Towards Operational Excellence — Part 2

Adrian Hornsby
Posted on March 10, 2020

On the importance of tools

Once again, I’d like to express my gratitude to Peter Vosshall, Distinguished Engineer at AWS, for the inspiration behind this series of posts. I’d also like to thank my colleagues and friends Chris Munns, Matt Fitzgerald and Aileen Gemma Smith for their valuable feedback.

As discussed in Part 1 on culture, it takes three interconnecting elements to operate the technology we build successfully. First, you need to have the right culture. Second, you need great tools. And third, you need complete processes.
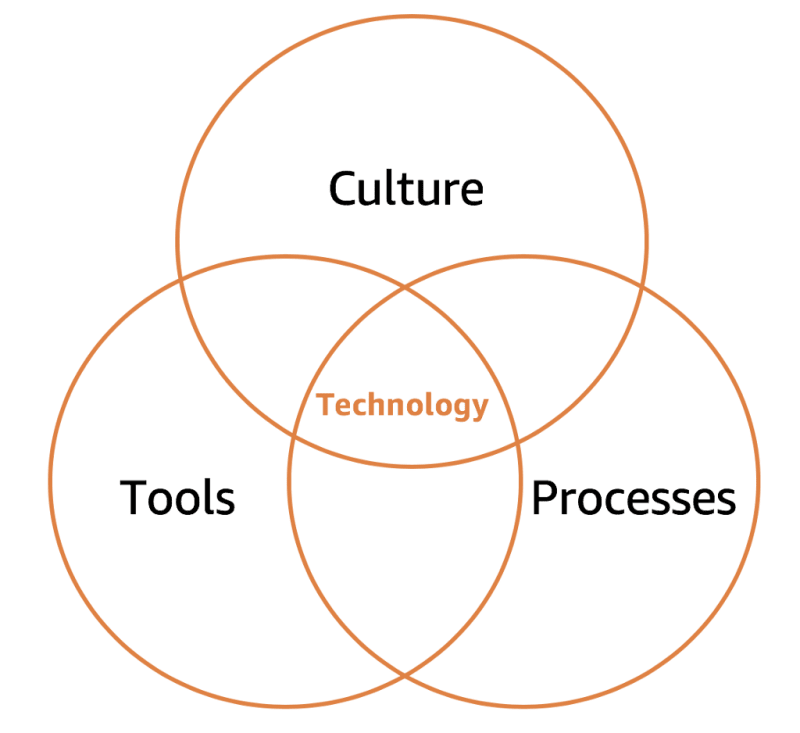
Part 1 of the series covered the cultural side of OE and examined Amazon’s culture in the context of its Leadership Principles (LPs). These LPs are the DNA of the company and the guiding principles by which every Amazonian operates. In Part 2, I discuss the tools but will continue to use LPs as the supporting framework to understand the motives and decisions made. Part 3 will cover processes.
Let’s get to it!
A bit of history
There are, of course, a broad set of tools needed to operate the cloud. The essential categories are listed here:
Test Automation
Configuration Management
Software Deployment
Monitoring and Visualization
Reporting
Change Management
Incident Management
Trouble Ticketing
Security Auditing
Forecasting and Planning
To understand the importance of tools, let’s dive into Software Deployment and how it has impacted and shaped Amazon.
In the early days, the systems running the amazon.com bookstore were relatively simple, incorporating a three-tier architecture with a front-page, a web server, a database, and few internal tools.

When you’re working with a monolithic application, developers are pushing changes through a shared release pipeline that can cause friction.
First, all the different teams need to coordinate changes to avoid breaking someone else’s code. Upgrading libraries for security or performance purposes requires the blessing and support of everyone since everyone will have to upgrade at the same time. Quick fixes and patches need similar approval. That leads to freeze-merge Fridays, or worse, freeze-merge weeks.
After a feature development, you’re faced with a tough question : How do you push these changes through the delivery pipeline?
Everything is shared, so you need to re-build the whole application, run entire test suites, and re-deploy all of the components.
Even a one-liner or a tiny change in the code needs to go through this process. This expensive “one-liner change process” is the reason deployment teams have “fast deploy” processes, which include bypassing the quality control part of the pipeline and adding even more risks and potential for failures.
Amazon had a central, dedicated team known as “ Houston ” whose sole job was to deploy this monolithic website application into production using a Perl script running “ website-push.”
Calling Houston
The name Houston relates to the fact that deployments were risky back then.
“The application is deployed!”
would often be followed by:
“Houston, we have a problem.”
Building Goliath
The second phase of the deployment was to copy new builds of command-line tools to a centralized NFS server. That was pretty convenient until the NFS server failed and took down the whole operation.
The command-line tools ranged from server administration to customer services. Below is a command used by customer service operators who wanted to issue a refund for customers.
/opt/amazon/customer-service/bin/request-refund
Since the same database was used by the bookstore, customer service tools, and fulfillment center tools, customer service operators had to log into the servers and run Unix commands.
Considering that in my previous life I dropped production databases using similar scripts, I find that pretty rad, yet a bit risky. But I digress :-)
As you can imagine, deploying that “monolith” wasn’t always as smooth as silk. For a fast-growing company like Amazon — trying to innovate and compete for happy customers — this was unacceptable.
The organization made a couple of essential changes: one was architectural and the other was organizational.
Breaking the monolith
First, the monolith was broken apart into a service-oriented architecture (SOA) — what we today call micro-service architecture.

A few strict requirements had to be taken into account during this refactoring: Services created had to be (1) small, (2) focused, (3) single-purpose, and (4) connected via an HTTP API.
To give you an idea of such decomposition, the “ Buy Now ” button on the amazon.com retail page is such a service.
This cleavage created a highly decoupled architecture, with services defined by a standard HTTP API. As long as that API remained stable, the team operating the service could iterate faster, without worrying about breaking everyone’s else.
Conway’s law
The Conway’s law was named after Melvin Conway, who introduced it in 1967.
“Organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.”
— M. Conway
The law tells us that for software to be developed and function properly, developers must communicate frequently with each other. Thus, the software interface structure of systems is often a mirror of the organization that releases it.

After tearing down the monolith, Amazon tore down the organization. The top-down hierarchical organization was broken up into small teams — small enough to be fed by two pizzas. When these “two-pizza teams” grew beyond 8–12 people, they were broken up and refocused.
The two-pizza teams were given full autonomy: working with internal and external customers, setting their roadmap, agreeing service specifications, writing code, running tests, deploying to production, and even operations.

These two changes made things go more smoothly. Teams were developing features faster than ever. However, things weren’t great quite yet.
What do you do when things aren’t great?
You measure. You collect data. You listen to anecdotes.
“I never guess. It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.”
Sir Arthur Conan Doyle.
Two LPs are, in my opinion, essential to developing a mindset of collecting data and understanding it before starting any work:
Dive Deep
Leaders operate at all levels, stay connected to the details, audit frequently, and are skeptical when metrics and anecdotes differ. No task is beneath them.
Insist on the Highest Standards
Leaders have relentlessly high standards — many people may think these standards are unreasonably high. Leaders are continually raising the bar and drive their teams to deliver high-quality products, services, and processes. Leaders ensure that defects do not get sent down the line and that problems are fixed, so they stay fixed.
These cultural traits led Amazon to measure its software development process. It discovered it was taking an average of 16 days from code check-in to being deployed to production. It also found that operations personnel carried out significant manual work, including emails and tickets. In other words, people spent most of their time waiting.

That was the problem to be solved: automating the production line to avoid developers waiting.
This is also where you start to realize that Culture and Tools go hand-in-hand. Without diving deep on the problems, without wanting to raise the bar, the next transformation would most certainly not have happened, and Amazon wouldn’t be where it is today.

Brazil, Apollo, and Pipeline
To avoid developers wasting time running build commands, Amazon created a centralized, hosted build system called Brazil. The main functions of Brazil are compiling, versioning, and dependency management, with a focus on build reproducibility. Brazil executes a series of commands to generate artifacts that can be stored and then deployed. To deploy these artifacts, Apollo was created.
Apollo was developed to reliably deploy a specified set of software artifacts across a fleet of instances. Developers define the process for a single host and Apollo coordinates that update across the entire fleet of hosts.
It was a big deal! Developers could simply push-deploy their application to development, staging, and production environment. No login into the host, no command to run. These automated deployments removed the bottleneck and enabled teams to innovate and deliver new features for customers rapidly.
The extensive use of Apollo by Amazon teams has driven the development of new features, and today Apollo can do plenty more — for example, it can perform a rolling-update with health-checking that allows an application to remain available during an upgrade. It can also deploy simultaneously to many hosts in different locations in case a fleet is distributed across separate data centers. That feature ensures the application remains balanced during deployment and redundant in case of failure in one location. Apollo does all of this while keeping track of the deployment status of each host, and it uses that information to withstand potential problems during deployments.
It is worth noting that Apollo uses a pre-baked custom Amazon Linux Instance (AMI) as the foundation for deployments. That custom AMI represents a standard OS environment with prerequisites baked in, making it easier to standardize deployments.
If you want to learn more about Apollo, please read Werner Vogels’ blog post here.
However, automated deployments can’t solve everything. Deployments are, in fact, part of a bigger picture. They’re part of a workflow that starts the instant a developer commits code to the repository and ends when that change is successfully running in production.
Pipeline s models that workflow, and the path that code takes from check-in to production. Pipelines is a continuous deployment system that allows developers to create a fully automated deployment — from the moment code is checked-in and passes its tests — to production, without manual intervention.
Of course, not everything can be fully automated. Still, Pipelines will automate the steps the team is comfortable with, and most importantly, codify the steps required between checking-in code to having it running in production.
Pipelines is also where the verification steps happen, whether it’s testing, compliance verification, security reviews, auditing, or explicit approvals.

A pipeline consists of any number of stages. The example above starts by building packages into version sets, then flows into Gamma stage, then one-box production stage, and finally, full production stage. Each arrow is a promotion step that serves as a validation gate before the release goes to the next stage.
Pipelines started as a pilot program for a small number of teams. By the end of the pilot, one of them had achieved a 90 percent reduction in the time it took to go from check-in to production. Yes, a 90 percent reduction!
As other Amazon teams saw the success of the team that piloted Pipeline, they naturally started to migrate their release processes into pipelines. Teams that had custom-made release processes converged to a standardized method used by everyone.
Furthermore, the migration to Pipeline allowed teams to find new ways to simplify the whole delivery process.
Finally, it is worth mentioning that the above tooling chain is tightly integrated with a common logging and monitoring system.
Driving consistency, standardization, and simplification
Brazil, Apollo, and Pipeline brought a lot of goodness to Amazon and our customers. It also brought a lot of software changes, and by 2019 Amazon was pushing hundreds of million deployments a year.
More importantly, while speeding the software delivery, the broad adoption of these tools reduced the risk of deployment failures as these tools drove consistency, standardization, and simplification of the release processes. Indeed, the development of these tools resulted in fewer defects being launched into production — and happier customers. That’s the essence of OE.
“[…] the broad adoption of these tools […] ”
The above statement is critical since, without the broad adoption of Brazil, Apollo, and Pipelines, none of this would have happened.
How do you enable the broad adoption of tools within your organization to drive consistency, standardization, and the simplification of processes?
Without spoiling Part 3 of this series, it’s all about complete processes — or what Amazon likes to call functional mechanisms.
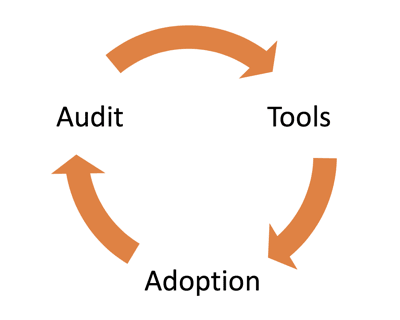
A mechanism is made up of three steps: tools, adoption, and auditing. Indeed, a tool is useless if you don’t have a training program and a way to drive adoption of it.
At Amazon, we have several ways to promote knowledge transfer and to train people to encourage the adoption of tools and other practices. A couple are very important:
First, we have numerous training and boot camps that anyone can enroll in. Depending on the role, some are compulsory, some voluntary. Compulsory sessions appear automatically in a so-called learning path, which is a standardized way to ramp up roles.
Second, we have an internal repository of videos, white papers, courses and wiki articles covering a variety of topics — from architectural patterns and cultural guidance to coding best practices.
“Knowledge, like air, is vital to life. Like air, no one should be denied it.” ―Alan Moore
Take-away
First, you have to consistently raise the bar and drive teams to deliver higher quality products, services, and processes.
To do so, you have to dive deep into your data and understand the problems you’re dealing with. Start by measuring your overall delivery process.
Do you know how long it takes between the first code commit to deployment in production? Do you know the number of defects that pass through your delivery pipeline? Do you know the number of security threats that go undetected?
(1) One of the most important things an organization can do is to nurture a culture of measuring everything. Without measurement, you operate in the dark, via assumptions.

Measuring allows you to get insights into what is missing in your organization — and to drive the development of tools required for improvements.
(2) To ensure the tools built are the right ones, pilot them with a few teams first, and iterate with them until the success stories are so good that they naturally infect other groups. Social pressure is a beautiful thing :-)
And, keep measuring. Don’t settle for “good enough.” You are, at this moment, setting a new flywheel in motion for the benefit of your customers.
(3) Having the same standardized tooling chain across the organization is key. While sometimes disliked by developers, the standardization of tools often drives consistency and simplification. And an improvement made to any tool immediately benefits everyone.
(4) To benefit the whole organization, make sure you continuously train your people and promote knowledge transfer.
Finally, if your delivery pipeline needs improvement, Brazil, Apollo and Pipeline have inspired the development of the AWS Code* suite of developer tools. You can use tools such as AWS CodeCommit, AWS CodeBuild, AWS CodeDeploy, AWS CodePipeline, and AWS CodeStar today in your organization.
These tools are designed to help you build applications like Amazon. They facilitate practices such as continuous delivery and infrastructure as code and will help you accelerate your software development and release cycle.
Wrapping up
That’s all for Part 2, folks. Please don’t hesitate to share your feedback and opinions. In the next post, I’ll discuss the a crucial part of Operational Excellence: complete processes.
-Adrian
Posted on March 10, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



