
Adit Modi
Posted on March 10, 2021
I started my Journey with Big Data in June 2019. I started learning about Big Data through Blogs and Articles . I was really Interested in Learning Hadoop Framework which is needed in order to understand Big Data. I was also Interested in Spark and hadoop .

My Background: Cloud and Big Data Enthusiast | 4x AWS Certified | 3x Oracle Cloud Certifed | 3x Azure Certified | Big Data Certified . I have recently completed 8+ Hadoop & Spark Courses from IBM & achieved badges . I am working from the past one year on AWS Services that make use of Big Data Technologies.
What is Big Data ?
Big Data is also data but with a huge size. Big Data is a term used to describe a collection of data that is huge in volume and yet growing exponentially with time. In short such data is so large and complex that none of the traditional data management tools are able to store it or process it efficiently.
What is big data used for?
Big data has been used in the industry to provide customer insights for transparent and simpler products, by analyzing and predicting customer behavior through data derived from social media, GPS-enabled devices, and CCTV footage. The big data also allows for better customer retention from insurance companies.
what is hadoop in big data ?
Hadoop is an open-source software framework used for storing and processing Big Data in a distributed manner on large clusters of commodity hardware. … Hadoop was developed, based on the paper written by Google on the MapReduce system and it applies concepts of functional programming.
Some Helpful Skill Sets for Learning Hadoop for Beginners
this skills are mandatory but not compulsory for learning.
· Linux Operating System
· Programming Skills
· SQL Knowledge
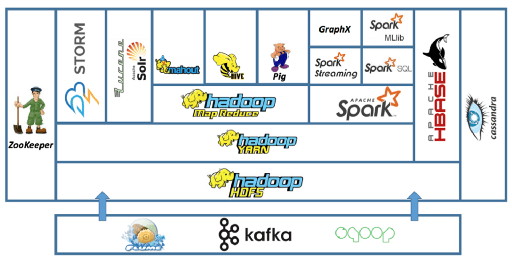
How to start working with Hadoop ?
· Watch Webinars and Documentation available on Internet.
· Get yourself acquainted with the underlying architecture of Hadoop. To do that try to understand how the components like HDFS, MapReduce and Yarn works in the architecture.
· There are a lot of good books available in the market that can help you at all stages. Books like Hadoop — the Definitive Guide works like the bible of Hadoop for the beginners.
· Join a course
· Follow a certification path

what is Spark in Big Data ?
Like Hadoop, Spark is open-source and under the wing of the Apache Software Foundation. Spark is seen by techies in the industry as a more advanced product than Hadoop — it is newer, and designed to work by processing data in chunks “in memory”. Additionally, Spark has proven itself to be highly suited to Machine Learning applications. Unlike Hadoop, Spark does not come with its own file system — instead it can be integrated with many file systems including Hadoop’s HDFS, MongoDB and Amazon’s S3 system.
How to start working with Spark ?
key features of Spark include:
Currently provides APIs in Scala, Java, and Python, with support for other languages (such as R) on the way
Integrates well with the Hadoop ecosystem and data sources (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
Can run on clusters managed by Hadoop YARN or Apache Mesos, and can also run standalone.
Get yourself acquainted with the features of Spark .

Spark Core is the base engine for large-scale parallel and distributed data processing.
SparkSQL is a Spark component that supports querying data either via SQL or via the Hive Query Language. It originated as the Apache Hive port to run on top of Spark (in place of MapReduce) and is now integrated with the Spark stack.
Spark Streaming supports real time processing of streaming data, such as production web server log files (e.g. Apache Flume and HDFS/S3), social media like Twitter, and various messaging queues like Kafka.
MLlib is a machine learning library that provides various algorithms designed to scale out on a cluster for classification, regression, clustering, collaborative filtering and so on.
GraphX is a library for manipulating graphs and performing graph-parallel operations.
you can learn more on the basics of Apache Spark from ( Radek Ostrowski’s Blog ).
Once the Concepts are Clear , to Boost your Concepts Enroll in a Course . Follow the learning path to complete the course and getting practice and hands-on regarding the concepts the course has to offer.

My Experience of learning hadoop framework and Spark Technology has been great . From being a beginner to being a Big Data Geek , the Journey has been amazing . People feel that learning a new technology must be difficult but when you are interested in a Technology like Big Data , you never stop and keep learning and keep improving your skills while developing projects to test your knowledge. I have completed several courses of big data including some offered by Coursera and UCSD and very popular Udemy Course by Frank Kane and practiced big data on AWS for a very long time . I have also achieved IBM badges for passing Hadoop Courses offered by cognitiveclass .
My Suggestion for people starting their journey into Big Data and mainly Hadoop is Start from the basics , know what are the basic terminologies involved in hadoop , Study the Core Concepts preferably with help of a course and once familiar with the concepts and having through Knowledge , practice the Concepts by making small projects to master the basic concepts.
Hope all of you Understood the Big Data Analytics Using Hadoop and Spark and In case of any queries or doubts feel free to reach out to me on LinkedIn.
You can view my badges here.
I also am working on various AWS Services and Developing various AWS and Big Data Projects.
Do Follow me on Github to get Knowledge of Some Big Data Projects Using AWS and Hadoop Framework.
If you liked this content then do clap and share it . Thank You .
To conclude, learning any technology is a journey, not a destination. Hence, you should have persistence and motivation to walk in this challenging world of technology.
Posted on March 10, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.