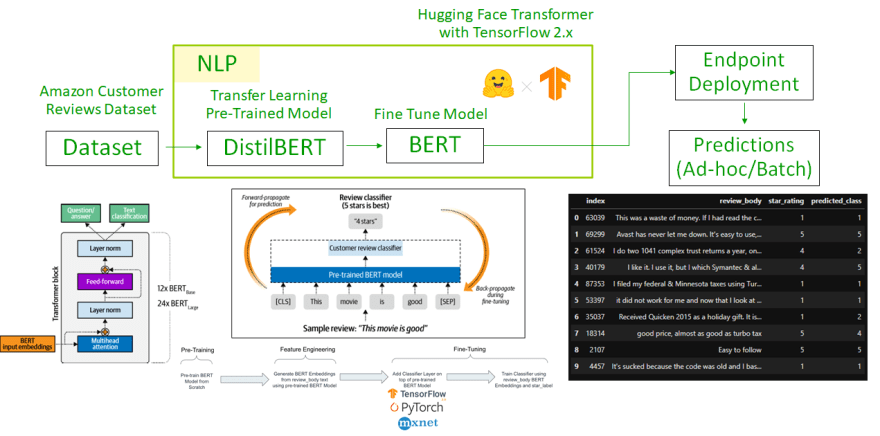
In this article we are going to see two ways of making inference from a machine learning model endpoint using Sagemaker SDK. The machine learning model is trained on 'Amazon Customer Reviews Dataset' and can predict customer review rating on a scale of 1-5. As a part of transfer learning, I have used BERT model with pre-training carried out through DistilBERT, using Hugging face transformer, which provides bi-directional attention, and TensorFlow. Details regarding model implementation are shown below.
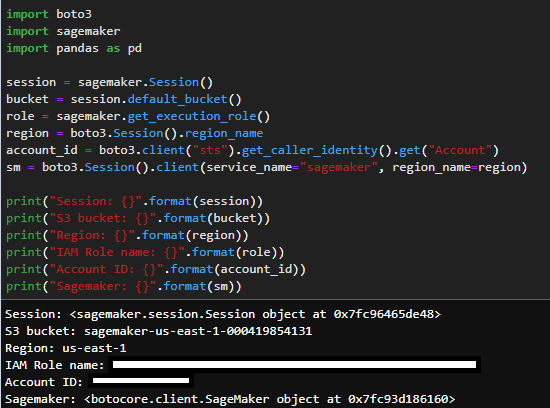
The first step for the inference script is to include the boiler plate details like session, bucket, role, region, account ID and Sagemaker object.
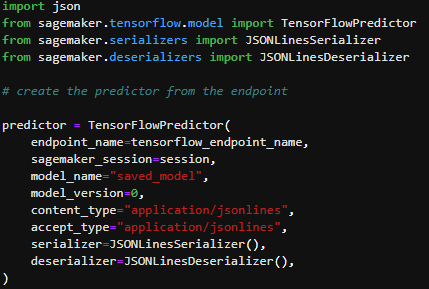
The second step is to include the details completed during the model deployment stage. This will include the training job name, model name, and endpoint details.

Using the deployment stage details, a predictor object needs to be created which includes session details and the endpoint name. We are using JSONserializer and JSONdeserializer to format the input, interpret it and then deserialize it into an object type.
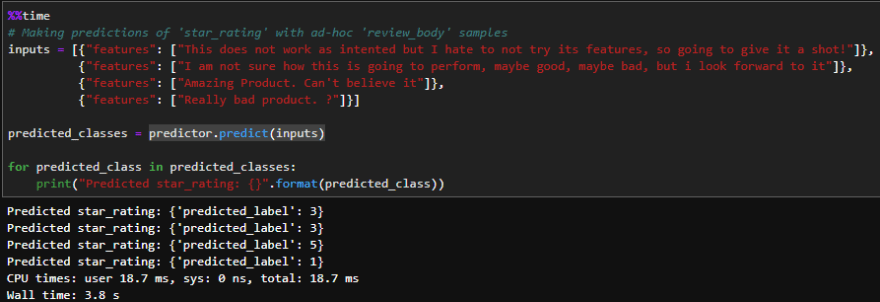
Category 1: Real-time/Ad-hoc predictions
Once this predictor is created, it can be used to make ad-hoc predictions by providing inputs as features, shown below. Here function predictor.predict() is being used to make real-time predictions against Sagemaker endpoints with python objects. Four examples of Amazon reviews have been shown here.
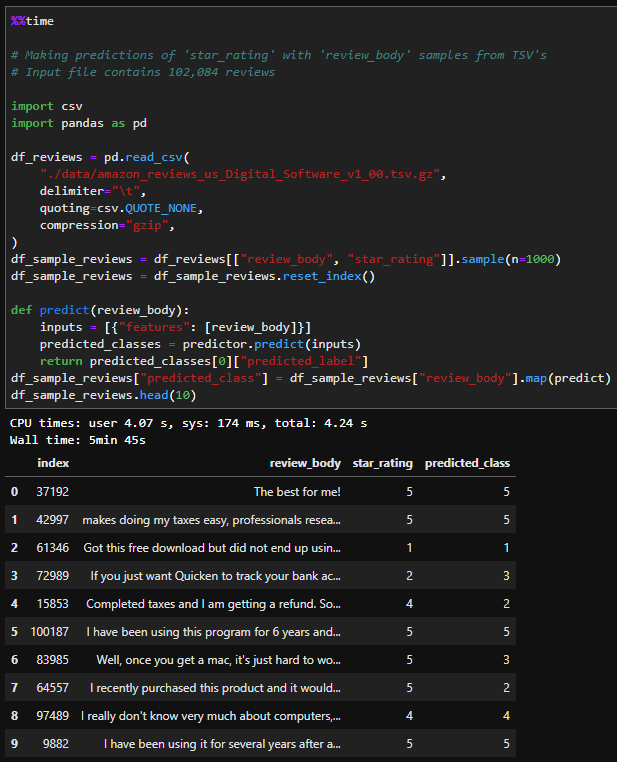
Category 2: Batch predictions
The reviews are stored in a .tsv file (tab separated value) and can be processed all at once. Predictions of 1000 sample reviews out of 102,084 reviews, were made which had a duration of 5 mins 45 seconds based on the compute being used. By providing the argument of 10, on the df_sample_reviews.head() call, we can retrieve the small number and validate the predictions. The column which serves as an input is 'review body' and predictions are compared against 'star rating'.
Predictions can also be invoked model as a SageMaker Endpoint directly using the following HTTP request/response syntax. This approach is primarily being used when models are deployed as microservices in a production environment.
References:
- Data Science on AWS, Chris Fregly and Antje Barth
- https://docs.aws.amazon.com/index.html?nc2=h_ql_doc_do_v
- https://sagemaker.readthedocs.io/en/stable/
Posted on May 2, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.