Text Processing Techniques in NLP

Huynh-Chinh
Posted on February 28, 2022

1. Introduction
Text processing is one of the most common tasks used in machine learning applications such as language translation, sentiment analysis, spam filtering and many others.
Text processing refers only the analysis, manipulation, and generation of text, while natural language processing refers of the ability of a computer to understand human language in a valuable way. Basically, natural language processing is the next step after text processing.
For example, a simple sentiment analysis would require a machine learning model to look for instances of positive or negative sentiment words, which could be provided to the model beforehand. This would be text processing, since the model isn't understanding the words, it's just looking for words that it was programmed to look for.
A natural language processing model would be translating full sentences into another language. Since syntax varies from one language to another, the computer has to understand the meaning of the sentences in order to accurately translate them. But while NLP is more advanced than text processing, it always has text processing invilved as a step in the process.
2. Sentence cleaning
Sentence cleaning or noise removal is one of the first things you should be looking into when it comes to Text Mining and NLP. There are various ways to remove noise. This includes punctuation removal, special character removal, numbers removal, html formatting removal, domain specific keyword removal (e.g 'RT' for retweet), source code removal, header removal and more. It all depends on which domain you are working in and what entails noise for your task.
"""Basic cleaning of texts."""
# remove html markup
text=re.sub("(<.*?>)","",text)
#remove non-ascii and digits
text=re.sub("(\\W|\\d)"," ",text)
#remove whitespace
text=text.strip()
Above are some examples of ways to clean text. There will be different ways depending on the complexity of the data and the type of language.
3. Stop Words
Stop words are a set of commonly used words in a language. Examples of stop words in English are "a", "the", "is", "are" and etc. The intuition behind using stop words is that, by removing low information words from text, we can focus on the important words instead.
For example, in the context of a search system, if your query is "what is text preprocessing?", you want the search system to focus on surfacing documents that talk about text preprocessing over documents that talk about what is. This can be done by preventing all words from your stop word list from being analyzed. Stop words are commonly applied in search systems, text classification applications, topic modeling, topic extraction and others.
stopwords=['this','that','and','a','we','it','to','is','of','up','need']
text="this is a text full of content and we need to clean it up"
words=text.split(" ")
shortlisted_words=[]
#remove stop words
for w in words:
if w not in stopwords:
shortlisted_words.append(w)
else:
shortlisted_words.append("W")
print("original sentence: ",text)
print("sentence with stop words removed: ",' '.join(shortlisted_words))
original sentence: this is a text full of content and we need to clean it up
sentence with stop words removed: W W W text full W content W W W W clean W W
4. Regular Expression
Read more...
5. Tokenization
Read more...
6. N-grams (Unigram, Bigram, Trigram)
Text n-grams are commonly utilized in natural language processing and text mining. It’s essentially a string of words that appear in the same window at the same time.
N-grams is a technique to tokenize a string into substrings, by equally dividing an existing string into equal substrings of length N.
Basically, N is usually from 1~3, with the corresponding names unigram (N=1), bigram(N=2), trigram(N=3).
For a simple example we have the string "good morning", parsed into bigrams:
"good morning" => {"go", "oo", "od", "d ", " m", "mo", "or", "rn", "ni", "in", "ng"}
From the above example, you can easily imagine how N-gram works. To implement N-gram, just a few lines of code as follows, like the example written in python as follows:
def split_ngram(statement, ngram):
result = []
if(len(statement)>=ngram):
for i in xrange(len(statement) - ngram + 1):
result.append(statement[i:i+ngram])
return result
Consider the sentence "I like dancing in the rain" see the Uni-Gram, Bi-Gram, and Tri-Gram cases below.
Uni-Gram: 'I', 'like', 'dancing', 'in', 'the', 'rain'
Bi-Gram: 'I like', 'like dancing', 'dancing in', 'in the', 'the rain'
Tri-Gram: 'I like dancing', 'like dancing in', 'dancing in the', 'in the rain'
Implement N-Grams using Python NLTK
from nltk import ngrams
sentence = 'I like dancing in the rain'
ngram = ngrams(sentence.split(' '), n=2)
for x in ngram:
print(x)
('I', 'like')
('like', 'dancing')
('dancing', 'in')
('in', 'the')
('the', 'rain')
7. Text Normalization
A highly overlooked preprocessing step is text normalization. Text normalization is the process of transforming a text into a canonical (standard) form. For example, the word "gooood" and "gud" can be transformed to "good", its canonical form. Another example is mapping of near identical words such as "stopwords", "stop-words" and "stop words" to just "stopwords".
Text normalization is important for noisy texts such as social media comments, text messages and comments to blog posts where abbreviations, misspellings and use of out-of-vocabulary words (oov) are prevalent.
Here's an example of words before and after normalization:

8. Stemming
Stemming is the process of reducing inflection in words (e.g. troubled, troubles) to their root form (e.g. trouble). The “root” in this case may not be a real root word, but just a canonical form of the original word.
Stemming uses a crude heuristic process that chops off the ends of words in the hope of correctly transforming words into its root form. So the words “trouble”, “troubled” and “troubles” might actually be converted to troublinstead of trouble because the ends were just chopped off (ughh, how crude!).
There are different algorithms for stemming. The most common algorithm, which is also known to be empirically effective for English, is Porters Algorithm. Here is an example of stemming in action with Porter Stemmer:
import nltk
import pandas as pd
from nltk.stem import PorterStemmer
# init stemmer
porter_stemmer=PorterStemmer()
# stem connect variations
words=["connect","connected","connection","connections","connects"]
stemmed_words=[porter_stemmer.stem(word=word) for word in words]
stemdf= pd.DataFrame({'original_word': words,'stemmed_word': stemmed_words})
# stem trouble variations
words=["trouble","troubled","troubles","troublemsome"]
stemmed_words=[porter_stemmer.stem(word=word) for word in words]
stemdf= pd.DataFrame({'original_word': words,'stemmed_word': stemmed_words})

9. Lemmatization
Lemmatization on the surface is very similar to stemming, where the goal is to remove inflections and map a word to its root form. The only difference is that, lemmatization tries to do it the proper way. It doesn't just chop things off, it actually transforms words to the actual root. For example, the word "better" would map to "good". It may use a dictionary such as WordNet for mappings or some special rule-based approaches. Here is an example of lemmatization in action using a WordNet-based approach:
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
# init lemmatizer
lemmatizer = WordNetLemmatizer()
#lemmatize trouble variations
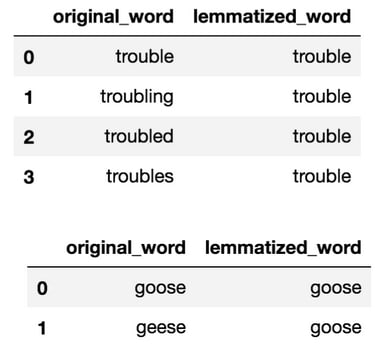
words=["trouble","troubling","troubled","troubles",]
lemmatized_words=[lemmatizer.lemmatize(word=word,pos='v') for word in words]
lemmatizeddf= pd.DataFrame({'original_word': words,'lemmatized_word': lemmatized_words})
lemmatizeddf=lemmatizeddf[['original_word','lemmatized_word']]
#lemmatize goose variations
words=["goose","geese"]
lemmatized_words=[lemmatizer.lemmatize(word=word,pos='n') for word in words]
lemmatizeddf= pd.DataFrame({'original_word': words,'lemmatized_word': lemmatized_words})
lemmatizeddf=lemmatizeddf[['original_word','lemmatized_word']]
Ref:
[1] Text processing: what, why, and how
[2] All you need to know about text preprocessing for NLP and Machine Learning
Conclusion
Thank you very much for taking time to read this. I would really appreciate any comment in the comment section.
Enjoy🎉
Posted on February 28, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related