How to Analyze Prometheus Alertmanager Alerts Using S3, Athena and CloudFormation

Frank Rosner
Posted on July 17, 2022

Introduction
When you operate a global SaaS product, your synchronous alerting channels can be overwhelmed from time to time. Noise notwithstanding, it becomes a real challenge to retroactively analyze issues across a wide range of components and environments.
Our alert analytics solution needs to meet the following goals:
- Analyze alerts across multiple dimensions. During major regional or global outages, it’s challenging to keep up with alerts firing across different systems that are ultimately related to the same issue. When your alerting Slack channel becomes overwhelmed, you need a solution that makes it easy to analyze and correlate these alerts across all your regions and environments. This way, we can easily figure out which customers have been affected by a specific outage.
- Improve alerts. It’s tough to define rules for useful alerts. When monitoring metrics and thresholds, there’s a sweet spot between overly noisy alerts and undetected problems. Analyzing alerts on a global level lets you see the signals that are too sensitive or possibly even false alarms.
- Understand overall system health. Compiling a historic view of all alerts with daily, weekly, or monthly summaries gives an overview of system health that we can share with stakeholders.
Besides these goals, the solution should be scalable and cost-effective, so that we only pay for what we actually use. This is why the solution architecture is based entirely on serverless, pay-as-you-go components. The next section explains the architecture in greater detail.
Architecture
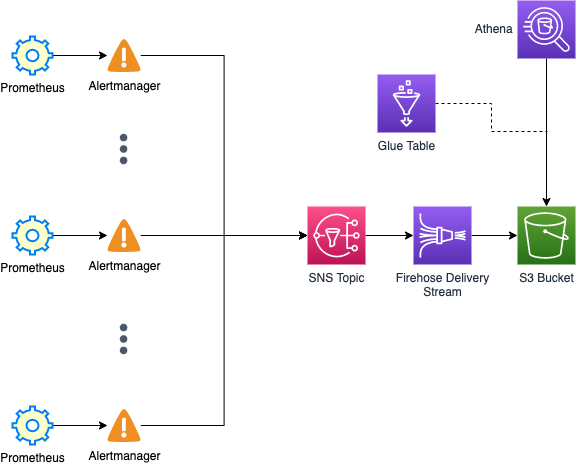
The existing infrastructure contains multiple Prometheus Alertmanager instances, which forward alerts to Slack and PagerDuty already. The goal now is to forward alerts to the new analytics pipeline.
Alerts are sent by Alertmanager instances towards a central SNS topic. In recent versions of Alertmanager, this can be done directly through an SNS receiver, without the need for an additional component.
The alert message template is a CSV formatted line. This lets us simply batch the individual messages through a Firehose Delivery Stream into headerless CSV files that will be stored on S3.
We can then set up a Glue table based on the CSV schema defined in Alertmanager and point it towards the Firehose S3 sink location in order to query the data with Athena using SQL.
All AWS components are created and managed using CloudFormation to facilitate reproducibility. It also enables the version control of the configuration.
Implementation
Alertmanager
To make Alertmanager send alerts to SNS, you simply configure an SNS receiver and route the alerts to it. The receiver configuration contains the target topic ARN, a message subject, a message body, as well as authentication details. The following code snippet shows how you can configure the Alertmanager configuration through a Helm template, provided you manage Alertmanager on Kubernetes through Helm.
receivers:
- name: sns
sns_configs:
- topic_arn: {{ .Values.topicArn }}
subject: |-
{{- $.Files.Get "subject.tmpl" | nindent 14 }}
message: |-
{{- $.Files.Get "message.tmpl" | nindent 14 }}
sigv4:
region: {{ .Values.region }}
access_key: {{ .Values.accessKey }}
secret_key: {{ .Values.secretKey }}
A nice feature about Helm is that you can manage the message and subject templates in separate files. The subject template simply contains the alert name, while the message template defines the schema of the CSV. You can access different variables that are replaced by Alertmanager based on the alert metadata and the available metric labels.
# message.tmpl
{{ range .Alerts -}}
{{ .Labels.alertname }};{{ .Status }};{{ .Labels.env }};...
{{ end }}
Before we can deploy this configuration we need to create the SNS topic and the access credentials. So let’s do that next.
SNS, Firehose, S3
Setting up the ingestion pipeline as CloudFormation YAML is tedious but straightforward. You will need to set up the following resources:
- AWS::SNS::Topic that will receive CSV rows from Alertmanager
- AWS::KinesisFirehose::DeliveryStream that buffers CSV rows into larger batches and writes them to S3
- AWS::S3::Bucket to store the CSV batches. Consider enabling encryption and adding a lifecycle rule to remove old data, and prevent your bill from increasing indefinitely
- AWS::IAM::Role for the delivery stream that allows us to write data to the S3 bucket
- AWS::SNS::Subscription that forwards messages to Firehose
- AWS::IAM::Role for the subscription, including a policy that allows SNS to send messages to Firehose
- AWS::IAM::User with permissions to send messages to SNS together with an AWS::IAM::AccessKey that will be used to authenticate the Alertmanager SNS receiver. Ideally, you store the credentials in an AWS::SecretsManager::Secret.
Once those resources are created, you can pass the credentials and topic ARN to Alertmanager and start ingesting data. Next, let’s look at making the data queryable through Athena.
Athena and Glue
Athena can be used to query files on S3. However, it needs to know how to parse those files, and that’s where Glue comes in. An external Glue table contains all the required information for Athena to successfully parse our CSVs and make them queryable via SQL.
First, we will create an AWS::Glue::Database, which holds a single AWS::Glue::Table. The following CloudFormation snippet contains the definitions for both resources. Let’s walk through it step by step.
AlertDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: Alert DB
AlertTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref AlertDatabase
TableInput:
Name: alerts
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: true
serialization.encoding: utf-8
EXTERNAL: true
projection.enabled: true
projection.datehour.type: date
projection.datehour.range: "2021/02/02/09,NOW"
projection.datehour.format: yyyy/MM/dd/HH
projection.datehour.interval: 1
projection.datehour.interval.unit: HOURS
storage.location.template:
!Join
- ''
- - !Sub s3://${Bucket}/firehose/
- '${datehour}'
StorageDescriptor:
Location: !Sub s3://${Bucket}
InputFormat: "org.apache.hadoop.mapred.TextInputFormat"
OutputFormat: "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
SerdeInfo:
Parameters: { "separatorChar": ";" }
SerializationLibrary: "org.apache.hadoop.hive.serde2.OpenCSVSerde"
Columns:
- Name: labels_alertname
Type: string
- Name: status
Type: string
- Name: labels_env
Type: string
# ...
PartitionKeys:
- Name: datehour
Type: string
Setting up the database is easy. We only specify in which Catalog it should be located, and provide some metadata, such as a description. The table definition is a bit more complex because we need to specify the file format and location.
First, we set the table type to be external, which means that the data is located on S3. The storage descriptor location parameter contains the respective bucket name. We are going to use standard Hadoop/Hive text input and output formats since we are working with CSV files, which are based on text. The serialization/deserialization (SerDe) parameters hold the CSV specific parsing logic.
We are assuming that the data is stored on S3 under the firehose/ prefix, which has to be configured in the Firehose Delivery Stream. Firehose then prefixes each batch with the creation timestamp in hourly resolution. We can utilize the partition projection feature to derive the partition key of the table from that prefix, so we can efficiently query alerts by time range.
After provisioning the database and table, we can finally query the alerts. Let’s take a look in the next section!
Usage
Running queries on Athena through the AWS Console is straightforward. Begin by selecting the alert database in the AWS data catalog and choose the table you created.
Note that if you’re using Athena for the first time, you’ll need to set up a bucket to save the query results. You can use the same bucket that Firehose is using, or create a separate one if you prefer.
The following query can be used to retrieve the number of alerts for each environment from January 20, 2022:
SELECT labels_env, count(*) as count
FROM alerts
WHERE cast(date_parse(datehour,'%Y/%m/%d/%H') as date)
>= cast('2022-01-20' AS date)
GROUP BY labels_env
Depending on the labels you exposed in your CSV schema, you can analyze your alerts at will. You can also query the data through an application rather than the AWS Console if you prefer.
Conclusion
This serverless alerts architecture is an easy and cost-effective solution to query alerts across many Alertmanager instances. The biggest challenge though lies in the fact that any CSV schema changes have to remain backward-compatible, and they have to be kept in sync between all your Alertmanager instances and Glue.
If you can get away with a single Alertmanager instance and analyze alerts based on Alertmanager metrics, that would be a much simpler, albeit less flexible solution. How do you analyze your alerts historically? Do you have to manage multiple Alertmanager instances in your infrastructure? Let us know in the comments!
Resources
- What is AWS CloudFormation?
- Amazon Simple Notification Service
- AWS CloudFormation Documentation
- AWS Glue
- Amazon Kinesis Data Firehose
- Amazon S3
- Amazon Athena
- Prometheus Alertmanager
If you liked this post, you can support me on ko-fi.
Posted on July 17, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.