Map Reduce - Practical Approach

Caleb Adewole Erioluwa
Posted on March 24, 2024

Prerequisite - A little knowledge about message passing, Golang (maybe but not important )
Mic check !!! 0 1 2.
Yeah I started on a funny index 😅, I hoped I could write this sooner but I have been busy with work. Anyway, let's see how good this note will be ... just kidding.
Map + Reduce = Map Reduce. It's funny how something you have used before was scaled into something big and useful. It's a crazy world of engineering similar to the atomic bomb E=mc^2. In a short while you will understand what I mean.
According to wiki, MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. It further describes it as a program composed of a mapping procedure, which performs filtering and sorting and a reduce method, which performs a summary operation.
A MapReduce framework is usually composed of three operations (or steps):
Map: each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed.
Map(k1,v1) → list(k2,v2)Shuffle: worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
Reduce: worker nodes now process each group of output data, per key, in parallel.
Reduce(k2, list (v2)) → list((k3, v3))
A little theoretical background shows that Map operation takes individual values of type A and produces, for each a: A a value b: B.; The Reduce operation requires a binary operation • defined on values of type B; it consists of folding all available b: B to a single value.
From a basic requirements point of view, any MapReduce operation must involve the ability to arbitrarily regroup data being reduced. Such a requirement amounts to two properties of the operation :
associativity: (x • y) • z = x • (y • z)
existence of neutral element e such that e • x = x • e = x for every x:B.
The second property guarantees that, when parallelised over multiple nodes, the nodes that don't have any data to process would have no impact on the result (wiki).
Enough of theory and let's apply the knowledge using a simple example to grasp the concept in a better way. Say we have a list of files with words and we want to know the count of each word in sorted order from all the files. Typically, in a traditional programming way, we will certainly grab the files, read them one after the other and process them i.e count the words using a general map to count the frequency of each word e.g
frequency = {}
files = [ "a.txt","b.txt"]
for file in files:
with open(file) as f:
lines = f.readlines()
for line in lines:
words = lines.split(" ")
for word in words:
if word not in frequency:
frequency[word] = 1
continue
# we are doing map reduce at the same time here
freqency[word]+=1
# reduce happen during addition here
// blah blah bah
Forgive my unoptimised code lol, I want to depict something close to how it will work. Will this work? yes, it will. Can we make it better using the above map reduce model? Sure we can.
There will be two approaches a coupled one using go channels as a mechanism for parallelising our solution and a decoupled one using RPC. In this article, Let's start with the coupled version
Let's create a map function following this pseudocode. Content extracted from files is sent into the map function and the map function generates a list of key-value data
func Map(name string, document string) []mr.KeyValue {
// name: document name
// document: document contents
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
For the next part, Let's create a reduce function that processes each group of output data. The reduced functions differ from each other depending on the program's application
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}
Okay, now that all our important functions have been created ... let's connect the dots (especially the one that makes this framework interesting). Place it in wc.go file
Let's take a step back, Assume we have a coordinator that directs all affairs of our map-reduce activity. Imagine you are in a classroom and your teacher( our coordinator ) decides to give N student documents each to perform a map operation and then tells M students to wait ( not necessarily ) while any result from any of the N students is still processed. Once the result is created from the map function the coordinator forwards it to the reduce function for further action.
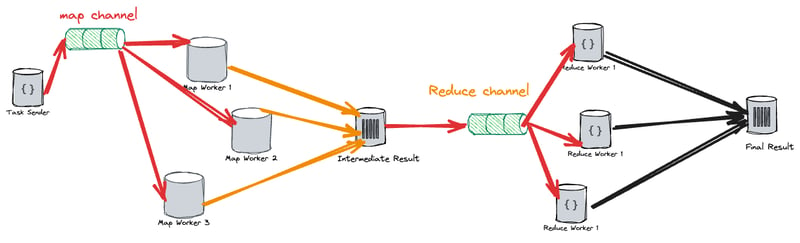
Our setup involves a main.go file which loads in the two functions above from their files
func loadPlugin(filename string) (mr.Mapfn, mr.Reducefn, error) {
p, err := plugin.Open(filename)
if err != nil {
return nil, nil, err
}
xmapfn, err := p.Lookup("Map")
if err != nil {
return nil, nil, fmt.Errorf("cannot look up map function in %s", filename)
}
xreducefn, err := p.Lookup("Reduce")
if err != nil {
return nil, nil, fmt.Errorf("cannot look up reduce function in %s", filename)
}
// assert if the type signature is correct
mapfn, reducefn := xmapfn.(mr.Mapfn), xreducefn.(mr.Reducefn)
return mapfn, reducefn, nil
}
func main() {
pluginFile := flag.String("plugin_file", "./build/fc.so", "name of plugin to run on the application")
filePath := flag.String("file_path", "./pg-dorian_gray.txt", "file path / glob pattern for files")
flag.Parse()
// load function from the passed plugin file
mapfn, reducefn, err := loadPlugin(*pluginFile)
if err != nil {
log.Fatalf("error loading plugin : %v", err)
}
// clean file path
*filePath = filepath.Clean(*filePath)
// extract the directory path
dirName := filepath.Dir(*filePath)
// base filename
baseFp := filepath.Base(*filePath)
workloads := []mr.FileInfo{}
if err := filepath.WalkDir(
dirName,
func(path string, d fs.DirEntry, err error) error {
if err != nil {
return fs.SkipDir
}
matches, err := filepath.Match(baseFp, filepath.Base(path))
if err != nil {
return err
}
log.Printf("Comparing baseFp : %s to path : %s (matches:%v)(regular_file:%v)", baseFp, filepath.Base(path), matches, d.Type().IsRegular())
if d.Type().IsRegular() && matches {
fs, err := os.Open(path)
defer func() {
fs.Close()
}()
if err != nil {
log.Printf("error occured when opening file path : %v", err)
return err
}
contents, err := io.ReadAll(fs)
if err != nil {
log.Printf("error occured when opening file path : %v", err)
return err
}
workloads = append(workloads, mr.FileInfo{
Filename: filepath.Base(path),
Contents: contents,
})
}
return nil
}); err != nil {
log.Fatalf("error retrieve files : %v", err)
}
mw, rw := 2, 2
coordinator := mr.NewCoordinator(mw, rw).
RegisterMapFn(mapfn).
RegisterReduceFn(reducefn).
LoadWorkloads(workloads)
startTime := time.Now()
if err := coordinator.Run(); err != nil {
log.Fatalf("error occurred while running coordinator : %s", err)
}
timeTaken := time.Since(startTime).Milliseconds()
totalByteProcessed := 0
for _, fileinfo := range workloads {
totalByteProcessed += len([]byte(fileinfo.Contents))
}
fmt.Printf("Coordinator Runtime [%dms] {mapWorker:%d,reduceWorker:%d} {TotalFileProcessed:%.1fmb} \n", timeTaken, mw, rw, float64(totalByteProcessed/(1024*1024)))
}
So in this code, we did the following :
We load the function written in the go plugin (This was because I wanted to understand how it works back when I was writing it). Check the comment in the code to know where.
List out all files in the directory we want to process so this parses all the file content Slow right but it works (PS - IO is costly🤗). Load the files into the variable workload so we can pass it as an argument to our coordinator.
The coordinator in this case of this example is like our teacher directing every sequence of our actions. And is defined in a coordinator file as shown below.
type Coordinator struct {
mapWorkers, reduceWorkers int
taskCh chan MTask
mapCh chan []KVPair
reduceCh chan RTask
resultCh chan string
mapfn Mapfn
reducefn Reducefn
workload []FileInfo
wg sync.WaitGroup
m sync.Map
mapResult []KVPair
}
So the coordinator dictates the number of students that will be mapping (as mapWorkers). In this case, the students doing the reduction (a.k.a reduceWorkers). Two channels are created to act as communication mediums for sending and receiving tasks meant for a map operation and reduced operation.
Okay, let's create our coordinator to manage all affairs in a coordinator.go file
func NewCoordinator(numberOfMapWorker int, numberOfReduceWorker int) *Coordinator {
return &Coordinator{
mapWorkers: numberOfMapWorker,
reduceWorkers: numberOfReduceWorker,
taskCh: make(chan MTask, 1),
resultCh: make(chan string),
mapCh: make(chan []KVPair, 1),
reduceCh: make(chan RTask, 1),
workload: make([]FileInfo, 0),
wg: sync.WaitGroup{},
m: sync.Map{},
mapResult: []KVPair{},
}
}
func (c *Coordinator) RegisterMapFn(fn Mapfn) *Coordinator {
c.mapfn = fn
return c
}
func (c *Coordinator) RegisterReduceFn(fn Reducefn) *Coordinator {
c.reducefn = fn
return c
}
func (c *Coordinator) LoadWorkloads(workloads []FileInfo) *Coordinator {
c.workload = workloads
return c
}
func (c *Coordinator) sendOutTaskInformation() {
c.wg.Add(1)
go func() {
defer c.wg.Done()
defer close(c.taskCh) // Close task channel after sending all tasks
for id, fileInfo := range c.workload {
task := MTask{
ID: id,
Payload: fileInfo,
}
log.Printf("Sending task for file: %s\n", fileInfo.Filename)
c.taskCh <- task
}
}()
}
func (c *Coordinator) sendReduceOutputForProcessing(mapWorkersWG *sync.WaitGroup) {
c.wg.Add(1)
go func() {
defer c.wg.Done()
// Use temporary slice to iterate and send reduce tasks
for kvPairs := range c.mapCh {
for _, kvPair := range kvPairs {
fmt.Printf("maps : %s %v\n", kvPair.Key, kvPair.Value)
c.aggregate(kvPair)
}
}
mapWorkersWG.Wait() // Wait for all map workers to complete
c.m.Range(func(k, v any) bool {
ks := k.(string)
vs := v.([]string)
log.Printf("Aggregated result: Key: %s, Values: %v\n", ks, len(vs))
c.reduceCh <- RTask{Key: ks, Value: vs}
return true
})
log.Println("closing c.reduceCh")
close(c.reduceCh)
}()
}
func (c *Coordinator) startMapWorkers(mapWorkersWG *sync.WaitGroup, mapDoneCh chan bool) {
for i := 0; i < c.mapWorkers; i++ {
id := i + 1
c.wg.Add(1)
mapWorkersWG.Add(1)
go func(id int) {
defer c.wg.Done()
defer mapWorkersWG.Done()
for task := range c.taskCh {
log.Printf("Map Worker[%d] -> Received task for file: %s\n", id, task.Payload.Filename)
log.Printf("Map Worker[%d] -> Received task for content: %s\n", id, string(task.Payload.Contents))
mappedResult := c.mapfn(task.Payload.Filename, string(task.Payload.Contents))
if mappedResult != nil {
c.mapCh <- mappedResult
log.Printf("Map Worker[%d] -> Mapped result for file: %s\n", id, task.Payload.Filename)
} else {
log.Printf("Map Worker[%d] -> Error mapping file: %s\n", id, task.Payload.Filename)
}
}
mapDoneCh <- true
log.Println("Done with map worker", id)
}(id)
}
}
func (c *Coordinator) startReduceWorkers(reduceWorkersWG *sync.WaitGroup, reduceDoneCh chan bool) {
for i := 0; i < c.reduceWorkers; i++ {
id := i + 1
c.wg.Add(1)
reduceWorkersWG.Add(1)
go func(id int) {
defer c.wg.Done()
defer reduceWorkersWG.Done()
for val := range c.reduceCh {
log.Printf("Reducer Worker[%d] -> Got %v ", id, val)
c.resultCh <- c.reducefn(val.Key, val.Value)
}
reduceDoneCh <- true
log.Println("Done with reduce worker", id)
}(id)
}
}
func (c *Coordinator) aggregate(v KVPair) {
existingVal, ok := c.m.Load(v.Key)
if ok {
pa := existingVal.([]string)
pa = append(pa, v.Value)
c.m.Store(v.Key, pa)
} else {
c.m.Store(v.Key, []string{v.Value})
}
}
func (c *Coordinator) monitorMapAndReduceWorkers(mapDoneCh, reduceDoneCh <-chan bool) {
c.wg.Add(1)
go func() {
defer c.wg.Done()
for i := c.mapWorkers; i > 0; i-- {
<-mapDoneCh
}
time.Sleep(1000 * time.Millisecond)
log.Println("closing c.mapCh")
close(c.mapCh)
}()
c.wg.Add(1)
go func() {
defer c.wg.Done()
for i := c.reduceWorkers; i > 0; i-- {
<-reduceDoneCh
}
time.Sleep(10 * time.Millisecond)
log.Println("closing c.result")
close(c.resultCh)
}()
}
func (c *Coordinator) Run() error {
var (
mapWorkersWG, reduceWorkersWG sync.WaitGroup
mapDoneCh = make(chan bool, 1) // Signal map completion
reduceDoneCh = make(chan bool, 1) // Signal reduce completion
)
// Assign map workers
c.startMapWorkers(&mapWorkersWG, mapDoneCh)
// Assign reduce workers
c.startReduceWorkers(&reduceWorkersWG, reduceDoneCh)
// Send out task information
c.sendOutTaskInformation()
// Send reduce tasks from temporary slice
c.sendReduceOutputForProcessing(&mapWorkersWG)
c.monitorMapAndReduceWorkers(mapDoneCh, reduceDoneCh)
// Write output to file
oname := "./mr-out-0"
ofile, err := os.Create(oname)
if err != nil {
return err
}
defer ofile.Close()
for result := range c.resultCh {
if _, err := ofile.WriteString(result + "\n"); err != nil {
return err
}
}
log.Println("About to close all jobs")
c.wg.Wait()
log.Println("Done with all jobs")
return nil
}
Long right😱? Yup
Let's break down all our functions in order (it is concurrent but we can still think about it detached )
func (c *Coordinator) sendOutTaskInformation() - This function sends out task information to the map workers. It iterates over the workload stored in the coordinator and sends each task (represented by a MTask struct) to the taskCh channel. Each task contains an ID and payload information (file information). The function closes the taskCh channel after sending all tasks.
func (c Coordinator) startMapWorkers(mapWorkersWG sync.WaitGroup, mapDoneCh chan bool)- This function starts the map workers. It creates a specified number of map workers, each running concurrently. Each map worker listens for tasks from the taskCh channel, performs the map function on the received task's file content, and sends the mapped result to the mapCh channel. After completing its tasks, each map worker sends a signal to the mapDoneCh channel to indicate completion.func (c Coordinator) sendReduceOutputForProcessing(mapWorkersWG sync.WaitGroup)- This function processes the output from map workers for reduction. It receives key-value pairs from the mapCh channel, aggregates them, and sends the aggregated results to the reduceCh channel. Once all map workers are done, it closes the reduceCh channel.func (c Coordinator) startReduceWorkers(reduceWorkersWG sync.WaitGroup, reduceDoneCh chan bool)- This function starts the reduce workers. Similar to this, it creates a specified number of reduce workers, each running concurrently. Each reduce worker listens for aggregated results from the reduceCh channel, applies the reduce function, and sends the result to the resultCh channel. After completing its tasks, each reduce worker sends a signal to the reduceDoneCh channel to indicate completion.func (c *Coordinator) aggregate(v KVPair) - This function aggregates key-value pairs. It takes a key-value pair (
KVPair), checks if the key already exists in the map (c.m), and appends the value to the existing list associated with the key. If the key does not exist, it creates a new entry in the map with the key and a list containing the value.func (c *Coordinator) monitorMapAndReduceWorkers(mapDoneCh, reduceDoneCh <-chan bool)- This function monitors the completion of the map and reduces workers. It waits for signals from mapDoneCh and reduceDoneCh channels to know when all map and reduce workers have completed their tasks. Once all map workers are done, it closes the mapCh channel, and once all reduce workers are done, it closes the resultCh channel.
The functions above give you an explanation of what goes on in the code but to make it a bit clear the prior diagram is doing.
To summarise the code aspect of things the snippet below shows the representation of each user type for the problem. The Run() wait till every create routine is done and then collates the result and writes it to a file.
Although this is not a perfect solution to the framework, It will give you an idea of how the RPC solution works.
type KVPair struct {
Key string
Value string
}
type FileInfo struct {
Filename string
Contents []byte
}
type Mapfn = func(string, string) []KVPair
type Reducefn = func(string, []string) string
type MTask struct {
ID int
Payload FileInfo
}
type RTask struct {
Key string
Value []string
}
One good thing to note is that the map-reduce model does not necessarily go for speed but instead, it exploits the optimised shuffle operation by separating the Map and Reduce phase. In my case, this is the func (c *Coordinator) aggregate(v KVPair) method.
To better understand this article take a look at the following resource:
-

The next article will properly explain how a more practical version of this model can be implemented using RPC. Hopefully, you can check it out 🤗.
Bye for now :).
Posted on March 24, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related