Lessons learned about building microservices and reactive systems

Dina Bogdan
Posted on July 20, 2020
I think that this will be the first blog post from a series in which my purpose is to share with you my experience when working with distributed systems.
For some time microservices are the most used architectural style and also the point that every software engineer wants to reach. During time microservices have undergone some changes and in this way, we have reached out at concepts such as miniservices, self-contained systems or reactive microservices and, reactive microsystems as defined by Jonas Bonér.
My point of view is that all these concepts share some fundamental to-be followed ideas, let’s called them patterns, and those are really important when building modern distributed systems. For me, personally, there is not about microservices or miniservices or other buzzy terminology, but about building responsive, scalable, and fault-tolerant distributed systems.
In the rest of this article, I will enumerate all the patterns that I’ve used when building modern distributed systems, briefly explaining them. In the following articles I will try to explain each of them more in-depth, so don’t be troubled if you will not find enough arguments regarding a specific pattern here, instead leave a comment with your questions so I can answer them in the future.
The need for microservices
The most natural thing that we should do is to think. Let’s think why an architectural style such as microservices appeared. Well… the answer is: because of monoliths! But not all monoliths are bad and when building software we should start building a monolith first. To be more precise, microservices appeared because of the not-proper evolved monolith, called “big ball of mud”.
But evolving our old application services from inside the monolith into some standalone software components that are integrated via the network using synchronous RPC APIs is not enough. In fact, doing this will lead us to the “distributed big ball of mud”, which is worse than the big ball of mud.
If you are not in total agreement with me it’s fine, we can have different points of view, but let’s look a little at InfoQ’s architecture and design trends 2019 Q1 Graph.
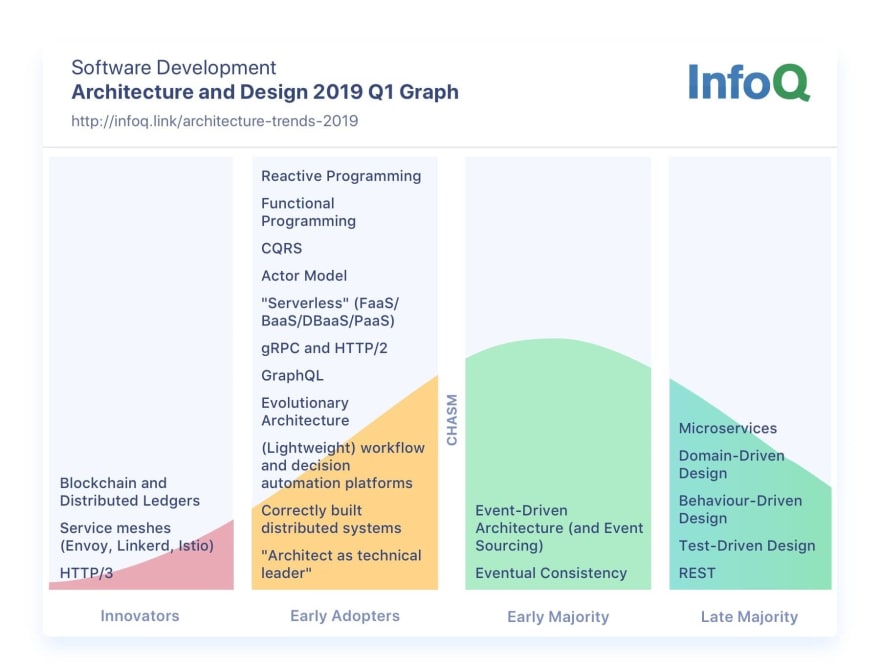
We can see that microservices are placed in the Late Majority column along with the Domain-Driven Design (which is a software methodology that enables us the build microservices in a successful way).
Now, it’s pretty clear that at the beginning of 2019 almost everybody heard about microservices and worked on a microservices architecture… But (!), Let’s have a look at how things evolved! For being as impartial as possible we will look at the next InfoQ’s trends report, which is Architecture and Design trends 2020 Q2 Graph.
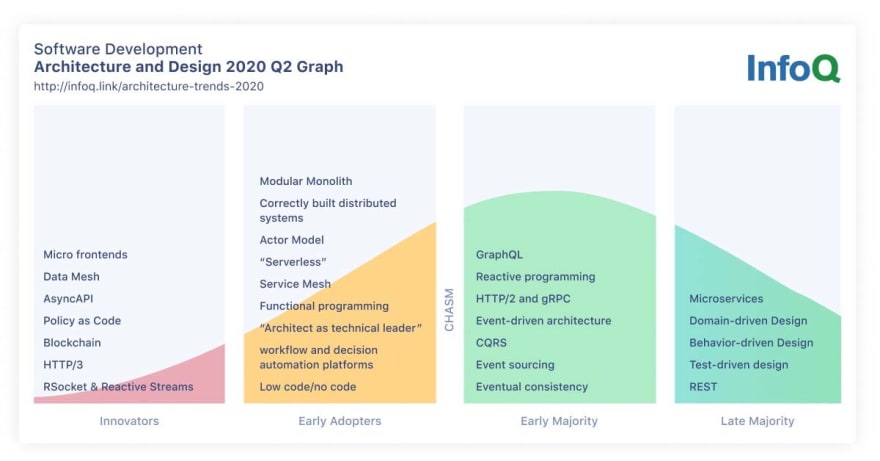
In this report, Microservices are still in the Late Majority column, but what is very interesting is that in the Early Adopters column there are two specific trends: Modular Monolith and Correctly built distributed systems. Why ever someone should adopt building a monolith when having microservices as the majority’s choice? Because microservices, at least their initial incarnation, were not as good as expected. Also, the “Correctly built distributed systems” trend is something that should make us think about what is the correct way to build a distributed system nowadays.
Monoliths vs microservices?
There are tons of books, articles, and blog posts that are comparing monoliths with microservices. The fundamental difference between monoliths and microservices was presented by Martin Fowler. He says that “a monolithic application puts all its functionality into a single process and scales by replicating the monolith on multiple servers”, whilst “a microservices architecture puts each element of functionality into a separate service and scales by distributing these services across servers, replicating as needed”.
I will not dig more into explaining the differences between monoliths and microservices, because Martin Fowler did a very good job with his explicit comparison.
The impact of the Reactive Manifesto
At the beginning of this article, I’ve said that as a software engineer I want to develop responsive, scalable, and fault-tolerant distributed systems. Basically these three properties of distributed systems are included in the so-called Reactive Manifesto along with the message-driven concept.
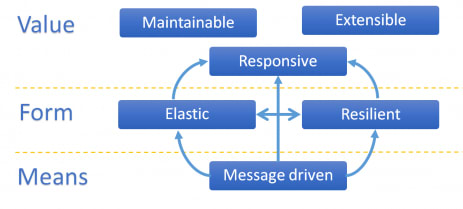
Reactive Manifesto was published on 16 September 2014 and is still producing a great impact over rethinking old distributed systems and designing new software. It helps a lot with correctly building distributed systems.
Principles of good design in a microservices or reactive world
As I’ve said in the very beginning, I want to present some of the principles that I’ve found useful when designing distributed systems. Some of them are:
- asynchronicity
- autonomy
- bulkheading
- single responsibility principle
- stateless
- distribution transparency
- past nature of information
- eventual consistency
- distributed tracing
- monitoring and observability
Embrace asynchronicity
First of all, let’s think about why should we choose asynchronicity instead of synchronous method invocations. Well… there are some arguments for this:
we will gain a loosely coupled architecture because the microservices can be integrated via message brokers (which are asynchronous by nature) that can enable us to evolve independently our components;
asynchronicity will enable concurrency in time which will allow better usage of the resources. Basically multiple requests can be performed at the same time using the same resources, which will improve the total responsiveness of the system;
mobility and distribution in space will be another advantage provided by asynchronous calls. In this way, it’s possible to move services from one data center to another or to have downtime periods in mid-day.
Using an asynchronous model instead of synchronous one will improve the responsiveness and the elasticity of the system.
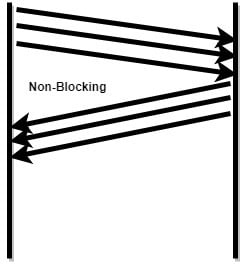
When using synchronous requests, each request blocks some resources (eg: threads) until a response is received.

Asynchronous invocations allow for non-blocking interactions between components. In this way, all resources are used more efficiently, because when a request is performed the resources are released immediately so more requests can be made.
Microservices that act autonomously
When working on a microservices-based architecture a very important characteristic that provides a successful story is the autonomy of microservices.
When thinking about how microservices can gain autonomy should consider the following aspects:
- the isolation level between them;
- the capacity to act independently in doing business tasks;
- the capacity to fail independently without propagating the failure from one microservice to others;
- the collaboration level between microservices in performing a complex business process.
Martin Fowler did a very good job surprising in a visual way the differences from autonomy perspective between monoliths and microservices, so I will use also an image like the one used by him for representing these differences.
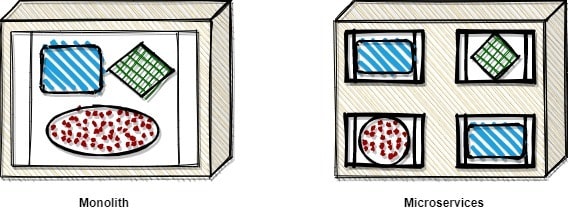
We can see that in the case of the monolith, multiple software constructions are deployed as a single deployment unit, so basically there is no isolation between them. Components are not acting autonomously and it is very probable that if one fails, the rest of the others will also fail.
When using microservices, those are deployed as individual deployment units which are isolated one of each other. All components are working autonomously and if one of them will fail, probably the rest of the other will still be working.
Bulkheading microservices
Bulkheading is a useful pattern that should be used in both cases when working on a monolith or on a microservices-based architecture.
The idea is that elements of an application should be isolated into separate pools so that if one fails, the others will continue to function.
The concept was named like this because it resembles the sectioned partitions of a ship’s hull. If the hull of a ship is compromised, only the damaged section fills with water which prevents the ship from sinking.
In Akka, which is one of the best toolkits for developing reactive microservices, bulkheading is implemented under the hood via something called dispatchers and can be configured by the user.

A microservice asks: What is my responsibility ?!
The answer is that a microservices must have a single responsibility! When designing a microservices-based architecture we should think at single-responsibility principle scaled from code construction level up to the architecture component level.
Designing microservices with SRP in mind will lead us to achieve a better decoupling between them and also a higher autonomy degree of each of them.
Just take care of your own state!!!
A microservice takes responsibility for its own state. It needs to be treated as a single unit that includes and executes specific behavior based on the owned state.
When designing reactive microservices you should think about principles like:
Law of Demeter is another principle such as SRP that comes from design guidelines for building object-oriented software programs. What this principle says is that in a piece of code such as a class we should avoid using an internal method or an object which is an attribute of that class as an intermediary point to access a third object’s state.
We should scale this principle from the program construction level up to the architecture design level. We can find below a visual representation of this concept.

The other mentioned concept: Tell, don’t ask is like SRP or Law of Demeter an object-oriented programming design principle that it was found useful at designing autonomous software components such as microservices.
The idea behind it is that a microservice should avoid asking about the state of another microservice and then executing its specific business logic. A better approach would be that each microservice performs its task and at the end to tell the others that its job is done and what must be done next. This will lead us to send commands and emitting events between microservices.
These two principles will increase the entire responsiveness of our system based on increased autonomy achieved by each component. Also, we will gain a better decoupling between microservices which will allow us to benefit from a more resilient system.
Distribution transparency
When designing distributed systems, distribution transparency is a fundamental property of them. There are more degrees of transparency detailed by Andrew Tanenbaum in his fundamental Distributed Systems book.
When working on a microservices-based architecture, what is fundamental to be achieved is the capacity of a microservice to be moved around without being unaddressable. Basically, our microservices must be mobile and still be addressable at the same known addresses.
This property is called Location Transparency and is one of the seven transparency degrees included by the distribution transparency concept.
“Information is always from the past” — Jonas Bonér
In his blogpost “bla bla microservices bla bla” from which I’ve inspired a lot when designing microservices, Jonas Bonér states that “information is always from the past” which means that we should think in terms of past events that contain pieces of information, instead of querying for “current” data.
When querying for data in a distributed system there are few or no guarantees that the received result is its most recent value. Instead of doing this, we should embrace concepts like command and event.
A component should perform some business logic after receiving a command (eg: “enrollNewCustomer”) and should react to and emit events (eg: “customerEnrolled”).
By using commands and events microservices can:
- be loosely coupled
- communicate in an asynchronous manner
- be isolated
Microservices as modern distributed systems
Traditional distributed systems are composed of multiple non-deterministic applications, where a single error located into one of those can lead to an inconsistent state of the entire system.
Microservices allows us to build modern distributed systems which have deterministic behavior, gained by logical and physical decoupling between components and also because these are performing specific business tasks in such a way that if a part of a system is affected by an error, then only the associated business process will be impacted, while the others can still be performed.
What about transactions?
How do we manage transactions in a microservices-based architecture?
One of the best methodologies of designing software is Domain-Driven Design (DDD). When applying DDD on a microservices-based architecture we often reach the point when a microservice encapsulates a DDD aggregate. The rule of thumb of aggregates is that a transaction should not involve more than one aggregate, so basically we conclude that a transaction must live only within a single microservice.
We should forget about distributed transactions done by using the two-phase commit protocol (2PC) because of the availability problems imposed by these and also because of the inconsistencies produced by the heuristic decisions.
Of course, for building complex distributed systems, there are scenarios when business processes involve more than a single microservice. How should we manage those situations for avoiding inconsistent states in our system?
One of the most used solutions for managing transactions that involve more than a single microservice is the Saga pattern or long-running business transaction pattern. The basic idea for implementing this pattern suppose to create a pair composed of every transaction with the associated compensating transaction. When an error occurs then we will execute in reverse order all the compensating transactions associated with the transactions executed until that specific point in time.
The following diagram can explain better than me how Saga pattern works.

Async but … I can’t find the trace
In a reactive world with asynchronous communication, you won’t be able to find a trace of your request. The solution to this problem is Distributed Tracing.
Here is a very good talk about distributed tracing delivered by Ben Singelman, co-founder of LightStep and co-creator of OpenTracing.
Am I under observation? Someone should supervise me! I could die in thread.SLEEP()
Very often, traditional distributed systems had a binary state: working or failed, so modern distributed systems like microservices are, should avoid this characteristic.
For avoiding such an undesirable binary state we should use the concepts described above, but also we must actively monitor and observe our microservices.
Google introduced a few years ago a set of concepts called site reliability engineering (SRE) by releasing a book. Some of the practices described in this book are:
- service level indicators (SLIs)
- service level objectives (SLOs)
- service level agreements (SLAs)
- error budget
Monitoring the values of these metrics can allow us to preemptively eliminate all the possible failures and also react to scaling our microservices when needed.
What about recovering from failure?
According to the reactive manifesto, our reactive system should be resilient which means being fault-tolerant and in fact, we should not avoid failures, but we should embrace them and code accordingly in such a way that failures will not totally damage our system.
Resilience is often achieved by replication, isolation, and delegation between microservices.
Sometimes failures in distributed systems are present due to the fact that it is overloaded. In an elastic system, these undesirable scenarios won’t be present, because such a system remains responsive under varying workload. Elasticity can be achieved by good design of our microservices and a high redundancy degree of these.
The hard part comes now …
According to the ideas mentioned above, we have a starting point for creating individual microservices, which are easy to understand and implement. Quoting Jonas Bonér again :) “A microservice is not of much use, they always come as systems”. This means that we should think about how to build systems of microservices and doing this includes hard tasks like:
- coordination, like orchestration vs. choreography
- security of the entire system
- replication
- data consistency
- deployment models
- integration models
Also, in the context of moving to the cloud we should think about covering some of the following characteristics:
- ACID 2.0
- event streaming
- managing state
- deployment strategies
Follow me on twitter !
Posted on July 20, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.