Effector: we need to go deeper

Victor Didenko
Posted on March 19, 2020

This is a script of my talk for the Effector meetup #1
You can find the slides here, and the video from the meetup here
⚠️ Note! Information in this article has been outdated a bit, and could be not specifically accurate. But overall architecture view is still relevant.
Hi, folks!
So, Effector. Why does anyone even need to look under the hood? Why go deeper? As you know, it can be dangerous, and you may get stuck in Limbo.
I'll tell you why I needed this knowledge and why it can be useful for you.

This is a photo from the 1966 24 Hours of Le Mans. Three Ford GT40s are finishing almost at the same time. Ford management wanted all three cars to cross the finish line together because this would make a perfect advertising photo.
When I create an effect and run it three times, I imagine it this way:

This effect launches three parallel asynchronous operations that work independently of each other. However, in some cases, it may be useful to coordinate them somehow, just like Ford management coordinated the cars at the 1966 24 Hours of Le Mans.
Let's say, you have an effect that submits a form to the server. When the user clicks the button, the effect is launched. But if the user clicks the button again, it's undesirable that the effect be launched for the second time. You have to either block the button or ignore any further clicks/effects.
A more interesting example is the auto-suggest function. When the user types in four letters, the effect launches to get suggestions from the server. However, if the user types in the fifth letter, the previous request is not relevant anymore. You have to cancel (or ignore) it and launch the effect again to get suggestions for a five-letter string.
It occurred to me that this is quite a frequent use case, so I wrote my own library called ReEffect, which slightly extends the effects from Effector adding a run strategy to them. I fully covered the code with tests, but when I tried to use my ReEffect with forward – it didn't work.

(Hey! I've written ReEffect. Yeah, but it doesn't work with forward. But… the tests…)
Just in case you’re curious, it works now, you can use it :)
I was in despair and asked Dmitry Boldyrev, the author of Effector, for help. He briefly told me about its internals and operation in general. And when I started to dig deeper, I began to realize that my understanding of Effector was like a pile of non-related pieces of a puzzle. It seemed simple, just four entities (event, store, effect, and domain) and 10-15 API methods. I could combine those pieces, glue them together by two or three, and use this Frankenstein's monster somehow. However, I didn't have the whole picture in my head, and the pieces didn't fit into the solved puzzle. Until I started to dig deeper.

I also hope that knowing how Effector works under the hood will help you to do this puzzle, if you have a similar pile of scattered puzzle pieces in your head as I did. It will help you to gain a clear understanding of Effector, or, at least, build the foundation for its understanding.
Let's start from afar. From the 18th century :)

This is Leonhard Euler, mathematician, engineer, and scientist, who lived in the 18th century. Once Euler was asked to solve a problem known as the Seven Bridges of Königsberg.

The city of Königsberg in Prussia (now Kaliningrad, Russia) was situated on both sides of the Pregel River and included two large islands – Kneiphof and Lomse – which were connected to each other, or to the two mainland portions of the city, by seven bridges. The problem was to devise a walk through the city that would cross each of those bridges once and only once.

If you don't know anything about this problem, you can stop here and try to find a solution :)
Euler found a solution and this solution is considered to be the first theorem of what now is called the graph theory.

Do you know what a graph is?

Imagine that each small circle in the image above is an object. Each structure in this image is called a graph. One object represents one vertex (or node) of the graph. The so-called list or bidirectional list is also a graph. A tree is a graph. Actually, any set of vertexes/nodes somehow connected with a set of edges (or links) is called a graph. There is nothing scary here.
I dare say you have already worked with graphs. A DOM tree is a graph. A database is a graph of tables and relations. Your friends and the friends of your friends on Facebook or VK form a graph. A file system is a graph (many modern file systems support hard links, and thus become "true" graphs, not trees). Wikipedia pages with internal links form a graph.
The whole human population of the Earth forms a huge graph of relationships, where you (yes, you, reader!) are just six (or fewer) social connections away from Donald Trump (as well as from Vladimir Putin). This is known as the 6 handshakes rule.
You may ask, how is all this related to Effector?
All Effector entities are connected in a graph! That's how!
If you think a bit and try to make logical connections between different entities, you will see it yourself.
Check out the following code:
const change = createEvent()
const onclick = change.prepend(
e => e.target.innerText
)
const { increment, decrement } = split(change, {
increment: value => value === '+',
decrement: value => value === '-'
})
const counter = createStore(1)
.on(increment, state => state + 1)
.on(decrement, state => state - 1)
const foo = counter.map(state => state % 3 ? '' : 'foo')
const bar = counter.map(state => state % 5 ? '' : 'bar')
const foobar = combine(foo, bar,
(foo, bar) => foo && bar ? foo + bar : null
)
sample({
source: change,
clock: foobar.updates.filterMap(value => value || undefined),
target: change
})
Here is a working REPL, where you can try out this code online
Let's draw logical connections between different entities in this code:

In a slightly better way, the result looks as follows:

As you can see, this is a graph.
I'd like to emphasize that we haven't even looked under the hood yet, all we've done so far is draw logical connections between the Effector entities. And now we've got a graph.
The most exciting part is that Effector actually works this way!
Any entity generated by Effector creates a node (or nodes) in a structural graph. And any Effector API creates and/or connects different nodes in this structural graph.
And I think it is great! We have a logical graph of relationships between different entities. Why not implement it using a physical structural graph of some nodes?
And now, we will open the hood and look under it!

This is what an Effector node looks like:

You can check out this interface here. I just rewrote it from Flow to Typescript and renamed a little
An Effector node is just an object with the following fields:
-
next– links to the next nodes. These are the edges of our graph. -
seq(from "sequence") – a sequence of steps for that node. The sequence of steps is what makes the types of nodes unique. We will take a closer look at the steps in a few minutes. -
scope– arbitrary data necessary for the steps. This object will be passed to the step during the node execution. -
reg(an unstable field that can be removed) – references to the stores necessary for the steps. -
meta– arbitrary metadata, for example, the name of an entity is stored here. -
family– describes the ownership graphs:-
type– the role of this node in each ownership graph. -
links– links to the nodes that belong to the given node. In other words, they indicate the nodes we need to delete when we delete this node. -
owners– links to the nodes that own the given node. That is to say, these links indicate the nodes from which we have to remove the link to the given node when we delete this node.
-
Thus you can see that we have more than one graph here: a computation graph (by links in the next field), two ownership graphs (by links in family.links and family.owners), and a graph of links to the stores (in the reg field).
Below, I will concentrate on fields next and seq, because these are the two main fields, where the logic of the whole process is described.
So, how does the Effector kernel work in a simple case?
Here are five nodes connected in a graph (in a tree configuration, but that's not the point). And at some moment, the data appears!
When the data is put in the node, this node is added to a queue, and the main cycle begins.
In each cycle iteration, the Effector kernel takes a node from the queue and executes all its steps.
Then the kernel adds all the nodes from
nextto the queue.Then it repeats stages 2, 3 and 4 until there is nothing in the queue.

By the way, this graph transversal algorithm is called the breadth-first search. Effector uses a slightly modified breadth-first search algorithm with priorities. We will see it later.
Let's have a closer look at these three points:
- What kind of data is it and how does it get into the node?
- Various kinds of steps and how they differ
- Queue

So, what kind of data is it and how does it get into the node?
The answer is events!
When you call an event (a simple function), all it does is send the payload to the graph and launch a computation cycle.
Also, of course, there are effects and stores.
You call an effect the same way you call an event (like a simple function) and thus send data into the graph. And when the operation is over, the resulting data also gets into the graph (into events/nodes .finally/.done/.fail).
The store has undocumented method .setState() that also transmits the payload to the graph. In fact, this doesn't differ much from the event.
But what exactly is an event?

An event is a simple function that receives the payload and calls function launch with itself and the received data. What is launch? launch is the only function exported by the Effector kernel and the only way to put data into the graph and launch a computation cycle.
"But what the heck, I can't see any nodes or graphs here!", – you might say. Well, that's because I haven't shown you the main thing:
Field .graphite:
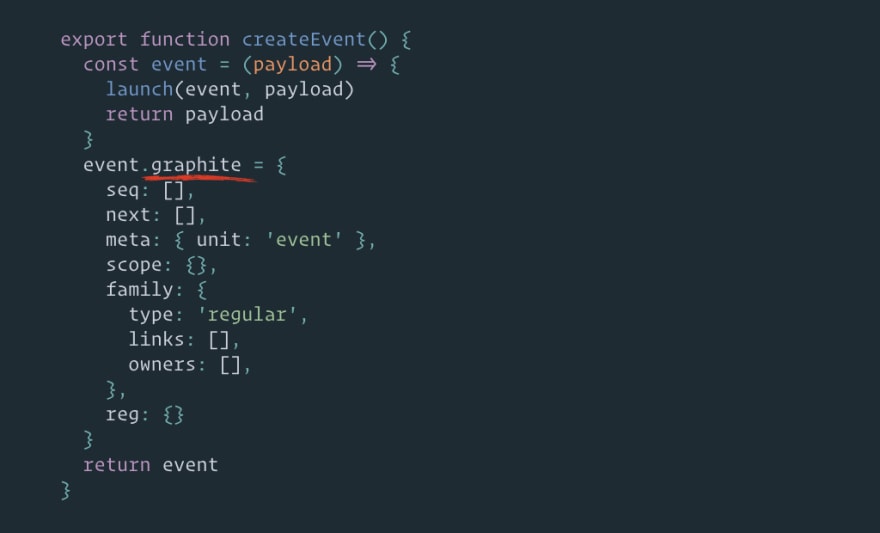
This is where our node is located. It's a communication point and a bridge from the event function to the graph.
Any Effector API works with field .graphite (or if there is no such field, the Effector API thinks that it works with the node directly).
So, an event is a function with a node in field .graphite. A store is an object with a node in field .graphite. And an effect is also a function with a node in field .graphite (an effect is a complex entity that contains other nodes, but the main node – the bridge from the function and the entry point – is located in the .graphite field).
And here is an interesting thing – the Effector API doesn't care what exactly is connected to the node. It can be a function, like events and effects, or a plain object like a store, or an async generator, which yields values when its node receives the given value. Or this can be a field in a prototype chain, then all instances of a class will be connected to the same graph node (I don't know how this can be useful, though).

What are steps and how do they differ?
A step is just an object with field .type. Inside the Effector kernel, there is a big switch (step.type) that decides what to do depending on the type of the step. For convenience, the Effector package exports the step object to create different types of steps.
There are six types of steps:

-
compute– a step to do pure computations. It accepts input data and returns new transformed data. For example, the reducer function instore.onis launched inside thecomputestep. The map function instore.mapalso runs inside this step. -
run– the same ascompute, although aimed to execute side-effects. When the kernel meets steprun, the computation for the node is postponed (I will show it later). Thus, any side-effects are executed after any pure computation. This step is used, for example, inwatchnodes (yes, the.watchmethod creates a new node). -
filter– a step to stop computations. It accepts input data and returnstrueorfalsevalues. And in case it'sfalse, the branch of computation stops here, i.e. no further steps will be executed and the nodes from thenextfield will not be added to the queue. This step is used, for example, in.filterand.filterMapnodes. -
barrier– a step with no logic, but this step either postpones the execution of the node or cancels it if the execution has already been postponed. This step is used incombineandsample. -
check– a step with two checks:-
defined– checks that the input data is not undefined -
changed– checks that the input data is different from the data saved in the store
-
-
mov– a step with almost internal logic. I will not describe it here, but long story short, this step copies data from/to the store and/or internal stack fields. I call them registers, like registers in CPU, e.g. AX or BX.

Now, the queue. Or queues, because there are five of them in the Effector kernel :) Here is the difference from the usual breadth-first search algorithm – the nodes can be moved to a different queue under some conditions.

-
child– the nodes from fieldnextare placed in this queue. -
pure– thelaunchfunction will add a node/nodes to this queue. -
barrierandsampler– two queues where the nodes with stepbarrierare placed. -
effect– a queue where the nodes with steprunare placed.
Queues have different priorities. In each iteration of the computation cycle, the kernel gets a node to process from the queue, depending on priority. So, top priority queue child is emptied first, and least priority queue effect is emptied last. Thus, the side-effects are always executed after pure computations.
Why do we even need different queues and priorities? Let's have a look at a common problem called the diamond dependency problem.

Another name for this problem is the glitches problem.
A glitch – is a temporary inconsistency in the observable state.
In essence, the problem is when there are many stores connected in a complex way, and a single update of one store can cause multiple updates of another store. Stores are frequently used in views, and fast multiple updates of one store cause useless view re-renders, and this looks like glitches, hence the name.
Here is a simple analogy with the Redux world: why do we even need to use memoized selectors? Because if we don't use them, any store update will cause the update of all the components, even if their data (part of the store) has not been updated.
Another example is from Rx world:
--a------b------c------d--------e--------
--1-------------2---------------3--------
combineLatest
--a1-----b1-----(c1c2)-d2-------(e2e3)---
The events in parentheses happen "simultaneously". In practice, they happen at slightly different time periods separated only by a couple of nanoseconds. That's why people consider them to be simultaneous. Events (c1c2) are called glitches and sometimes thought to be a problem because one usually expects only c2 to happen.
So, what does Effector do to avoid this problem? This is one of the reasons why barriers and different priority queues exist.
Here is an example code:
const setName = createEvent()
const fullName = createStore('')
.on(setName, (_, name) => name)
const firstName = fullName.map(
first => first.split(' ')[0] || ''
)
const lastName = fullName.map(
last => last.split(' ')[1] || ''
)
const reverseName = combine(
firstName,
lastName,
(first, last) => `${last} ${first}`
)
reverseName.watch(
name => console.log('reversed name:', name)
)
setName('Victor Didenko')
- Event
setNameaccepts the full name - The full name is set to store
fullName - Two derived stores
firstNameandlastNameare set automatically to the first and last name (the map function divides the full name with a space) - The combined store
reverseNamedepends on storesfirstNameandlastNameand joins their values in reverse order
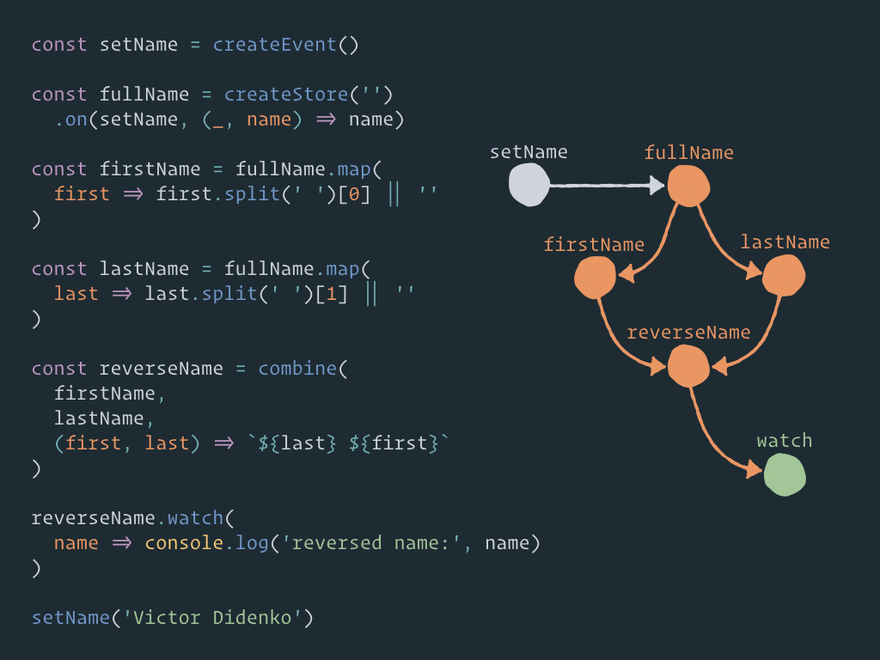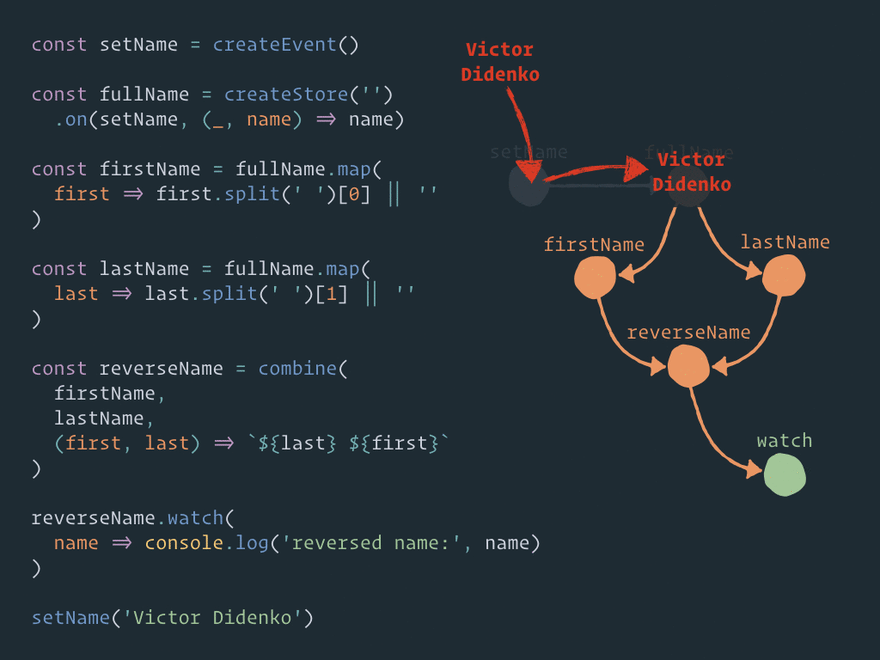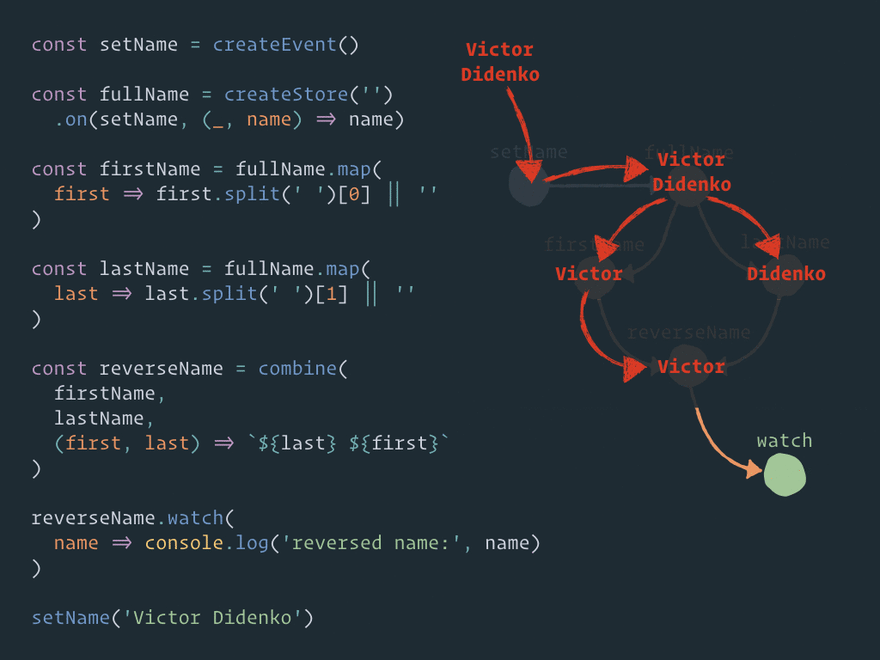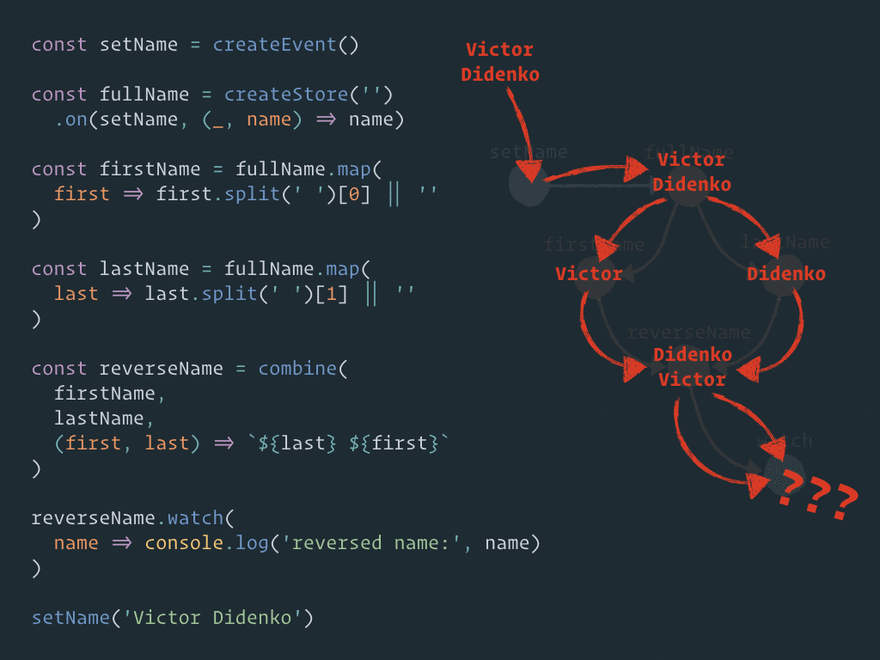
Here is a question: will store reverseName be updated once (correctly) or twice (glitch)?
If you've checked the REPL, you already know the right answer. The store will be updated only once. But how does this happen?
Let's unfold this logical graph of relationships into a structural graph of Effector nodes:
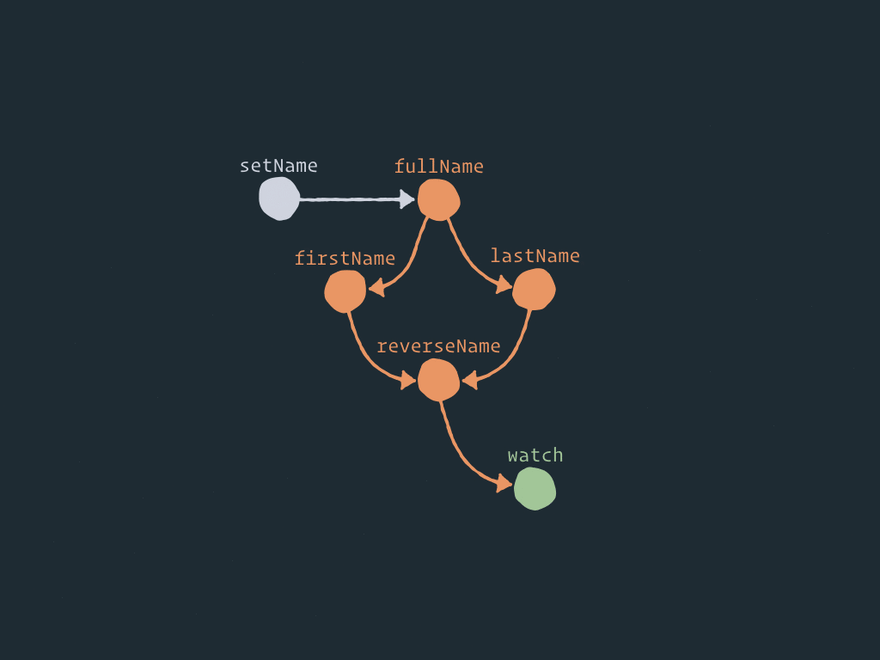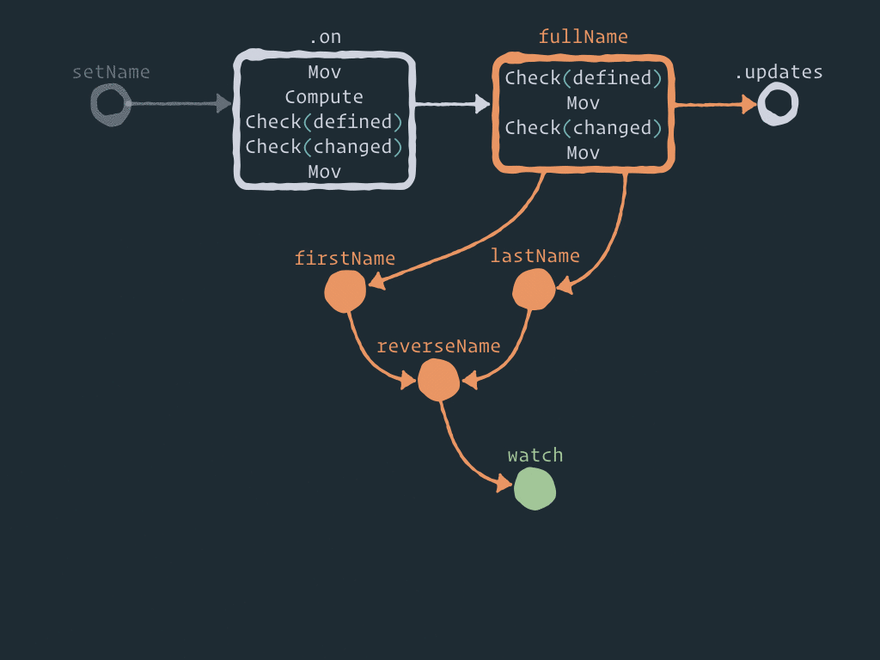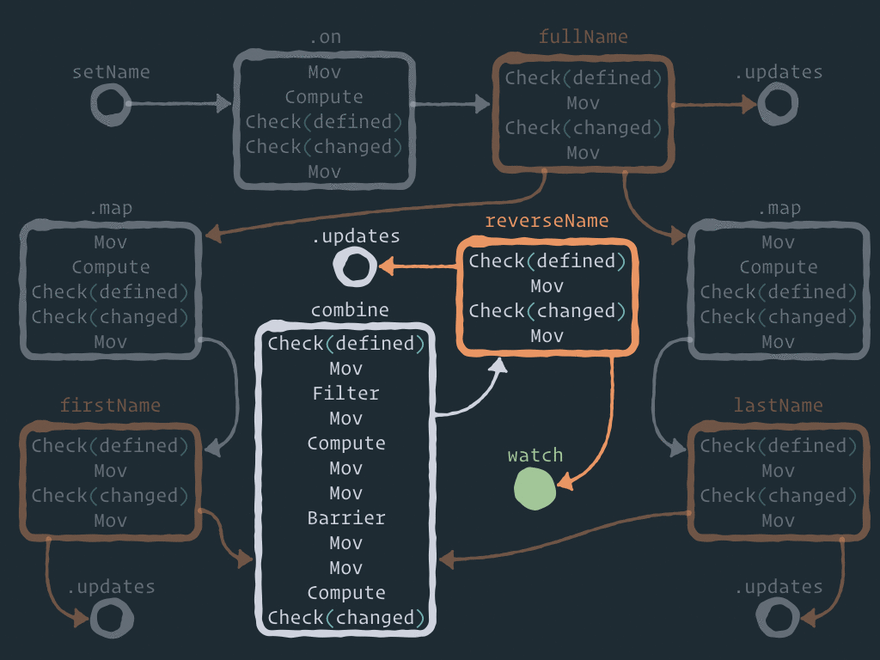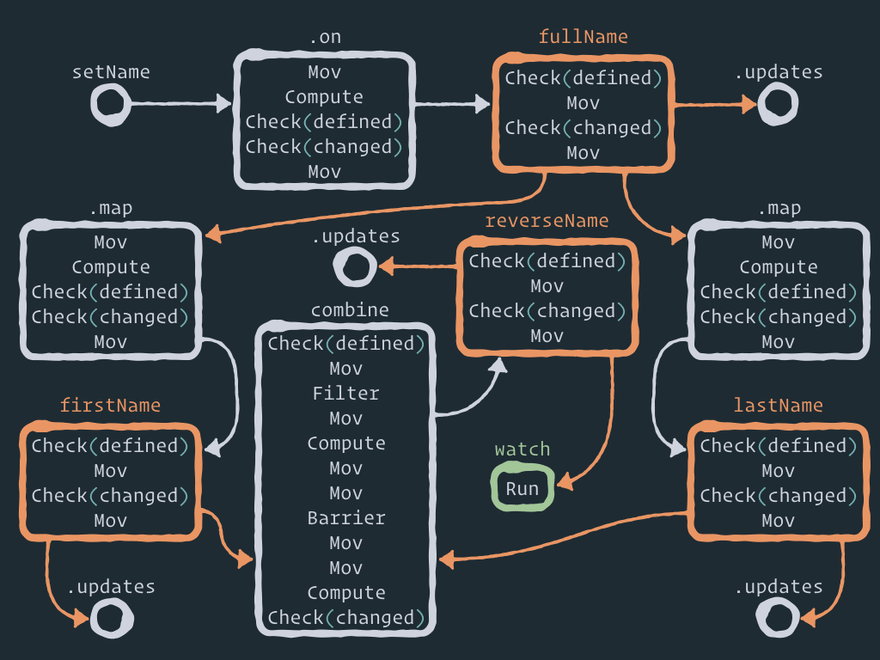
Here is a full static view of the Effector graph:
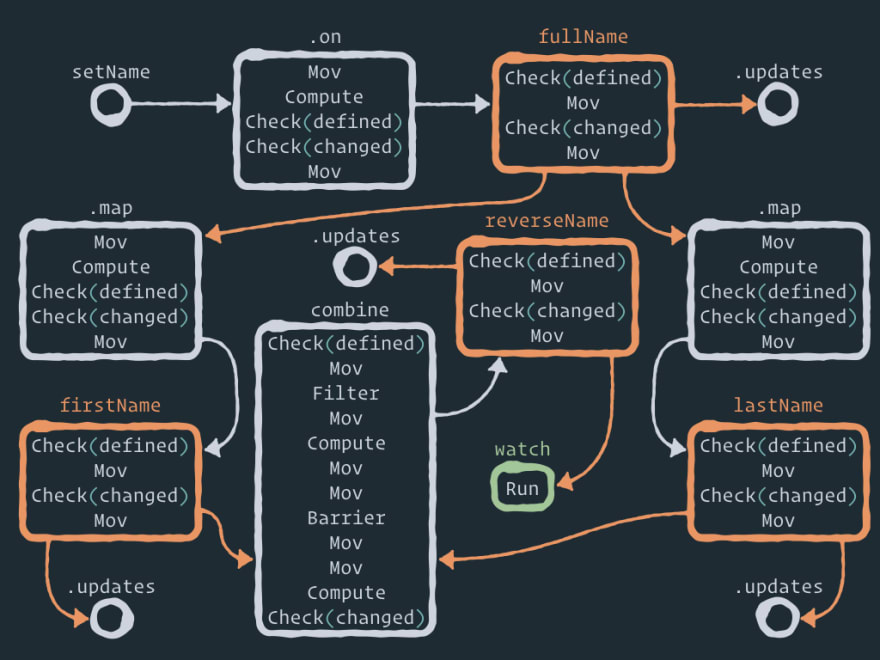
Here you can see a few auxiliary nodes like .on between the event and the store, .map between the store and the derived store, and combine between the stores and the combined store. And that is where the beauty of Effector lies, in my opinion. You can perform any operation between entities/nodes by adding one or more auxiliary nodes with some logic. For example, forward just adds one node between two nodes. .watch only adds one new node. .on adds one auxiliary node between the event and the store. And if you want to perform operation .off, you just remove this intermediate node! Fascinating, isn't it?
The edges in this computation graph are drawn only by the links in field next. I didn't draw the ownership graphs, nor the graphs of links to the stores.
I will not explain each step in this graph (moreover, the implementation can be changed), but I want you to pay attention to a few things:
- When you use API
store.on(event, reduce)– the reduce function is executed inside intermediate node.onby the second stepcompute. - The current store value is copied to the intermediate node by the first step
mov. - Intermediate nodes
.maplook exactly like node.on– in other words, this literally means that the derived store subscribes to the updates of the parent store. Just like the store subscribes to the event. There is one difference though – the map function gets a new value (from the parent store) as the first argument, as opposed to the reduce function, which gets a new value (from the event) as the second argument, and the current store value as the first one. - Any store has
check.definedas the first step, so it is impossible to set anundefinedvalue to the store. - Also there is a step
check.changedin each store, so if the store value has not been changed by the new data, there will be no update to the next nodes in the graph.
And I'd like to describe step barrier in node combine in more detail. Here is the animation of solving the diamond problem:

What is going on, step by step:
- At some point, we have two nodes in the child queue –
firstNameandlastName. - The kernel gets
firstNameand executes the node steps. Then it adds nodecombineto thechildqueue. Node.updatesis also added, but it's a trivial process, so I'll ignore it here. - The kernel gets the next node
lastNameand executes the node steps. Then it also adds nodecombine(the same node) to thechildqueue. So, now we have two links to the same node in the queue. - The kernel gets node
combineand executes the node steps until it meets stepbarrier. - When the kernel meets step
barrier, it pauses the node execution and places this node to thebarrierqueue. The kernel also saves the barrier ID and the step index where the execution was paused. - Then the kernel gets node
combine(the same node) from thechildqueue (because thechildqueue has higher priority than thebarrierqueue) and executes the node steps until it meets stepbarrier. - When the kernel meets step
barrier, it pauses the node execution, but now it knows that there already is one postponed node in thebarrierqueue with the same barrier ID. So, instead of placing this node to thebarrierqueue again, the execution of this branch just stops here. - Please note that the execution stop is not throwing all computation results away. Node
combinesaves both thefirstNamevalue and thelastNamevalue for this moment. - Now the
childqueue is empty, so the kernel gets nodecombinefrom thebarrierqueue and continues the execution from the step where it was paused. - Thus, only one execution branch of two gets through step
barrier. So, this is how the diamond problem is solved. StorereverseNamewill get only one update. - If you are interested, the combine function is executed in step
computeafter stepbarrier– both values already exist here.
In Effector telegram chat, I saw a beautiful comparison of the computation cycle with lightning: calculations branch, diverge, converge, get cut and so on, but all these are parts of one single discharge.

And returning to the very beginning, why do you need to know the Effector internals?

If you search through the Effector documentation, you will not find any mention of the graphs (except for the Prior Art section). That is because you don't need to know the internal implementation to use Effector effectively. Sorry for the tautology. Your decision to choose one tool over another should be motivated by the task this tool aims to solve, and not by the tool's internal implementation. Effector solves any state manager problems like a boss, by the way ;)
But! There are always buts :)
Knowing what is going on under the hood, you can clean up the mess in your head if you do have it as I did. Imagine the whole picture, solve the puzzle, and build that racing car out of a pile of scattered pieces.
By the way, if you have some irrational fear of the word "graph", I can show you a mental lifehack for that:

You see the word "graph", you hear the word "network".
I'm serious, it is the same thing. But historically the term "network" is more widespread among engineers, not mathematicians.
This knowledge also gives you a bonus: you can create your own entities with your own logic that will work alongside with native Effector entities :)
I won't show you anything complex, but just a simple example: node future (I also call it a "porter"). It accepts any data and passes it further to the graph if it is not Promise. But if it is, the node holds it until Promise is resolved.
function createFuture () {
const future = createEvent()
future.graphite.seq.push(
step.filter({
fn(payload) {
const isPromise = payload instanceof Promise
if (isPromise) {
payload
.then(result => launch(future, { result }))
.catch(error => launch(future, { error }))
}
return !isPromise
}
})
)
return future
}
const future = createFuture()
future.watch(_ => console.log('future:', _))
future(1)
future(new Promise(resolve => setTimeout(resolve, 100, 2)))
future(Promise.resolve(3))
future(Promise.reject(4))
future(5)
As you see, I took an ordinary event and modified its seq field, i.e. added one step filter. It is possible to create an entity with a node from scratch, but in that case, you should also think about implementing useful methods like .watch, .map, .prepend and so on. The event has them by default, so why not use them :)
The above code will print the following:
future: 1
future: 5
future: {result: 3}
future: {error: 4}
future: {result: 2}
And to finish, I'd like to put here an out-of-context quote by Linus Torvalds:
Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
So, think about your tools.
Worry about data structures.
Thank you.
Posted on March 19, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related