A Docker Free Intro to Containers (Write Your Own Containers and Images)

Deepak Ahuja 👨💻
Posted on May 24, 2020

Containers are collection of Operating System technologies that allows you to run a process. Containers are themselves a very old technology, but after introduction of Docker and the software system they built to create, deploy and ship containers, it has made containers to be opted widely. We will look at atomic units needed to build a container without docker so that you can get past the definitions like "light weight VM", "something to do with docker", "poor man's virtualization".
So what technologies do we need to create our own containers?
Well, let's first look at what an OS does for us essentially. An OS runs processes, an entity which represents the basic unit of work to be implemented in the system. There is a Process Control Block which is a table maintained by OS in which it identifies each process with the help of a special number known as PID (process ID). It also has status of process along with privileges, memory information, environment variables, path, child processes etc. Every process has a certain root directory in which process executes. You can actually find this information in a folder called /proc in the file system or by running a command:
ps aux
Here's what it looks like in my machine:
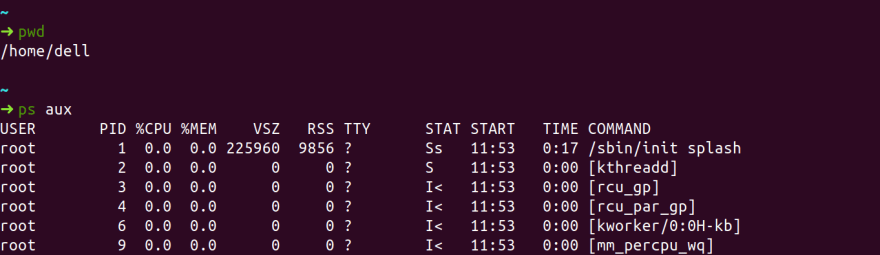
There's a lot more to each of this, but we're gonna stay focused on high level overview of Linux systems.
Now if we are able to create a process and isolate it such that it run somewhere else too without installing the whole operating system, we can call it a container. To isolate this process, i.e. make it impossible for it to look outside it's own folder, we need to "jail" it. We can do it using the following command:
chroot /path/to/new/root command
It will change the root folder for this process and it's children, hence the process will not be able to access anything outside this folder. let's follow some steps as super user:
mkdir my-new-root
chroot my-new-root bash
Here we have created a new folder and then using chroot command to “change the root” and run command bash in it.
You should see some error like bash is not found or command not recognized. Refer following screenshot:

Since command bash is running inside my-new-root and it cannot access anything outside it's new root, it is unable to find program that runs the bash shell.
To fix this, use ‘ldd’.
ldd prints the shared other objects required by an program to run.
ldd /bin/bash
This command outputs dependencies for a certain program needed to run:
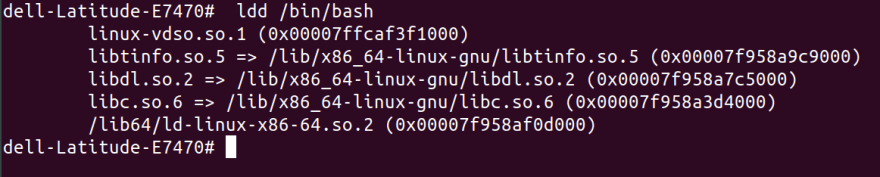
let's copy these in their respective folders inside my-new-root.
mkdir my-new-root/{bin,lib64,lib}
cp /bin/bash my-new-root/bin
cp /lib/x86_64-linux-gnu/libtinfo.so.5 /lib/x86_64-linux-gnu/libdl.so.2 /lib/x86_64-linux-gnu/libc.so.6 my-new-root/lib
cp /lib64/ld-linux-x86-64.so.2 my-new-root/lib64
Here we have created 3 folders in which shared libraries that are required by bash reside (under lib and lib64). Then we are copying those objects into them.
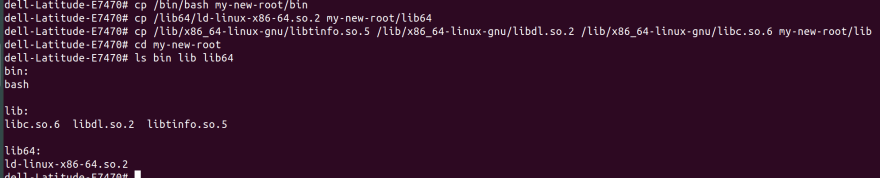
Now if we run chroot my-new-root bash it will open up a bash shell inside my-new-root. You can verify it by pwd it should output /
Why don't you try enabling
lscommand in this too?
Even though our new root cannot access files outside, it can see still running processes on host container. This won't work for us if we want to run multiple containers on the same host. To achieve true isolation, we also need to hide the processes from other processes. If it’s not done then one container can kill PID of process, unmount a filesystem or change network setting for other containers. Each process lie in one of 7 namespaces defined in UNIX world. We can use a command called unshare to see those:
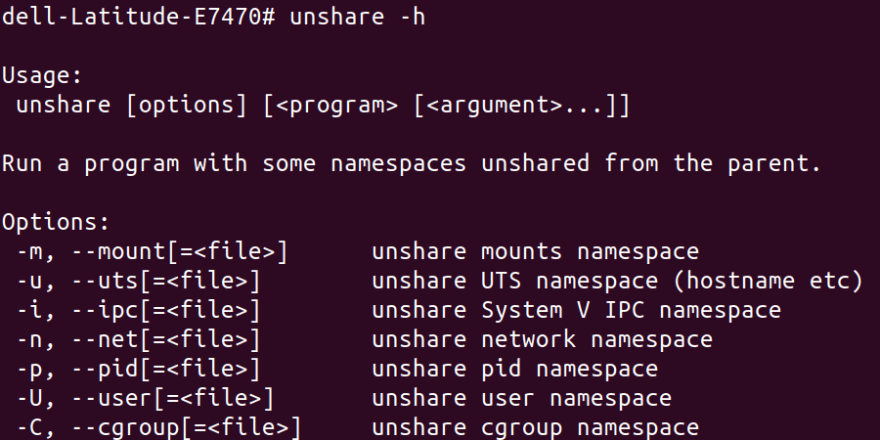
We can see the important 7 namespaces above. We can use unshare command to restrict those namespaces.
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot my-new-root bash
Now our new root has restricted access to processes from any of these namespaces. They can now get duplicate PID too! That's true isolation.
One last thing left, namespace don't help us limit physical resources like memory limits. For them we have cgroups, which essentially is a file in which we can collect PIDs and define limits for cpu, memory or network bandwidth. The reason it is important because one container can starve the resources (like by fork bomb attack) of host environment for use by other containers.
Note: Windows operating systems are not vulnerable to a traditional fork bomb attack, as they are unable to fork other processes.
Here's how we'd do it (Don't worry about commands, we're just learning things that containers are made from)
# outside of unshare'd environment get the tools we'll need here
apt-get install -y cgroup-tools htop
# create new cgroups
cgcreate -g cpu,memory,blkio,devices,freezer:/sandbox
# add our unshare'd env to our cgroup
ps aux # grab the bash PID that's right after the unshare one
cgclassify -g cpu,memory,blkio,devices,freezer:sandbox <PID>
# Set a limit of 80M
cgset -r memory.limit_in_bytes=80M sandbox
You can learn more about cgroups here
That's it! Now we have created our own container.
Let's create images without docker
Images
Images are essentially the premade containers packages as a file object.
We can use the following command to package this container as a compressed file:
tar cvf dockercontainer.tar my-new-root
Now we can ship it somewhere else and we would create a folder to decompress it:
# make container-root directory, export contents of container into it
mkdir container-root
tar xf dockercontainer.tar -C container-root/
# make a contained user, mount in name spaces
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot $PWD/container-root ash # change root to it
# mount needed things
# change cgroup settings
# etc
That's it? Means we can go around and use containers like this. Not really, docker does a lot more than this for you. It provides us an awesome registry of pre baked images, networking, import, export, running, tag, list, kill these images etc.
Benefits of Docker Containers
- Runtime: docker engine allows us to use different packages compiled and run same across various OS. It's runtime provides good workflow benefits too
- Images: Great portability, image registry, image diffs
- Automation: Your containers can flow through local computer to jenkins all with a file which contains config. It also enables caching and multi stage builds for containers. Hence image builds are very fast
An example of above process written in go programming language can be found here and it's accompanying video.
We'll look at all of this in coming posts. Thank you for making it to end of the post.

Please share it if helped you learn something new. You can drop me a hello on twitter. Take care :)
Posted on May 24, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related