
David💻
Posted on April 1, 2022

Tal vez hayas escuchado el término "ETL" más de una vez o tal vez no lo hayas escuchado nunca. En este blog te explicare que es un ETL y cómo podemos implementarlo de una manera ágil y serverless en AWS.
¿Qué es ETL?
Es el proceso que tiene como objetivo es extraer (Extract) datos de una fuente, estos datos pueden provenir de una base de datos, de un archivo Excel, o de un archivo de texto. Posteriormente se realizará una transformación (Transform) según sea necesario, sea que se requiera aplicar un Golden record o simplemente algún criterio de negocio, para la culminación del proceso se realiza el paso de carga (Load), el cual dependiendo de la necesidad, pueden ser cargados de manera acumulativa significando su almacenamiento y continua transformación a un reporte o repositorio general, durante un lapso de tiempo o caso contrario mantener un grado de granularidad realizando este proceso en pequeños reportes.
¿Qué es AWS Glue?
AWS Glue es un servicio ETL (extracción, transformación y carga) serverless en la nube de AWS. Que facilita a usuarios la preparación de sus datos para posterior análisis. En este artículo, abordaré brevemente los conceptos básicos de AWS Glue y como crear nuestro primer ETL.
Componentes
Data catalog: El catálogo de datos contiene los metadatos y la estructura de los datos de la fuente de información que utilizaremos, se lo puede considerar como una copia de una tabla Dynamo, un archivo en un S3, o una base de datos relacional. Es un repositorio central que almacena metadatos estructurales y operativos para recursos de datos. Para un conjunto de datos determinado, puede almacenar la definición de la tabla y la ubicación física, agregar atributos relevantes para la empresa y realizar un seguimiento de cómo los datos han cambiado con el tiempo.
Database: Es una base que contiene todas las tablas que ha mapeado el clasificador (crawler).
Table: Es una tabla con un esquema especificado al cual se puede realizar consultas.
Crawler and Classifier (Rastreadores): Se utiliza para mapear datos de una o varias fuentes mediante clasificadores integrados o personalizados. Crea o usa tablas de metadatos que están predefinidos en el catálogo de datos. Un rastreador se conecta con un almacén de datos, avanza a través de una lista priorizada de clasificadores para extraer los esquemas de sus datos y otras estadísticas, y rellena el catálogo de datos de Glue con estos metadatos. Los rastreadores pueden ejecutarse de manera periódica para detectar la disponibilidad de nuevos datos, así como cambios en los datos existentes, incluidos cambios en la definición de una tabla. Los rastreadores añaden nuevas tablas, nuevas particiones a tablas existentes y nuevas versiones de las definiciones de tablas de manera automática. Puede personalizar los rastreadores de Glue para que clasifiquen sus propios tipos de archivos.
Job (Trabajos): Es un proceso que lleva la lógica de negocio deseada de forma automatizada que lleva a cabo tareas ETL, utiliza internamente Apache Spark y es compatible con lenguajes como Python o Scala.
Trigger (Disparador): Un trigger o disparador es una lógica que inicia la ejecución de un trabajo ETL bajo demanda o en un momento específico de tiempo.
Creando nuestro primer ETL
Pre-requisitos: Para este ejemplo debemos contar con una tabla en DynamoDB y un archivo csv en un bucket S3.
AWS Glue es compatible de forma nativa con los datos almacenados en Amazon Aurora, Amazon RDS for MySQL, Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon RDS for SQL Server, Amazon Redshift, DynamoDB y Amazon S3, así como también en bases de datos de MySQL, Oracle, Microsoft SQL Server y PostgreSQL en su nube virtual privada (Amazon VPC) en ejecución en Amazon EC2. AWS Glue también es compatible con transmisiones de datos de Amazon MSK, Amazon Kinesis Data Streams y Apache Kafka.
Para este ejemplo utilizaremos una tabla y un archivo que poseerán algunos registros, el propósito será extraer los registros que sean similares y transformarlos a un mismo tipo de dato.
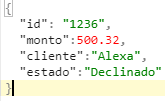
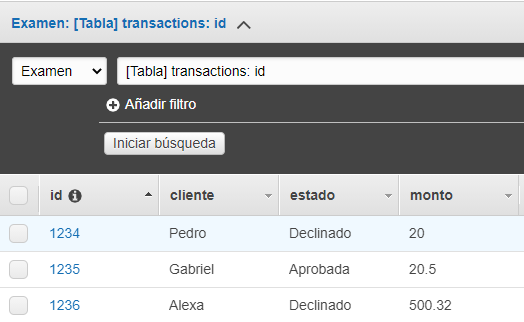
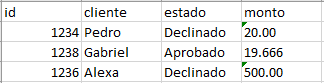
Tanto nuestra tabla como nuestro archivo estará conformado por 4 campos, de los cuales nos interesa verificar si el estado y el monto son los correctos dependiendo del id y del cliente.
Ahora procederemos en la Parte 2 de este tutorial donde crearemos nuestro primer ETL.
Posted on April 1, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related