
Jonathan Johnson
Posted on April 27, 2021
When I last left off, I had reached a significant milestone for PliantDb: I had just released the first version of the client-server functionality. Today, I wanted to recap what I've done in the last two weeks, but more importantly, start painting a picture of where this project is going in my head. If you thought the goals in the project's README were already lofty, you're in for a journey today.
What's new in PliantDb 0.1.0-dev.3
PubSub
PliantDb now offers PubSub:
let subscriber = db.create_subscriber().await?;
// Subscribe for messages sent to the topic "ping"
subscriber.subscribe_to("ping").await?;
db.publish("ping", &1_u32).await?;
println!("Got ping message: {:?}", subscriber.receiver().recv_async().await?);
Key-Value Store
I don't want any compromise on the ACID compliance of transactions in collections, yet that comes at a significant performance cost. Sometimes, you'd rather sacrifice data safety for high-performance. The Key-Value store aims to provide redis-like speed and functionality to PliantDb. The current API is limited to basic set/get/delete key operations, but it supports enough atomic operations to enable using the key-value store as a synchronized lock provider. For example, executing this operation on multiple clients will result in only one client executing the isolated code:
match db.set_key("lock-name", &my_process_id).only_if_vacant().expire_in(Duration::from_millis(100)).await? {
KeyStatus::Inserted => {
// Run the isolated code
}
_ => {
println!("Other client acquired the lock.");
}
}
Improving the onboarding experience
From the start of this project, I've enforced public APIs to have documentation. I've also tried to create reasonably simple examples of the basic functionality of PliantDb. However, for a project like this, there's a lot of use-case-specific topics that need to be covered. I decided there needed to be a book. It's still very early in progress, but it seems perfect to share at this stage of the project: pliantdb.dev/guide.
At this stage, I wouldn't want anyone to use PliantDb in a real project yet. I think the storage mechanisms themselves are reliable and can be trusted, but I can't guarantee that the storage format will be stable between versions. Because of this harsh anti-recommendation, the guide is at a good stage for people interested in the project: it covers some high-level concepts. It also begins to explore some of the concepts I'm going to discuss here later on -- writing those sections were an inspiration for this post.
I want the user guide to have sections for topics that cover the knowledge someone needs to possess to feel confident in being their own database administrator. It sounds daunting, but the goal of PliantDb is to make being a responsible database administrator as easy as it can be.
Keeping PliantDb Modular
While having many feature flags can be daunting, I think I've come up with a good approach to the feature flags in the "omnibus" crate. If you're just getting a project up and running, full can be used to bring in everything. If you want to pick and choose, you can now enable each of these features independently:
- PubSub
- Key-Value store
- WebSockets
- trust-dns based DNS resolution on the client
- Command-Line structures/binary
Furthermore, realize that this is a core goal of mine: While this is a reasonably large project, you will be able to pick and choose what you need in your database. Some functionality will need to be integrated to work optimally, but as much as possible will be kept modular.
Fun fact: there are currently 18 build jobs processed in CI to ensure each of the various valid feature flag combinations compile and pass unit tests.
Redefining the Onion
The design of PliantDb is meant to be layered, kind of like an onion. The pliantdb-core is the core of the proverbial onion, and the first layer around it is pliantdb-local. Before today, here's how I described the layers:
-
local: Single-database storage mechanism, comparable to SQLite -
server: Multi-database networked server, comparable to CouchDB.
In discussing the plans I'm about to unveil to you, I realized I went too far in mimicking CouchDB's design. I decided to implement the multi-database abstraction as a server-type operation -- the server doesn't really care about the databases. It just organizes multiple databases together. But, CouchDB is only accessible via HTTP, unlike PliantDb. In PliantDb, your code can run in the same executable as the database.
Because of this, a very valid use case is a completely offline multi-database storage mechanism. Suppose you are running a single-machine setup and aren't needing any other access to the database. In that case, you should be able to utilize all of PliantDb's features that make sense: multiple databases, key-value store, PubSub, and more to come. This realization had me commit a massive refactoring defining the layers as:
-
local: TheStoragetype provides multi-database management, and theDatabasetype provides access to a single database. -
server: TheServertype uses aStorageinstance internally and allows accessing it over a network.
As a testament to this being the correct design decision, I was able to remove many internal APIs that were needed to support the Server before. While it was a painstaking process, I'm pleased with the outcome.
Fixed backup/restore
As part of the previous pull request, there was an update to the backup process. The bug wasn't related to the safety of the data but rather that I wasn't saving the executed transaction metadata. At the time, that was a design decision, but I didn't test well enough. It wasn't until the multi-database implementation utilized a view query under the hood that an expect() failed in the view indexer: the view indexer thought it was entirely reasonable to expect: if there were documents, there must be a transaction id.
As I thought about my original decision, I realized I was deeply mistaken. Not saving the transaction information breaks the ability for a restored database to keep replication history. So, now that I've updated backup/restore to work for multi-database (another side-effect of this design decision) and included transaction information, here's what it looks like:
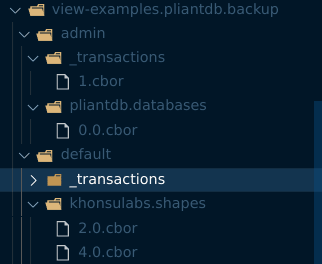
The top-level directories, admin and default, are the two databases in this example exported. The admin database is the internal database used to track the databases that have been created. default is the default name of a database, if it was created for you automatically during Database::open_local.
Inside of each database folder is a _transactions folder. Each file is a single Executed transaction.
All of the remaining folders will be Collections of documents. Each file is named using the document ID and the revision number. The contents of the file are the exact bytes that were stored in the document, which usually means it's encoded as CBOR. But, you can manage the document bytes directly if you desire.
What's the end goal of PliantDb?
As odd as it may sound, I'm writing PliantDb to power a game I'm writing. As I mentioned in my last post, the game currently is using PostgreSQL and Redis, and the changes above were all inspired by thinking about what I need to be able to update Cosmic Verge to use PliantDb instead of those two engines.
Once I finished the key-value store, I found myself ready to start on that task! But, as I started trying to figure out where to begin the refactoring, I realized I had been having grandiose visions of PliantDb that I thought were unrelated to Cosmic Verge... Only, they were starting to seem relevant now that I thought about it more.
I'm going to start with the conclusion: PliantDb's ultimate form is a platform to help you build a modern Rust-y app. For Cosmic Verge, it will be what game clients connect to over the internet, and it's what our internal API will be powered by. To support this safely, a robust permissions model will be needed. But, rest assured, if all you want is a local database with minimal features, you'll be able to get just that and no more.
To begin to understand why this is the logical conclusion of multiple days of conversations on Discord, we must first start thinking about the goals of the Cosmic Verge architecture we're going for:
- We want to have a large number of "locations" with independent sets of data and regular-interval game loops.
- We want to have a cluster that can scale up and down as needed to meet demand. This means dynamically moving locations between servers as load is increasing.
- We want to have every location be configured in a highly-available setup. If one server fails, clients should barely notice a hiccup (the only hiccup being if they dropped their connection).
- Every server will have PliantDb data on it, but we want custom logic driving placement of data/tasks within the cluster. We want to be able to use metrics to balance load intelligently.
Because of these basic facts, we concluded that every Cosmic Verge server was going to be a part of the PliantDb cluster. And, if each server was going to be connected via PliantDb, could we improve upon PliantDb's solution to solving our networking problems by implementing a separate protocol? In the end, we decided we couldn't. But more importantly, as we reviewed the features needed by Cosmic Verge to achieve clustering and the features required by PliantDb, we realized the overlap was too significant to ignore.
Why is this better than using some other database cluster? It boils down to how PliantDb works in the server's executable. Each instance of the Cosmic Verge server will open a PliantDb server in cluster mode. When the server's code calls into the cluster, it will know what servers contain the data in question. For a PubSub message, for example, it knows precisely which servers have any subscribers listening to the topic of the message being published. Because of this knowledge, a PubSub message sent through the PliantDb cluster will be a direct message between two servers in the same cluster. The same knowledge also works for all database operations. If you need a quorum write to succeed, and you're one of the three servers in that particular database shard's cluster, only two network requests are sent. Or, if you ask for a cached view result, your local server instance will return the data without making a network request if it can.
But, what about the actual game API? How is PliantDb going to help with that? Let me introduce a project that I haven't updated in a little while: basws. This is the project that Cosmic Verge currently is built on. The main idea is to build a simple way to create API servers, abstracting the authentication/re-authentication logic as much as possible. As I started envisioning how I would integrate PliantDb with it, I started realizing that I wanted PliantDb to have some of this functionality. It wouldn't be hard to add this exact functionality into PliantDb and give it direct support for the Users and Permissions models. A clear win for Cosmic Verge, but hopefully for a lot of developers.
What's next?
I have my hopes on demoing a native-client version of Cosmic Verge at next month's Rust Game Dev Meetup powered by PliantDb, but to do that I need a few more things:
- Permissions: I don't want to allow people to connect to a PliantDb server that has no concept of permissions.
- basws-like API layer: This layer will be defined as a trait that you will be able to optionally provide on the
Serverand (eventually)Clustertypes. - Users if I want to support logging in, although for the demo I might simply give each player a unique random color.
The next meetup is on May 8. I'm hopeful, but there's a lot of work to do. And, I keep finding myself writing very long blog posts!
As always, thank you for reading. I hope you're interested in PliantDb. If you'd like to join the development conversations, join our discord.
Posted on April 27, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.